
Difyの並列処理(パラレルブランチ)完全ガイド:ワークフローを3倍速くする方法
 室谷
室谷今回はDifyの並列処理について話しましょう。これ、.AI(ドットエーアイ)コミュニティでも「ワークフローが遅すぎる」って声がすごく多くて・・・並列処理を知ってるかどうかで、体験が全然変わるんですよね。
 テキトー教師
テキトー教師ほんとそうですね。講座でDifyを教えていて、みんなが最初につまずくのが「なんでこんなに時間かかるの?」ってところなんですよ。
3つのLLMに聞きたいのに、1つずつ順番に実行されて3倍の時間がかかる、みたいな。
3つのLLMに聞きたいのに、1つずつ順番に実行されて3倍の時間がかかる、みたいな。
室谷MYUUUでもDifyを使ったワークフローをたくさん作ってきたんですが、複数のAPIを叩く処理を全部直列で書いてた時期があって。処理時間が30秒を超えることもあって、ユーザー体験的にきつかったんですよね・・・。
並列処理を覚えてからは、それが10秒以下になった。
並列処理を覚えてからは、それが10秒以下になった。
テキトー教師「並列」って聞くとエンジニア向けの難しい話に聞こえるんですけど、Difyはノードを複数の経路に分岐させるだけで実現できるので、非エンジニアでも十分使いこなせますよね。
室谷そう。ブランチを引っ張るだけで、あとはDifyが勝手に並列実行してくれる。
難しいことを考えなくていい。この記事では、概念から実際の設定方法、実践的なユースケースまで全部まとめます。
難しいことを考えなくていい。この記事では、概念から実際の設定方法、実践的なユースケースまで全部まとめます。
Dify並列処理の基本:逐次処理との違い
室谷まず「そもそも並列処理って何?」という話から入りましょう。知ってる人も多いかもしれないけど、Difyのコンテキストでちゃんと整理しておきたいです。
テキトー教師整理すると、こういう構図です。普通のワークフロー(逐次処理)は、タスクAが終わったらタスクBをスタートする、という直列の動き。
一方で並列処理は、タスクA・B・Cを同時にスタートして、全部終わったら次に進む。
一方で並列処理は、タスクA・B・Cを同時にスタートして、全部終わったら次に進む。
室谷図で見るのが一番わかりやすいですよね。
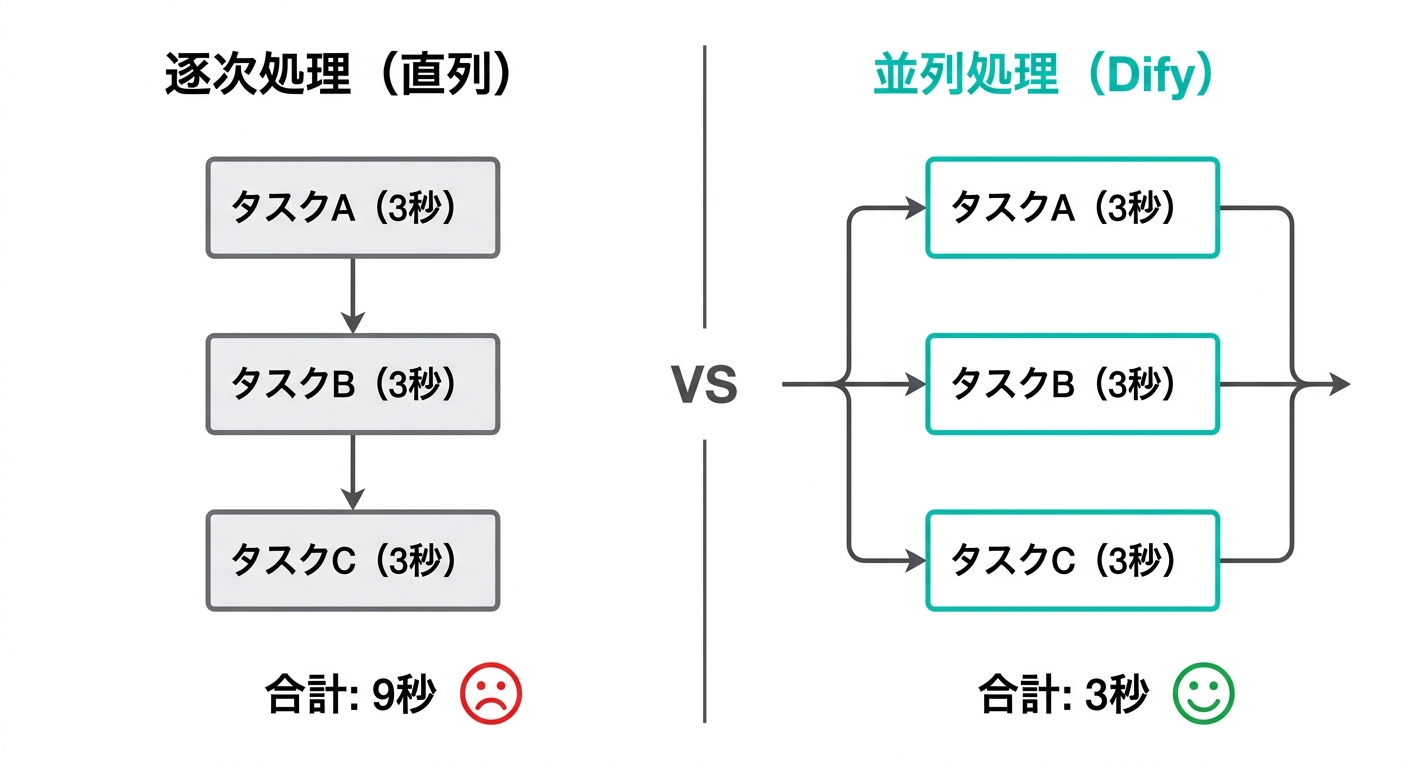
テキトー教師この図が全てですよね。タスクが3つあって、それぞれ3秒かかるとすると、逐次処理では9秒、並列処理では3秒。
理論上は処理数が増えるほど差が開いていく。
理論上は処理数が増えるほど差が開いていく。
室谷Difyで言うと「互いに依存しないタスク」を並列化するのがポイントなんですよ。たとえば「Claudeに聞く」「GPT-4oに聞く」「Geminiに聞く」という3つのタスクは互いに独立してるので、同時に実行できる。
でも「検索結果を受け取ってから要約する」というのは依存関係があるので並列化できない。
でも「検索結果を受け取ってから要約する」というのは依存関係があるので並列化できない。
テキトー教師ここを理解してないと、無闇に並列化しようとして「あれ、変数が渡せない」ってなるんですよね。講座でもここが一番説明しがいのある部分です。
Difyの並列処理で実現できること
室谷実際に何ができるか整理すると、大きく3つですね。
テキトー教師まとめるとこうなります。
| ユースケース | 説明 | 効果 |
|---|---|---|
| 複数LLMへの同時問い合わせ | Claude・GPT・Geminiに同じ質問を同時送信 | 回答時間1/3以下 |
| 複数APIの並列実行 | 天気API・地図API・レストランAPIを同時に叩く | データ収集を高速化 |
| イテレーションの並列モード | 配列の各要素を並列処理 | バッチ処理を大幅高速化 |
室谷特に「複数LLMへの同時問い合わせ」は、AIの回答品質を上げるときに効果的なんですよね。1つのLLMだけじゃなく複数に同じ質問を投げて、一番良い回答を選ぶ、みたいな使い方ができる。
テキトー教師コミュニティのメンバーさんでも「1つのLLMだと出力が偏る」という課題を持ってる方が多いので、複数LLM並列はすごく刺さるユースケースだと思います。
Difyで並列処理を実装する2つの方法
室谷Difyで並列処理を実現する方法は、大きく2つあります。1つは「ブランチ分岐(パラレルブランチ)」、もう1つは「イテレーションノードの並列モード」です。
テキトー教師使い分けを整理すると、処理対象が「固定の複数処理」なのか「配列の各要素」なのかで変わってきますよね。
室谷そうですね。「3つのLLMに聞く」というのは処理内容が決まってるのでブランチ分岐。
「10個の記事タイトルそれぞれについて処理する」というのは配列なのでイテレーション。
「10個の記事タイトルそれぞれについて処理する」というのは配列なのでイテレーション。
方法1:ブランチ分岐(パラレルブランチ)
テキトー教師ブランチ分岐はDifyのワークフローキャンバスで、1つのノードから複数の線を引っ張るだけです。操作としてはシンプルで、LLMノードなりHTTPリクエストノードなりから「+」を押して、複数の行き先にノードをつなぐ。
それだけで並列実行されます。
それだけで並列実行されます。
室谷重要なのが「変数アグリゲーター(Variable Aggregator)」ノードですね。並列に走ったブランチの結果を1つにまとめるためのノードで、これがないと後続処理に結果を渡せない。
テキトー教師ここで詰まる人が多いんですよね(笑)。ブランチを作ったのはいいけど、結果が合流しないって。
変数アグリゲーターは必ずセットで覚えておくべきです。
変数アグリゲーターは必ずセットで覚えておくべきです。
室谷設定の流れを整理するとこうなりますね。
- スタートノードから最初のLLMノードへ接続
- LLMノードから複数のノード(ブランチ1、ブランチ2、ブランチ3)へ接続
- 各ブランチの処理ノードを作成(LLM/HTTPリクエスト等)
- 全ブランチのノードを変数アグリゲーターに接続
- 変数アグリゲーターから後続処理へ接続
テキトー教師この流れを最初に頭に入れておくと、設定でつまずく場所がかなり少なくなります。
方法2:イテレーションノードの並列モード
室谷もう1つがイテレーションノードの並列モードです。Difyの公式ドキュメント()にも記載されている機能で、配列の各要素をイテレーションするときに「Sequential Mode」と「Parallel Mode」を選べます。
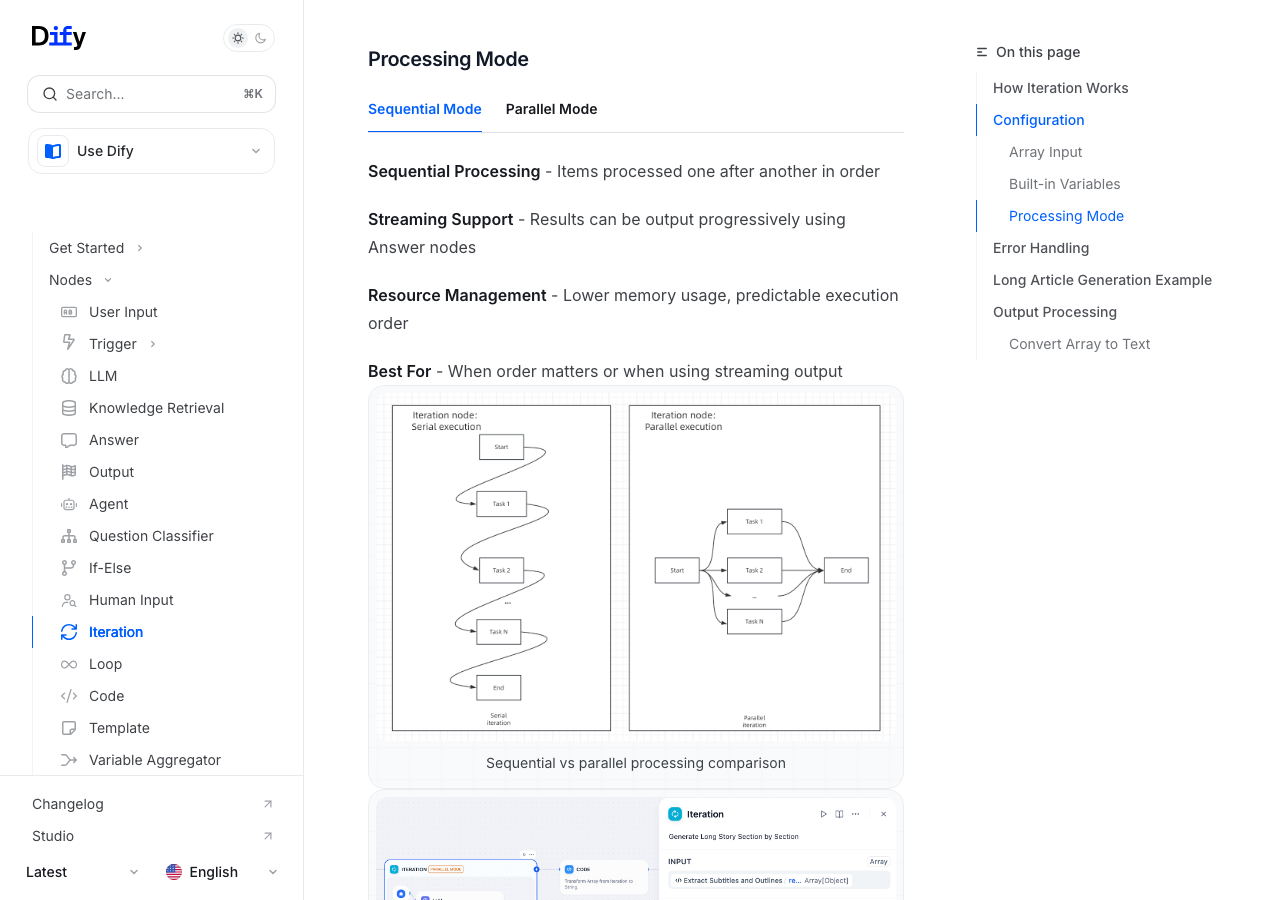
テキトー教師Sequential Mode(順次処理)は順番通りに1つずつ処理する、Parallel Mode(並列モード)は配列の要素を同時に処理する。デフォルトはSequentialなので、意識して設定する必要がありますね。
室谷イテレーションのエラーハンドリングも重要です。Terminate(エラーで停止)、Continue on Error(エラーをスキップして継続)、Remove Failed Results(失敗した要素を除外)の3つから選べる。
テキトー教師並列モードだと特にエラーハンドリングが重要になります。複数の要素を同時に処理していて、1つが失敗したときにどう振る舞うか。
業務で使う場合は「Continue on Error」にしておくと安全なことが多いです。
業務で使う場合は「Continue on Error」にしておくと安全なことが多いです。
室谷入出力の対応を理解しておくと後続処理の設計が楽になります。
- 入力:
[1, 2, 3] - Continue on Errorの場合:
[result-1, null, result-3](失敗した要素はnull) - Remove Failedの場合:
[result-1, result-3](失敗した要素を除外)
テキトー教師この仕様を知っておくと後続処理の設計が楽になりますよね。nullが混じるのか、要素数が変わるのか、事前に分かってれば対応できる。
実践ユースケース:複数LLMを並列で比較する
室谷一番わかりやすい実践例として、複数LLMへの同時問い合わせを見ていきましょう。MYUUUでも実際に使っているパターンです。
テキトー教師コミュニティのメンバーさんからも「試してみたい」という声が多いユースケースですよね。
室谷Dify2.0で搭載されたキュー駆動グラフエンジン(Queue-based Graph Engine)についても触れておきたいです。
テキトー教師ブランチが並列に走るだけでなく、エラーが起きたときに「その分岐だけ再実行」できるようになる、というのは大きな進化ですよね。従来は1つでも失敗したら最初からやり直しだったわけで。
室谷業務自動化の観点から言うと、エラー時の再実行が分岐単位でできるのは設計の幅が広がります・・・。ワークフロー構成のイメージをまとめるとこうなります。
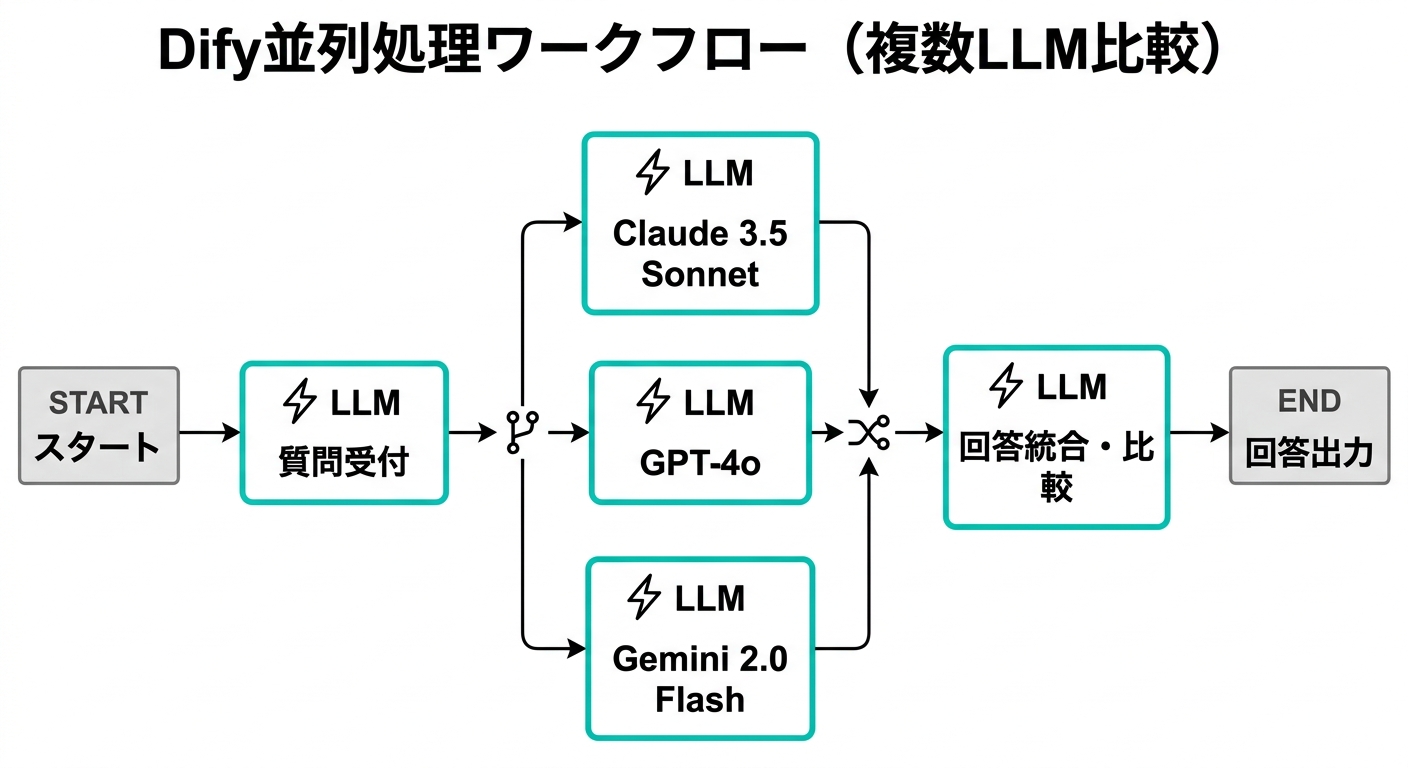
テキトー教師スタートノード → 質問受付LLM → 3並列(Claude 3.5 Sonnet・GPT-4o・Gemini) → 変数アグリゲーター → 回答統合LLM → 出力、という流れですね。
室谷変数アグリゲーターで3つのLLMの回答をまとめた後、最後のLLMに「3つの回答を比較して最も網羅的なものを選んでください」と指示する。これで自動的に回答品質が上がります。
テキトー教師「AIにAIを評価させる」という発想が面白いですよね。これ、1つのLLMだけで実現しようとすると、3回に分けて問い合わせる必要があって時間がかかる。
並列処理で同時に叩いてから評価させる構成が圧倒的に速い。
並列処理で同時に叩いてから評価させる構成が圧倒的に速い。
情報収集を並列化して高速レポート生成
室谷もう1つの実践例として、複数のデータソースから同時に情報収集するパターンもよく使います。
テキトー教師HTTPリクエストノードを複数のAPIに向けて同時に投げる、という構成ですよね。
室谷ビジネス情報の収集ワークフローで、こんな構成を組んだことがあります。
- ブランチ1: 業界ニュースAPIからデータ取得
- ブランチ2: 競合他社の公式サイトをスクレイピング
- ブランチ3: 社内データベースAPIから関連情報取得
テキトー教師3つを逐次処理すると、それぞれ5秒かかれば合計15秒。並列処理なら最も時間のかかる処理1つ分、約5秒で終わる。
室谷しかも後続の集約LLMが「以下の3つの情報を統合して、200字のサマリーを作成してください」と指示すれば、人力で数時間かかる調査が自動化できる。MYUUUでも競合調査や市場調査の自動化にこの構成を使っています。
イテレーション並列処理の実践:大量データのバッチ処理
テキトー教師イテレーションの並列モードが特に威力を発揮するのは、大量データのバッチ処理ですよね。
室谷そうですね。たとえば「100個のキーワードについて、それぞれSEO分析をする」というタスクを考えると、逐次処理では100回 × LLM処理時間がかかる。
並列モードに切り替えるだけで、これが大幅に短縮できます。
並列モードに切り替えるだけで、これが大幅に短縮できます。
テキトー教師講座で実際にやってみせると、目に見えて速さが変わるので、受講生さんの反応がわかりやすくていいんですよね(笑)。
室谷イテレーション並列処理の設定手順を整理すると、こうなります。
- Parameter ExtractorまたはCodeノードで、処理したいデータを配列に変換
- イテレーションノードを追加し、入力変数に配列を接続
- イテレーション内部に処理ノード(LLM等)を追加
- イテレーション設定で「Parallel Mode」を選択
- エラーハンドリングを設定(Continue on ErrorまたはRemove Failed)
- イテレーション出力を後続処理に接続
テキトー教師ステップ4が肝心で、デフォルトはSequentialなので忘れずにParallelに切り替えること。意外とここを見落とす人が多いんですよね。
室谷イテレーションの出力は配列です。たとえば10個のキーワード分析をして10個の結果が配列で返ってくる。
これをそのまま使うか、Codeノードでテキスト化するかは用途によって変わります。
これをそのまま使うか、Codeノードでテキスト化するかは用途によって変わります。
テキトー教師Dify公式ドキュメントにもコードノードでの配列変換の例が載っています。
def main(articleSections: list):
return {
"result": "\n".join(articleSections)
}
これをCodeノードに入れれば、配列を結合したテキストとして後続に渡せます。
よくある失敗パターンとトラブルシューティング
テキトー教師ここからは「よくある詰まりどころ」の話をしましょう。講座やコミュニティで本当によく出る質問です。
室谷並列処理を初めて組む人が必ず1回はハマるやつですね(笑)。
変数が後続ノードに渡らない
テキトー教師ダントツで多いのが「変数が渡らない」という問題です。
室谷原因の9割は「変数名のタイポ」か「アグリゲーターの設定漏れ」です。並列ブランチ内のノードで出力変数を定義して、それを変数アグリゲーターで正しく参照しているか確認する。
変数名は一文字でも違うと動かない。
変数名は一文字でも違うと動かない。
テキトー教師参照するときはアグリゲーターのノード名も含めて正確に入力する。ここがよくミスポイントです。
特定のブランチだけエラーになる
室谷これはAPIキーの問題やURLの間違いが多いです。並列処理だと他のブランチが成功してるから気づきにくい。
デバッグするときは、問題のあるブランチだけを単独で実行してエラーメッセージを確認する。
デバッグするときは、問題のあるブランチだけを単独で実行してエラーメッセージを確認する。
テキトー教師Difyのデバッグ機能でノードごとの入出力を確認できるので、どのノードで何が起きているか追いやすいです。
変数アグリゲーターで結果が期待通りにまとまらない
室谷変数アグリゲーターは「値を合流させるだけ」で、加工はしません。「2つのテキストを結合したい」という場合は、アグリゲーターの後にCodeノードかLLMノードを挟む必要があります。
テキトー教師「アグリゲーターは合流地点、加工は別ノードで」という理解が重要ですよね。ここを混同してる人が多いです。
並列処理を使うべき場面・使うべきでない場面
室谷並列処理は万能ではないので、使い分けが大事です。経営者的な目線で言うと「コスト」の問題もあって。
テキトー教師どういうことですか?
室谷複数LLMに並列で問い合わせると、APIコストも並列で発生するんですよ。3つのLLMに同じ質問を投げたら、3倍のコストがかかる。
だから「並列にすれば速くなるから全部並列に」じゃなくて、ちゃんと設計が必要です・・・。
だから「並列にすれば速くなるから全部並列に」じゃなくて、ちゃんと設計が必要です・・・。
テキトー教師早さとコストのトレードオフを意識する必要がある。整理するとこうなります。
| 並列処理を使うべき場面 | 並列処理を使うべきでない場面 |
|---|---|
| タスク間に依存関係がない | 後のタスクが前のタスクの結果に依存する |
| 応答速度がユーザー体験に影響する | コストを厳密に管理する必要がある |
| 複数のデータソースを同時に取得したい | 処理の順序が重要な場合 |
| 回答品質を高めたい(複数LLM比較) | ストリーミング出力が必要な場合 |
室谷特に「ストリーミング出力が必要な場合は並列化しにくい」というのは知っておくべきポイントです。Dify公式ドキュメントによると、イテレーションのSequentialモードだとAnswerノードでストリーミング出力ができるが、Parallelモードではできない、という制約があります。
テキトー教師ユーザーに「考え中...」という進捗を見せながら処理したい場合はSequentialのままにしておく、という設計判断が必要になるわけですね。
FAQ:Dify並列処理についてよくある質問
室谷コミュニティでよく来る質問をまとめましょう。
テキトー教師Q&Aで整理しますね。
Q: 並列処理の同時実行数に上限はありますか?
室谷Difyのクラウド版では同時実行数に上限があります。過剰な並列処理は他のユーザーへの影響や、LLMプロバイダーのレート制限に引っかかる可能性があります。
イテレーションの並列モードでは、過剰な並列数を設定しないよう注意が必要です。
イテレーションの並列モードでは、過剰な並列数を設定しないよう注意が必要です。
テキトー教師実用上は処理の複雑さやプランに応じて調整するのが安全だと思います。
Q: 並列処理した結果の順序は保証されますか?
室谷基本的に保証されません。どのブランチが先に終わるかは実行タイミング次第です。
変数アグリゲーターで合流させる際も、順序は不定です。
変数アグリゲーターで合流させる際も、順序は不定です。
テキトー教師イテレーションの場合は、公式ドキュメントによると配列として結果が収集されます。ただし内部の実行順は並列なので、順序依存の処理は注意が必要です。
Q: 並列処理のコストはどうなりますか?
室谷LLMを複数並列で実行すれば、APIコストはその分増えます。3つのLLMに並列で問い合わせれば、消費トークン数は3倍になる。
Dify自体のAPIコストが増えるわけではないですが、各LLMプロバイダーへの費用が増加します。
Dify自体のAPIコストが増えるわけではないですが、各LLMプロバイダーへの費用が増加します。
テキトー教師コスト試算をしてから設計するのがいいですよね。「速さ × コスト」のバランスをどこに設定するか。
Q: セルフホスト版でも並列処理は使えますか?
室谷使えます。並列処理はDifyのワークフローエンジンが担うので、クラウド版・セルフホスト版どちらでも動作します。
ただし、実行環境のリソース(CPU・メモリ)によって実際の並列実行パフォーマンスは変わります。
ただし、実行環境のリソース(CPU・メモリ)によって実際の並列実行パフォーマンスは変わります。
まとめ:Dify並列処理でワークフローを進化させよう
室谷まとめましょう。Difyの並列処理を活用する最大のポイントは「タスク間の依存関係を見抜く力」だと思います。
依存しないタスクをどれだけ並列化できるか、これがワークフロー設計の腕の見せ所です・・・。
依存しないタスクをどれだけ並列化できるか、これがワークフロー設計の腕の見せ所です・・・。
テキトー教師「まず1つ作ってみる」が大事です。難しく考えすぎずに、2つのLLMを並列で走らせて速さの違いを体感してみる。
そこから応用していけばいい。
そこから応用していけばいい。
室谷MYUUUでも当初は全部逐次処理で組んでいたんですが、並列処理を覚えてから処理時間が大幅に改善しました。特に「複数のLLMを比較させる」という使い方は、AIの回答品質を上げながら速度も落とさないという一石二鳥の効果があります。
テキトー教師この記事で学んだ内容を整理すると、Dify並列処理には「ブランチ分岐」と「イテレーション並列モード」の2つのアプローチがある。前者は固定数の処理を並列化、後者は配列の各要素を並列化する。
どちらも変数の扱いと、エラーハンドリングの設計が肝心です。
どちらも変数の扱いと、エラーハンドリングの設計が肝心です。
室谷Difyの並列処理をマスターすると、ワークフロー設計の幅が一段階広がります。ぜひ公式ドキュメントも参照しながら、実際に手を動かしてみてください。
出典・参考資料
- Dify公式ドキュメント - Iteration Node: https://docs.dify.ai/en/guides/workflow/node/iteration
- 室谷 @0x__tom ポスト(Dify2.0並列処理について): https://twitter.com/0x__tom/status/1966372533525241890