
Difyのイテレーション(反復処理)とは?繰り返し処理の仕組みを徹底解説
 室谷
室谷今回はDifyのイテレーションについて話しましょう。これ、.AI(ドットエーアイ)コミュニティでも「使い方がよくわからない」という声が多いんですよね。
概念は簡単なのに、いざ設定しようとするとハマる・・・
概念は簡単なのに、いざ設定しようとするとハマる・・・
 テキトー教師
テキトー教師講座でも毎回質問が出るトピックです。「配列って何ですか?」から始まって「出力をどう受け取ればいいですか?」まで、段階的につまずきポイントがあるんですよね。
今回はそこを丁寧に解説していきましょう。
今回はそこを丁寧に解説していきましょう。
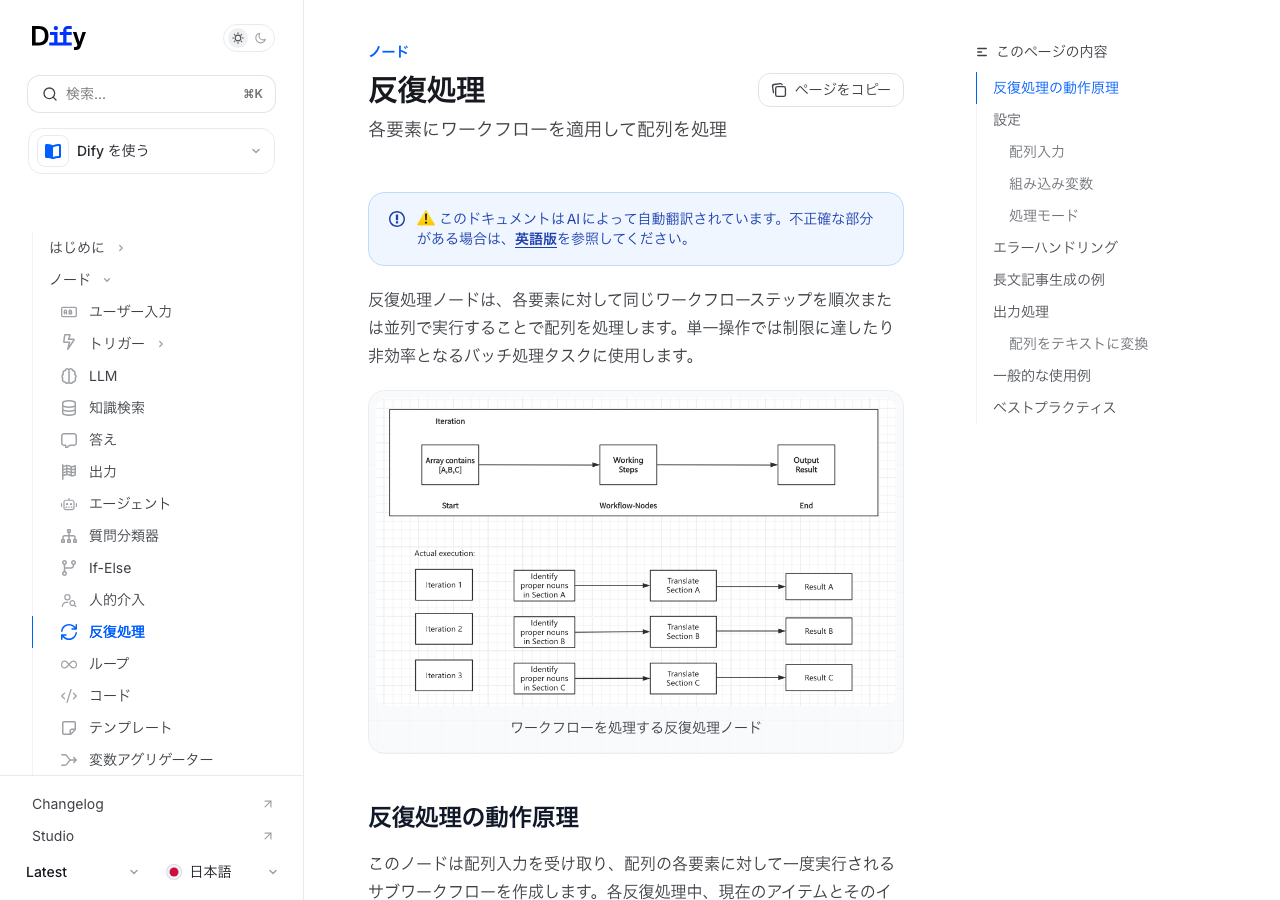
室谷イテレーション、日本語だと「反復処理」ですね。Difyの公式ドキュメントでは「各要素にワークフローを適用して配列を処理する」と説明されています。
要するに、リストになっているデータに対して、同じ処理を繰り返し実行するノードです。
要するに、リストになっているデータに対して、同じ処理を繰り返し実行するノードです。
テキトー教師プログラミングで言うと「forループ」に相当します。ただ、Difyのイテレーションはノードをつなぐだけで実装できるので、コードを一行も書かずにループ処理が組めるんですよ。
これが非エンジニアにとっての強みですよね。
これが非エンジニアにとっての強みですよね。
室谷そうそう。たとえば10件の顧客名リストがあって、それぞれに対してLLMで返信メールのドラフトを生成したい、みたいな場合に使います。
一件ずつ手動で実行する代わりに、イテレーションに配列を渡せば10件まとめて自動処理してくれる。
一件ずつ手動で実行する代わりに、イテレーションに配列を渡せば10件まとめて自動処理してくれる。
テキトー教師整理すると、こういう構造です。
- 入力: 配列(Array)データ
- 処理: 配列の各要素に対してサブワークフローを実行
- 出力: 処理結果を集めた新しい配列
室谷この「入力が配列、出力も配列」というのが肝で、最初にここを理解していないと後でハマります。
テキトー教師ですよね。受講生さんが一番ハマるのが「出力をどうやってテキストにするか」という点です。
イテレーションの出力は配列なので、そのままでは終了ノードに渡せないんですよ。後で詳しく触れましょう。
イテレーションの出力は配列なので、そのままでは終了ノードに渡せないんですよ。後で詳しく触れましょう。
ループノードとイテレーションの違い
室谷ここで一つ重要なポイントがあって、Difyには「ループ」と「イテレーション」という似た名前のノードが両方あるんですよね。これ、混同している人が多い・・・
テキトー教師これ、本当によく聞かれます(笑)。整理すると、目的が全然違うんですよ。
| ノード | 目的 | 特徴 |
|---|---|---|
| イテレーション | 配列の各要素を処理 | 入力は配列、出力も配列 |
| ループ | 条件が満たされるまで繰り返す | 前の結果を次のサイクルに引き継ぐ |
室谷イテレーションは「同じ処理を複数のデータに適用する」もので、ループは「品質基準を満たすまで同じデータを改善し続ける」ものですね。用途が明確に違います。
テキトー教師具体例で言うと、「100件の商品説明文をそれぞれLLMで要約したい」→ イテレーション。「詩の品質が基準を超えるまで何度も改稿させたい」→ ループです。
室谷MYUUUでも両方使いますが、ビジネスで圧倒的に出番が多いのはイテレーションです。バッチ処理系の自動化はほぼイテレーションで組んでいます。
Difyイテレーションの設定方法:配列入力から出力変数まで
テキトー教師では実際の設定方法に入りましょう。まず大前提として、イテレーションノードへの入力は必ず「配列(Array)」である必要があります。
ここを理解していないと設定の段階でつまずきます。
ここを理解していないと設定の段階でつまずきます。
室谷配列って、要はリストですよね。
Difyだと
["りんご", "みかん", "ぶどう"] みたいな形式。Difyだと
Array[String] や Array[Object] といった型で扱います。テキトー教師そうです。この配列をどこから持ってくるかがポイントで、主に4つの方法があります。
- パラメータ抽出ノードで文字列から配列を生成する
- コードノード(Python/JavaScript)で配列を組み立てる
- 知識検索の結果を配列として受け取る
- HTTPリクエストのレスポンスから配列を取得する
室谷実務でよく使うのはコードノードとパラメータ抽出の組み合わせですね。固定フォーマットならコードノードの方が速いし、LLMで柔軟に抽出したいときはパラメータ抽出を使います。
組み込み変数:itemとindex
テキトー教師イテレーションの中では、2つの組み込み変数が使えます。これが便利で。
items[object]- 現在処理中の配列要素(現在のアイテム)index[number]- 現在のインデックス番号(0から始まる)
室谷この
items を、イテレーション内のLLMノードや変数アサイナーで参照する、というのが基本パターンです。たとえばLLMのシステムプロンプトに {{items}} と書けば、配列の各要素が順番に渡されます。テキトー教師index は「何番目の処理か」を把握したいときに使います。ログ出力や進捗管理に便利ですね。ちなみに0から始まるので、1件目が
index=0、2件目が index=1 になります。室谷ここで一つ注意点があって、イテレーション内の処理が完了したら、必ず出力変数を設定してください。出力変数を定義せずに実行するとエラーが出ます。
これ、地味にハマりポイントです。
これ、地味にハマりポイントです。
テキトー教師受講生さんもここで詰まる人が多いんですよ(笑)。イテレーション内のノードの出力を設定パネルから指定する必要があります。
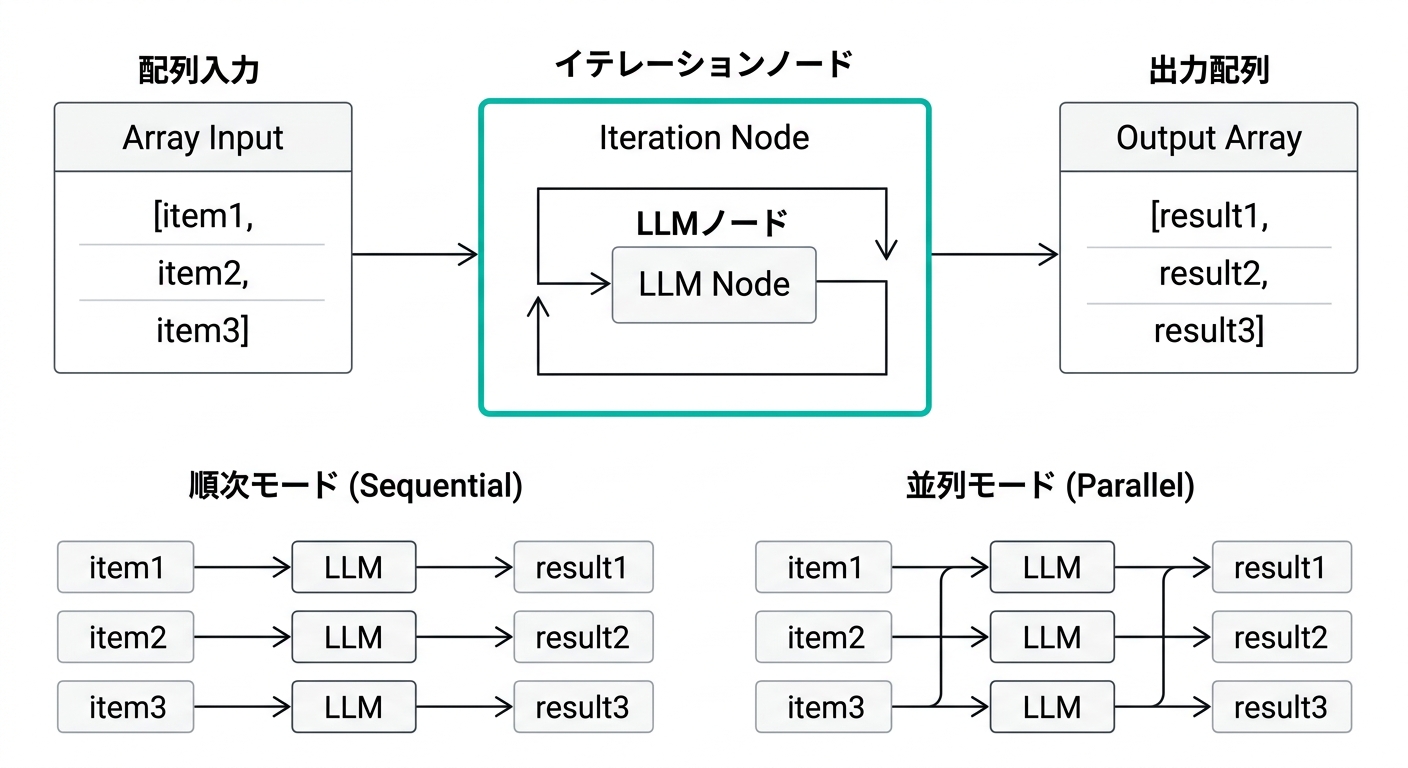
順次モードと並列モード
室谷処理モードが2種類あって、これが重要です。順次モードと並列モードですね。
テキトー教師整理するとこうです。
| モード | 動作 | 向いている場面 |
|---|---|---|
| 順次モード | アイテムを1件ずつ順番に処理 | 順序が大事な処理、ストリーミング出力を使う場合 |
| 並列モード | 複数アイテムを同時に処理 | 速度重視、各アイテムが独立している処理 |
室谷並列モードを使うと処理が速くなりますが、API のレート制限に引っかかることがあるので注意が必要です。特にOpenAIやAnthropicのAPIを使っているときは、並列数を絞った方が安全です。
テキトー教師Qiitaに実践的な記事を書いてくれている方もいて、「パラレルモード使用時においてLLM向けのAPIスロットル制限が出ることがある。その場合は最大並列処理を減らして調整してください」という点も指摘されていますよ。
室谷ストリーミング出力が必要な場合は順次モード一択です。並列モードだと回答ノードでの段階的な出力ができないので。
Difyイテレーションの使い方:5ステップでワークフローを構築
室谷実際にどう組み立てるかを見ていきましょう。基本的なイテレーションワークフローの構築手順です。
テキトー教師シンプルな例として「複数のテキストを1件ずつLLMに送って処理する」ワークフローを考えます。これが最も基本的なパターンです。
Step 1. 配列を用意する(コードノードまたはパラメータ抽出)
室谷まず、イテレーションに渡す配列を作ります。シンプルに固定リストを使う場合はコードノードが便利です。
def main(text1: str, text2: str, text3: str) -> dict:
result = [text1, text2, text3]
return {
"result": result, # Array[String] として返す
}
重要なのが、コードノードの出力変数の型を
Array[String] に設定すること。これを忘れると、イテレーションノードで入力を受け取れないんですよ。室谷パラメータ抽出ノードを使う場合は、抽出するパラメータの型を
Array[String] に設定して、LLMに「入力テキストを各要素が個別アイテムになるよう配列に変換してください」と指示します。Step 2. イテレーションノードを追加して配列を接続
テキトー教師ノードの「+」ボタンから「反復処理」を選択して追加します。入力変数に先ほどのコードノードの出力配列を接続します。
室谷設定パネルで入力変数を選択するときに、型が
Array[Object] や Array[String] になっているものだけが選択できます。ここでも型の確認が大事です。Step 3. イテレーション内にLLMノードを配置
テキトー教師イテレーション内部に LLM ノードを追加して、プロンプトで
{{items}} を参照します。こうすると、配列の各要素が順番に LLM に渡されます。室谷LLMノードの入力変数として
items を設定して、システムプロンプトで使います。たとえばこういう感じですね。あなたは優秀な編集者です。
以下のテキストを100文字以内に要約してください。
テキスト: {{items}}
この
{{items}} の部分が、配列の各要素に自動的に置き換わるわけです。1件目の処理では1件目のテキスト、2件目では2件目のテキストが入ります。Step 4. 出力変数を設定する
室谷イテレーション内の処理が決まったら、出力変数を設定します。LLMノードの出力(例:
text)をイテレーションの出力変数として指定します。テキトー教師ここを忘れると実行時エラーが出るので、設定パネルの「OUTPUT VARIABLES」で必ず指定してください。これ、本当によく忘れるんですよね(笑)。
Step 5. 出力配列をテキストに変換する
室谷イテレーションの出力は配列なので、終了ノードに渡す前にテキストに変換する必要があります。コードノードかテンプレートノードで処理します。
テキトー教師コードノードを使う場合はこうです。
def main(sections: list) -> dict:
return {
"result": "\n\n".join(sections)
}
テンプレートノードの場合はJinja2の構文が使えます。
{% for item in arg1 %}
{{ loop.index }}. {{ item }}
{% endfor %}
どちらを使うかはケースバイケースですが、シンプルな連結ならコードノード、フォーマットを整えたいならテンプレートノードが使いやすいですね。
Difyイテレーションのエラーハンドリング:上限・失敗時の挙動を制御する
室谷実運用で重要になるのがエラーハンドリングです。配列の途中で1件失敗したとき、全体を止めるのか、その件をスキップして続けるのかを選べるんですよね。
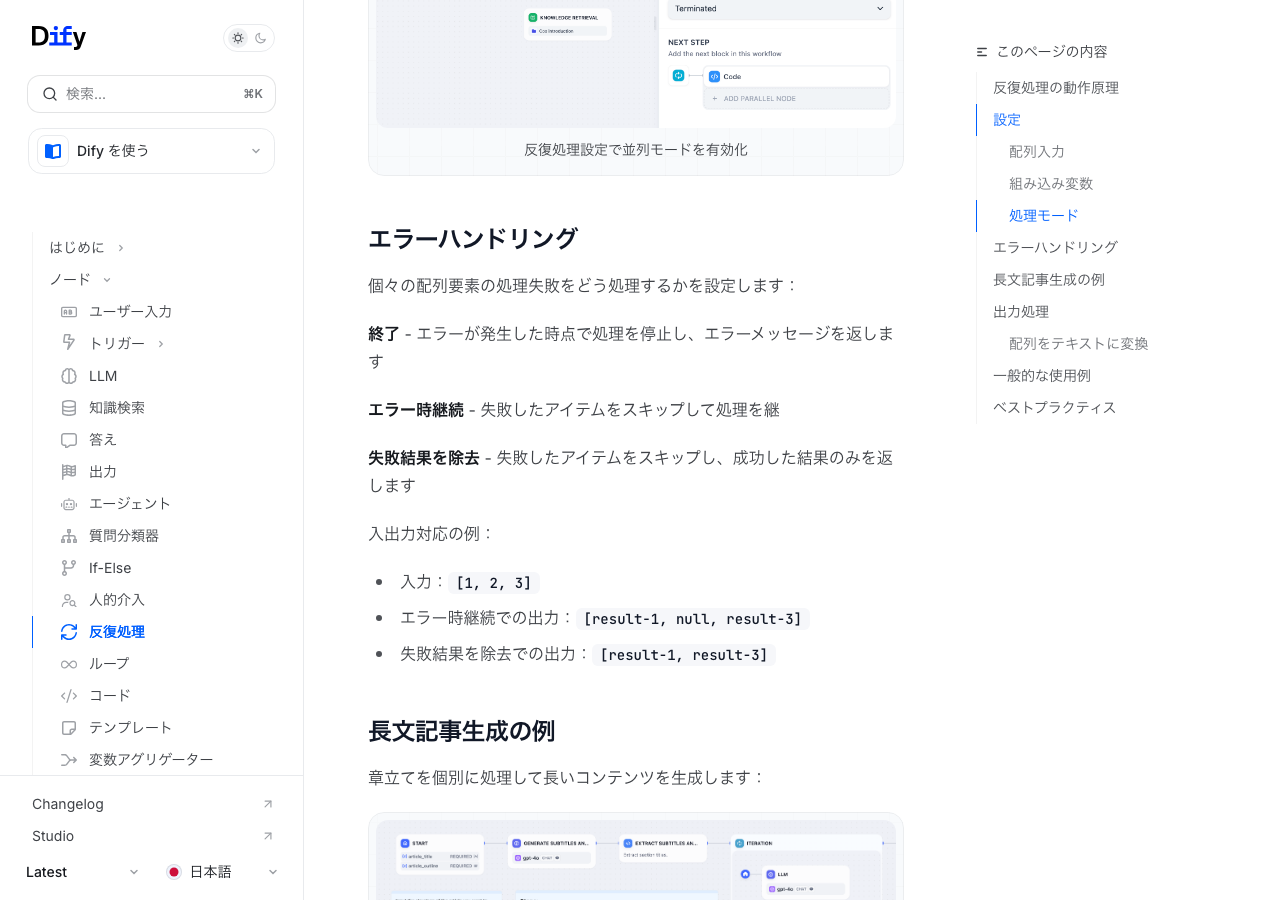
テキトー教師設定できるエラー処理が3種類あります。
- 終了(Terminate): エラーが発生した時点で処理全体を停止する
- エラー時継続(Continue on Error): 失敗したアイテムをスキップして処理を続ける。失敗した箇所はnullになる
- 失敗結果を除去(Remove Failed Results): 失敗したアイテムをスキップして、成功したものだけを出力配列に含める
室谷これ、実務では「エラー時継続」か「失敗結果を除去」を選ぶことが多いですね。100件のバッチ処理で1件失敗したからといって全部やり直すのはコストが高すぎますから。
テキトー教師ビジネス用途では「失敗結果を除去」が使いやすいと思います。成功したものだけが出力されるので、後続の処理で null チェックが不要になります。
室谷公式ドキュメントの例がわかりやすくて、入力が
[1, 2, 3] でアイテム2だけ失敗した場合、「エラー時継続」だと [result-1, null, result-3]、「失敗結果を除去」だと [result-1, result-3] になります。イテレーション回数の上限
テキトー教師もう一つ、イテレーション回数の上限についても確認が必要です。Difyのイテレーションには処理回数の制限があります。
室谷バージョンによりますが、1回のイテレーションで処理できる件数には上限があります。Difyの公式GitHubでも「30件を超えるとどうなるか」という議論が出ているくらい、よく引っかかるポイントです。
大量データを処理したい場合は、あらかじめ配列を分割するか、ループノードと組み合わせて複数回に分けて処理する設計が必要です。
大量データを処理したい場合は、あらかじめ配列を分割するか、ループノードと組み合わせて複数回に分けて処理する設計が必要です。
テキトー教師受講生さんから「数十件のデータを処理したら途中で止まった」という相談がよくあって、上限に引っかかっていることが多いです。大量データを扱うときは分割を前提に設計しておくのが安全ですね。
Difyイテレーション活用例:CSV・JSON・ファイルのバッチ処理
室谷実際にどんなシーンで使うか、具体的な活用パターンを見ていきましょう。
テキトー教師大きく分けると、入力データの形式によってパターンが変わります。
CSVデータをイテレーションで処理する
室谷CSVのイテレーション活用で一番多いのが、顧客リストを読み込んで1件ずつ処理するパターンです。MYUUUでも実際にやっています。
テキトー教師フローとしてはこうなります。HTTPリクエストノードでCSVを取得 → コードノードでCSVをパースして配列に変換 → イテレーションで各行を処理 → 結果を集約。
室谷Pythonで書くとCSVのパースはこんな感じです。
import csv
import io
def main(csv_text: str) -> dict:
reader = csv.DictReader(io.StringIO(csv_text))
rows = [dict(row) for row in reader]
return {"result": rows} # Array[Object] として返す
この場合、出力は
Array[Object] になります。イテレーション内では {{items.name}} や {{items.email}} のように、オブジェクトのフィールドにアクセスできます。JSONデータのイテレーション
室谷APIのレスポンスをイテレーションで処理するパターンも多いですね。たとえばHTTPリクエストノードで取得したJSON配列をそのままイテレーションに渡すことができます。
テキトー教師HTTPリクエストのレスポンスが
{"items": [...]} という形式であれば、変数として response.items を参照してイテレーションに接続できます。これが一番シンプルなパターンです。室谷ただ、JSONの構造によってはコードノードで整形する必要が出てくることも。レスポンスが配列でない場合や、必要なフィールドだけを抽出したい場合は、コードノードを挟むのがベストプラクティスです。
複数ファイルをイテレーションで処理する
テキトー教師複数ファイルのバッチ処理も、Difyのイテレーションの強みですね。ドキュメントエクストラクターと組み合わせると、複数のPDFを一括で処理できます。
室谷たとえば10本の契約書PDFから特定の情報を抽出したいとき、配列にPDFのリストを入れてイテレーションに渡し、内部でドキュメントエクストラクター → LLM(抽出プロンプト)を実行する形です。これ、人手でやったら何時間もかかる作業が数分で終わります。
テキトー教師ちなみに並列モードを使うとさらに速くなりますが、ファイルサイズが大きい場合はメモリ使用量に注意が必要です。大量の大きなファイルを並列処理すると負荷が高くなるので、適切な並列数に設定しましょう。
Difyイテレーションで長文記事を自動生成する実践例
室谷公式ドキュメントにも紹介されている、もっとも実践的なユースケースが「長文記事の章立て生成」です。これ、.AIコミュニティのメンバーがやって日本経済新聞さんに取材されたやつとも関連しているんですよね。
テキトー教師フローを説明しましょう。まず開始ノードでユーザーが記事のタイトルとアウトラインを入力します。
次にLLMノードで詳細な章立てを生成します。パラメータ抽出ノードで章のリストを配列化して、イテレーションで各章を1つずつLLMに書かせます。
最後にコードノードかテンプレートノードで全章を結合して完成です。
次にLLMノードで詳細な章立てを生成します。パラメータ抽出ノードで章のリストを配列化して、イテレーションで各章を1つずつLLMに書かせます。
最後にコードノードかテンプレートノードで全章を結合して完成です。
室谷この構造の何が賢いかというと、LLMのコンテキストウィンドウの制限を回避できることです。1万字以上の記事を一度に生成しようとすると品質が下がりますが、章ごとに分けて生成すれば各章で高品質なアウトプットが得られます。
テキトー教師そうそう。「最大トークン数管理」という観点でイテレーションを使うのは、上級者がよくやるパターンです。
1つのLLM呼び出しでは難しいタスクでも、分割してイテレーションすることで対応できます。
1つのLLM呼び出しでは難しいタスクでも、分割してイテレーションすることで対応できます。
室谷あと、回答ノードをイテレーション内に配置すると、章ができあがるごとにストリーミングで表示できるんですよ。これが地味に体験が良くて・・・全部完成するまで待つのではなく、書き上がった章から順番に表示されるので、ユーザーから見てレスポンスが速く感じる。
テキトー教師ストリーミングが使えるのは順次モードだけなので、この場合は順次モードを選択してください。
Difyオーケストレーションとイテレーションの組み合わせ
テキトー教師少し応用的な話をしましょう。Difyのオーケストレーション機能とイテレーションを組み合わせると、複雑なワークフローが組めます。
室谷「Dify オーケストレーション」というのは、複数のAIアプリやワークフローを連携させる仕組みのことですよね。エージェントオーケストレーションとも言います。
テキトー教師イテレーションをオーケストレーションに組み込むパターンで面白いのが、各イテレーションのアイテムに対してサブフローを呼び出す構成です。複雑な処理を外部ワークフローに分離できるので、保守性が上がります。
室谷MYUUUでもそういう設計をしているプロジェクトがあって、メインフローはシンプルに保って、処理の詳細はサブフローに任せるパターンです。これだと処理ロジックを変えたいときにサブフローだけ修正すればいいので管理が楽になります。
テキトー教師あと、ネスト(入れ子)のイテレーション、つまりイテレーションの中にイテレーションを入れることも理論上は可能ですが、複雑になりすぎるので初心者にはおすすめしません。まずはシンプルな1階層で使いこなすことを優先しましょう。
室谷ネストに関しては「dify イテレーション ネスト」で検索している人も多いようなんですが、よほど特殊なケースでない限り、フラットな設計で解決できることがほとんどです。
Difyイテレーション使い方まとめ:よくあるエラーとその対処法
テキトー教師最後に、よくあるエラーとその対処法を整理しておきましょう。
室谷これは本当に役に立つ情報ですよね。コミュニティで毎週のように同じ質問が来ますから。
テキトー教師まとめるとこうなります。
| エラー・症状 | 原因 | 対処法 |
|---|---|---|
| イテレーションが動かない | 入力が配列型になっていない | コードノードで Array[String] に変換する |
| 出力変数エラー | イテレーション内の出力変数が未設定 | 設定パネルのOUTPUT VARIABLESで指定する |
| 処理が途中で止まる | 処理件数が上限に達した | 配列を分割するか、ループと組み合わせる |
| 結果がJSON形式のまま | 配列をテキスト変換していない | コードノードでjoin()処理を追加する |
| API制限エラー | 並列モードで同時リクエストが多すぎる | 並列数を下げるか、順次モードに変更する |
室谷一番多いのが「入力が配列型になっていない」ですね。コードノードで配列を作るときに出力変数の型設定を忘れると、イテレーションが受け取れなくて詰まります。
テキトー教師「結果がJSON形式のまま」も頻発します。イテレーションの出力をそのまま終了ノードに渡そうとすると「JSON形式のみが出力されました」と表示される。
コードノードで文字列に変換する一手間を忘れずに。
コードノードで文字列に変換する一手間を忘れずに。
室谷あとは、ハルシネーションという観点でも一つ。Difyのイテレーション内でLLMを使う場合、1件ずつ独立した処理になるので、前の件の文脈を引き継ぎません。
これを誤解して「前の処理結果を踏まえて次の処理をさせたい」と思うとうまくいかないんですよね。その場合はループノードを使う方が適切です。
これを誤解して「前の処理結果を踏まえて次の処理をさせたい」と思うとうまくいかないんですよね。その場合はループノードを使う方が適切です。
よくある質問(FAQ)
テキトー教師Qとして、「イテレーションの中でコードを書かずに処理を組めますか?」というのをよく受けます。
室谷答えはYesですが、ある程度の工夫が必要です。パラメータ抽出ノードを使って配列を作り、イテレーション内にLLMノードだけ置く構成であればコードレスで組めます。
ただ、出力をテキストに変換する部分はテンプレートノードを使えばコードなしでいけます。
ただ、出力をテキストに変換する部分はテンプレートノードを使えばコードなしでいけます。
テキトー教師「並列モードと順次モード、どちらを使えばいいですか?」という質問も多いです。
室谷基本は順次モードから始めて、速度が問題になったら並列モードを試す、という順序がいいですね。並列モードはAPI制限との兼ね合いがあるので、本番前に小さい配列でテストしてから使う方が安心です。
テキトー教師「配列ではなくて、文字列をそのままイテレーションに渡せますか?」もよく聞かれます。答えはNoです。
必ず配列型のデータを渡す必要があります。文字列の場合はコードノードかパラメータ抽出で変換してから接続してください。
必ず配列型のデータを渡す必要があります。文字列の場合はコードノードかパラメータ抽出で変換してから接続してください。
まとめ
室谷今回はDifyのイテレーション(反復処理)について、基本概念から実践的な使い方まで解説しました。ポイントをまとめると・・・
テキトー教師こういう整理になりますね。
- イテレーションは配列の各要素に同じ処理を適用するノード
- 入力は必ず配列(Array)型が必要。コードノードやパラメータ抽出で準備する
- 組み込み変数
items(現在の要素)とindex(インデックス)が使える - 順次モードはストリーミング可能、並列モードは高速処理向け
- 出力は配列なので、終了ノードに渡す前にコードノードかテンプレートノードでテキストに変換する
- エラーハンドリングで「終了」「エラー時継続」「失敗結果を除去」が選べる
- 1回の処理件数には上限があるため、大量データは分割が必要
室谷Difyのイテレーションを使いこなせると、バッチ処理系の自動化が一気に広がります。「同じ処理をたくさんのデータにやりたい」という場面では積極的に活用してみてください。
テキトー教師公式ドキュメント()も充実していますし、実際に手を動かしながら試すのが一番の近道です。シンプルな「テキスト3件をLLMで処理する」ワークフローから始めてみましょう。