
Difyの変数集約器とは?ワークフロー設計が変わる仕組みを徹底解説
 室谷
室谷今回はDifyの変数集約器の話をしましょう。.AI(ドットエーアイ)のコミュニティでも「ワークフローが複雑になってきた」という声をよく聞くんですが、その悩みを根本から解決するのがこのノードなんですよね。
 テキトー教師
テキトー教師ですよね。講座でワークフローを教えていると、ある段階から「分岐させたいんだけど、その後の処理をどうまとめればいいの?」という壁に当たる受講生さんが必ず出てきます。
変数集約器を知る前と知った後で、ワークフロー設計の発想がガラッと変わるんですよ。
変数集約器を知る前と知った後で、ワークフロー設計の発想がガラッと変わるんですよ。
室谷まず定義から整理しましょう。変数集約器は、Difyのワークフローで「異なる実行パスから生まれた変数を、ひとつの出力にまとめる」ノードです。
公式ドキュメントでは「Variable Aggregator(変数アグリゲーター)」とも呼ばれていて・・・
公式ドキュメントでは「Variable Aggregator(変数アグリゲーター)」とも呼ばれていて・・・
テキトー教師名前が「変数集約器」と「変数アグリゲーター」の2つあって混乱する受講生さんも多いんですが、同じものです。DifyのUI上での表示名が変わっただけで、機能は同一ですね。
室谷そうなんですよ。で、このノードが必要になる背景を先に話した方が理解しやすいと思って。
MYUUUでもDifyのワークフローをガッツリ使っているんですが、条件分岐を入れた瞬間に「同じ処理を複数のブランチに書き直す」という問題が発生するんですよね・・・
MYUUUでもDifyのワークフローをガッツリ使っているんですが、条件分岐を入れた瞬間に「同じ処理を複数のブランチに書き直す」という問題が発生するんですよね・・・
テキトー教師これ、ほんとに全員ハマります(笑)。If-Elseで「質問の種類によって検索するナレッジを変える」というワークフローを作ると、技術的な質問のブランチにもLLMノードが必要、料金に関する質問のブランチにもLLMノードが必要、と同じノードを何度も配置しなきゃいけなくなる。
室谷まさにそれが「変数集約器なしの世界」の辛さで。変数集約器を使えば、各ブランチの結果をひとつにまとめてから、LLMノードは1個で済む。
シンプルでしょ。
シンプルでしょ。
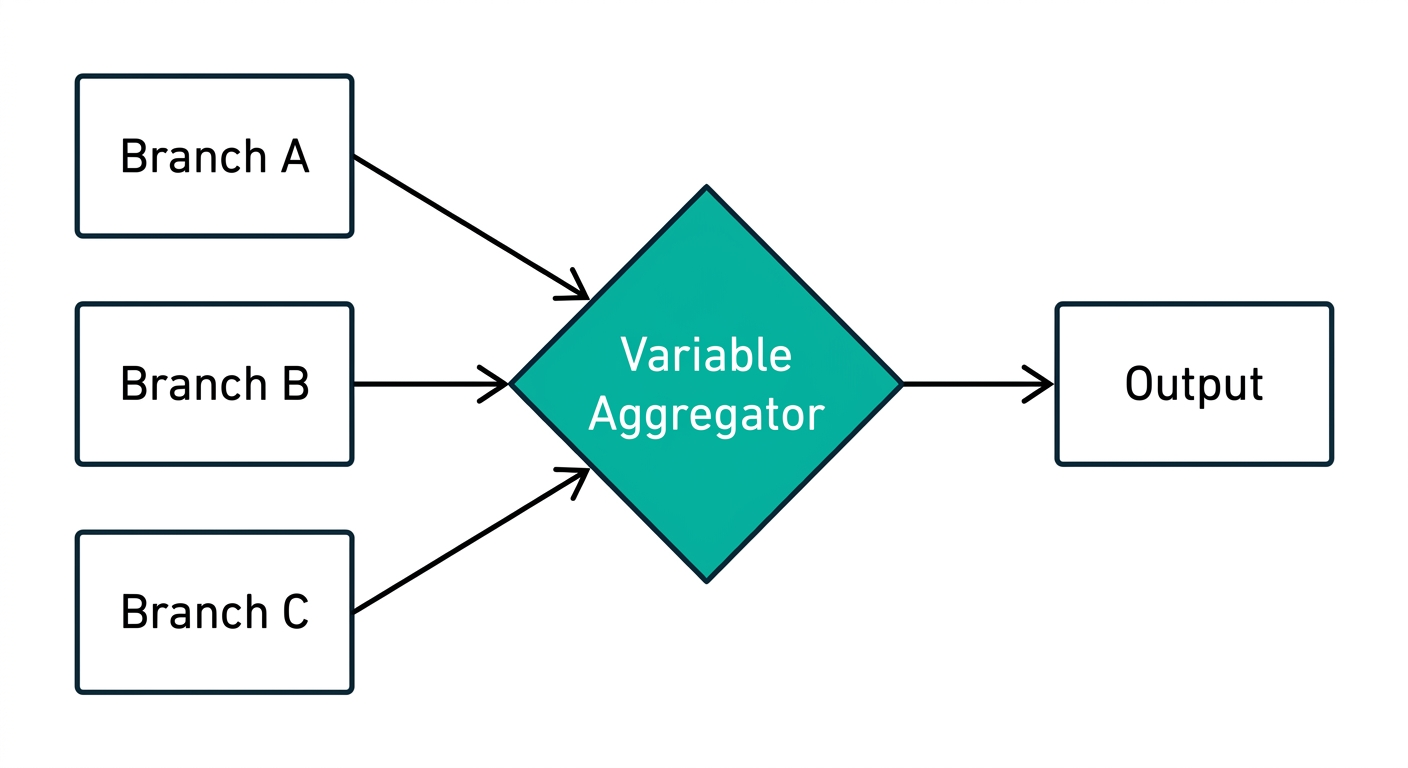
なぜワークフローが複雑化するのか:分岐問題の本質
テキトー教師変数集約器を理解するには、まず「分岐問題」を理解する必要があります。こういう構造で考えるとわかりやすいです。
室谷Difyのワークフローで条件分岐(If-Else)や問題分類器を使うと、複数のブランチが生まれます。このブランチは「一度に1つしか実行されない」という特性があるんですよね。
テキトー教師ここが肝心なんですよ。例えばユーザーの入力を「技術的な質問」「料金の質問」「その他」の3つに分類するワークフローを作るとします。
各カテゴリで異なるナレッジベースを検索したい。
各カテゴリで異なるナレッジベースを検索したい。
室谷そこで変数集約器を使わないと、こうなるわけです。
- 技術質問ブランチ → ナレッジ検索A → LLMノードA → 回答ノードA
- 料金質問ブランチ → ナレッジ検索B → LLMノードB → 回答ノードB
- その他ブランチ → ナレッジ検索C → LLMノードC → 回答ノードC
テキトー教師LLMと回答ノードが3セットずつ必要になる。ブランチが増えるほど、同じノードが増殖していく。
これがメンテナンスの地獄ですね(笑)。
これがメンテナンスの地獄ですね(笑)。
室谷変数集約器があると、各ブランチのナレッジ検索結果を1か所にまとめてから、LLMノードは1個で済む。ワークフローの見た目もスッキリするし、修正も1箇所で完結するんですよ。
テキトー教師公式ドキュメントにも「集約されたワークフローでは、同じ機能を維持しながら複雑さを大幅に削減します」とあって、まさにそれです。
変数集約器の基本的な設定方法
室谷では実際の使い方を見ていきましょう。ノードの追加から設定まで、順を追って説明します。
テキトー教師基本の操作手順はこちらです。
- ワークフロー画面で、集約させたいブランチのいずれかのノード右端の「+」をクリック
- ノード一覧から「変数集約器」を選択して追加
- 他のブランチのノード右端の「+」から、変数集約器のブロックにドラッグして接続
- 変数集約器をダブルクリックして設定画面を開く
- 「変数を代入する」の横の「+」をクリックして、集約したい変数を追加
室谷ドラッグで接続するところが最初は直感的じゃないと感じる人もいるんですよね。でも慣れると「ノードとノードをつなぐ」感覚が視覚的でわかりやすい。
テキトー教師受講生さんに「どの変数を集約するか」を考えてもらうと、ワークフロー全体のデータの流れが自然に整理されてくるんですよ。変数集約器を設定する作業が、ワークフロー設計の見直しにもなる。
室谷集約する変数を決める作業が「このブランチで最終的に何を出力すべきか」を決める作業にもなるから、ワークフロー全体の設計が明確になる効果があるんですよね。
テキトー教師あと注意点として、集約する変数は同じデータ型でなければいけません。文字列なら文字列、数値なら数値で揃える必要があります。
室谷これは仕様上の制約なんですが、実際に困ることはほぼないですね。同じブランチの結果を集約するなら、同じ型になるのが自然だし・・・
テキトー教師ただし、テキスト回答と数値スコアを同時に集約したいケースは出てくる。そういう時は「複数集約グループ」を使います。
これが後ほど説明する応用機能ですね。
これが後ほど説明する応用機能ですね。
変数集約器が対応するデータ型
室谷データ型の話を整理しておきましょう。Difyの変数集約器がサポートしているデータ型はこちらです。
| データ型 | 概要 | 使用例 |
|---|---|---|
| 文字列 | テキスト出力 | LLMの回答、ナレッジ検索結果 |
| 数値 | 数値データ | スコア、計算結果、件数 |
| オブジェクト | 構造化データ | JSONオブジェクト、複合データ |
| ブール値 | True/False | 判定結果、フラグ |
| 配列 | リスト・コレクション | 検索結果一覧、複数出力 |
テキトー教師実務でよく使うのは「文字列」と「配列」ですね。複数のブランチからLLMが返してきたテキストを集約するのが文字列型の典型で、ナレッジ検索の結果リストを集約するのが配列型の典型です。
室谷オブジェクト型も便利なんですよね。「ユーザーの属性データと検索結果を一緒に次のノードに渡したい」みたいなケースで使えます。
MYUUUだとエージェントへのコンテキスト受け渡しによく使っています。
MYUUUだとエージェントへのコンテキスト受け渡しによく使っています。
テキトー教師ただし1つの集約ノードに接続する変数はすべて同じ型でないといけない。最初に接続した変数の型が自動的に「このグループの型」として設定され、それと異なる型の変数は追加できなくなる仕組みです。
室谷「文字列と数値を混ぜてひとつの変数にまとめる」って、データとして意味が通らないですもんね。直感的に正しい制約だと思います。
If-Else分岐での変数集約器の使い方:基本パターン
テキトー教師次は実際のユースケースを見ていきましょう。一番使われるのがIf-Elseブランチ後の集約です。
室谷講座で一番最初に紹介するパターンです。シンプルな例で言うと、ユーザーが「無料プランの機能を知りたい」と入力した場合と「有料プランの機能を知りたい」と入力した場合で、検索するナレッジベースが違う。
テキトー教師こんなワークフロー構成になりますよね。
- ユーザー入力ノード
- If-Elseノード(「無料」or「有料」を判定)
- 無料プランブランチ → ナレッジ検索(無料プランDB)
- 有料プランブランチ → ナレッジ検索(有料プランDB)
- 変数集約器(両方の検索結果をまとめる)
- LLMノード(集約された検索結果を元に回答生成)
- 回答ノード
室谷変数集約器がなければ、LLMノードと回答ノードが「無料プランブランチ用」「有料プランブランチ用」と2セット必要だったところが、変数集約器で結果をまとめることで1セットに減らせます。
テキトー教師出力の変数名も統一されるんですよ。変数集約器の出力変数は
outputという名前で参照できるので、後続のLLMノードは「どちらのブランチが実行されたか」を意識せずにoutputを参照するだけでいい。室谷これが「下流ノードの重複処理を排除する」という公式の説明の意味です。後続ノードの視点から見ると、上流で何が起きたかを気にしなくてよくなる。
シンプルに
シンプルに
outputを受け取るだけでいいんですよね。テキトー教師ワークフローが大きくなると修正コストが跳ね上がるので、重複ノードを減らすことでメンテナンス工数が全然違ってきます。分岐を1つ追加するたびに複数ノードを追加していたら、すぐに収拾がつかなくなる。
問題分類器との組み合わせパターン
室谷次は問題分類器(Question Classifier)との組み合わせです。.AIのコミュニティでも「どう設計すればいいの?」と聞かれることが多くて。
テキトー教師問題分類器はDifyのノードのひとつで、ユーザーの入力を複数のカテゴリに自動分類するものです。「技術サポート」「料金・プラン」「一般的な使い方」みたいなカテゴリを事前に定義しておくと、入力に応じて自動的に振り分けてくれる。
室谷カスタマーサポートBotを作る時の定番パターンです。各カテゴリで参照するナレッジベースが違う場合に変数集約器が活躍します。
テキトー教師構成はこんな感じになります。
- 問題分類器(3〜5カテゴリに分類)
- カテゴリAブランチ → ナレッジ検索A(技術ドキュメント)
- カテゴリBブランチ → ナレッジ検索B(料金FAQ)
- カテゴリCブランチ → ナレッジ検索C(操作マニュアル)
- 変数集約器(全ブランチの検索結果をまとめる)
- LLMノード(検索結果を元に最終回答を生成)
室谷カテゴリが増えても、変数集約器以降のLLMノードは変えなくていいんですよ。カテゴリを追加するたびにブランチとナレッジ検索だけ追加して、変数集約器に繋ぐだけ。
スケーラブルな設計になる。
スケーラブルな設計になる。
テキトー教師教える立場からすると、このパターンが「変数集約器の価値」を一番実感しやすいんですよ。変数集約器なしだと、カテゴリを1つ追加するたびにLLMノードと回答ノードも1セット追加しなきゃいけなくなるので、「ワークフローが横に広がっていく」感じになる。
室谷変数集約器があるとワークフローが縦に伸びていく感じで、全体像がつかみやすくなりますよね。MYUUUでもカスタマーサポート系のワークフローでこのパターンをよく使っています。
複数集約グループの使い方(v0.6.10以降)
テキトー教師ここからは応用機能の話をしましょう。複数集約グループです。
室谷これはDifyのv0.6.10から使えるようになった機能です。1つの変数集約器の中で、複数の独立したグループを持てる。
各グループが独自の型制約を持てるので、「文字列の結果」と「数値のスコア」を同じノードで同時に集約できます。
各グループが独自の型制約を持てるので、「文字列の結果」と「数値のスコア」を同じノードで同時に集約できます。
テキトー教師具体的なユースケースを挙げると・・・複数のLLMで同じ質問に回答させて、それぞれの回答テキストと信頼スコアを集約するワークフローです。
室谷コンテンツ生成でも使えますよね。複数のスタイルで文章を生成させて、「本文テキスト(文字列)」と「評価スコア(数値)」を別グループで集約する。
テキトー教師設定方法を説明します。変数集約器の設定画面で「グループ」ボタンをクリックするとグループモードがオンになります。
- 変数集約器の設定画面を開く
- 「グループ」ボタンをクリックしてグループモードを有効化
- グループ1(例:文字列型)の「+」から変数を追加
- 「グループを追加」をクリックして新しいグループを作成
- グループ2(例:数値型)の「+」から変数を追加
室谷後続ノードでは、グループ1の出力は
output.group1、グループ2はoutput.group2みたいな形で参照できます。テキトー教師ブランチが複数の関連する出力を生成していて、それらを個別に下流ノードに渡したいケースに最適です。講座の上級コースで教えているんですが、これを使いこなすと「Difyのワークフローらしさ」が全然変わってくるんですよね。
出力動作の仕組み:実行されたブランチの値だけが出力される
室谷少し技術的な話になりますが、変数集約器の出力動作を理解しておくと、デバッグがしやすくなります。
テキトー教師ここ、意外と見落とされがちなんですよ。変数集約器は「実際に実行されたブランチからの値」を出力します。
室谷条件付きワークフローでは一度に1つのブランチしか実行されないので、実行中は集約ノードへの入力変数のうち1つだけが値を持つ状態になります。他のブランチの変数は空になっている。
テキトー教師これ、「集約」という言葉から「全ブランチの値を全部まとめる」と誤解する受講生さんがたまにいて。実際は「実行されたブランチの値がoutputになる」というシンプルな動作です。
室谷だからこそ、後続のLLMノードは「どのブランチが実行されたかを気にしなくていい」んですよ。実行されたブランチの結果だけがoutputに入っているので、outputを参照するだけで正しい値が取れる。
テキトー教師エラーハンドリングの観点でも重要で。ワークフローの途中でエラーが発生したブランチの変数は、後続の処理に渡らないように設計されています。
これでデータの整合性が保たれる。
これでデータの整合性が保たれる。
室谷この設計、すごく合理的ですよね。「どこかのブランチが失敗しても、ちゃんと動いたブランチの結果だけが流れていく」という安全な仕組み。
変数集約器の使い方:実践的なTips
テキトー教師実際にワークフローを組むときに知っておくと便利なTipsを共有しましょう。まずノードの命名です。
室谷これ地味だけど重要なんですよね。変数集約器には複数のブランチが接続されるので、「どのブランチからの変数か」がわかる名前をつけておくと後のメンテナンスがラクになる。
テキトー教師設定画面でノードに名前がつけられるので「無料プラン用集約」「有料プラン用集約」みたいに用途を明確にするのがコツです。受講生さんによく言っているんですが、ワークフローが大きくなると「このノード何のためにあるの?」状態になりやすい。
室谷あと、集約グループを使う場合は「グループ名も明確にする」ことをおすすめします。「テキスト出力」「スコア」みたいに。
テキトー教師デバッグのコツも。変数集約器が正しく動いているかを確認したいときは、一旦変数集約器の直後に「変数アサイナー」か「テンプレート変換」ノードを置いて、outputの中身を確認するとわかりやすいですよ。
室谷ログを見るのが一番確実ですけどね。Difyのワークフロー実行ログで、変数集約器ノードの出力がどんな値になっているか確認できます。
テキトー教師あとは「型の不一致エラー」への対処。集約しようとした変数が異なる型だとエラーになるので、そういう場合はコードノードで型変換してから集約するか、複数集約グループを使う。
室谷コードノードで
str(value)とかint(value)で型変換するのが一番手軽ですね。変数集約器と変数アサイナーの違い
テキトー教師よく混同されるので整理したいのですが、変数集約器と変数アサイナーは別物です。
室谷そうですね。名前が似ているので混乱する人が多いんですが、全然違う役割です。
テキトー教師以下の通りです。
| ノード | 役割 | 使いどころ |
|---|---|---|
| 変数集約器 | 異なるブランチの変数を1つの変数にまとめる | 分岐後の出力を統一したい時 |
| 変数アサイナー | 会話変数に値を保存する | セッションをまたいで値を記憶したい時 |
室谷変数集約器は「ワークフロー内の分岐を合流させる」ためのノードで、変数アサイナーは「会話変数(チャットフローで使えるセッション変数)に値を保存する」ためのノードです。用途が全然違う。
テキトー教師受講生さんでよくあるのが「チャットの途中でユーザーの名前を記憶させたい」という要件を、変数集約器でやろうとするパターン。これは変数アサイナーの仕事ですね。
室谷逆に「条件分岐した後、どちらのブランチが実行されても同じLLMに渡したい」という要件は変数集約器の仕事。この使い分けを覚えておくと設計がスムーズになります。
変数集約器を使った実践ワークフロー設計例
テキトー教師最後に、変数集約器を使った完全なワークフロー設計例を見ていきましょう。コンテンツ自動生成のシナリオです。
室谷MYUUUで実際に使っているパターンに近い例を紹介しますね。入力されたトピックに対して「詳しい解説記事」か「短いSNS投稿」かを自動判定して、それぞれ違うプロンプトで生成するワークフローです。
テキトー教師構成はこうなります。
- スタートノード: トピックとコンテンツ種別(詳細/短文)を入力
- If-Elseノード: コンテンツ種別を判定
- 「詳細」→ 詳細記事生成ブランチ(ナレッジ検索 + 長文プロンプト)
- 「短文」→ SNS投稿生成ブランチ(シンプルな短文プロンプト)
- 変数集約器: 両ブランチのLLM出力を集約
- コードノード: 生成されたコンテンツを後処理(文字数チェック等)
- 回答ノード: 最終出力
室谷このワークフローのポイントは、LLMノードが各ブランチに1つずつあって、それぞれ異なるシステムプロンプトを持っていること。でも後段の処理(コードノードと回答ノード)は1セットで済む。
テキトー教師これが変数集約器の真骨頂ですよね。ブランチの「前段」は多様性を持ちながら、変数集約器を境に「後段」はシンプルに統一される。
室谷拡張性もいい。「プレゼン資料用」「メール本文用」と種別を増やしていっても、後段のコードノードと回答ノードは変えなくていいので。
テキトー教師講座の上級ワークフロー設計の回で、このパターンを実際に組んでもらうんですが、変数集約器を使った瞬間に「あ、ワークフロー設計ってこういうことか」ってなる受講生さんが多いんですよ。ブレークスルーの瞬間ですね(笑)。
室谷このポストでも書いたんですが、チャットフローの場合は変数集約器と会話変数を組み合わせると、途中でセーブポイントを作れるんですよ。ワークフローで複雑な処理をやり直したい時はワークフロー全体を最初から再実行するしかないけど、チャットフローなら「ここまでの結果を会話変数に保存しておいて、続きから再実行できる」という設計が可能になる。
テキトー教師これは確かにチャットフローならではの強みですよね。ワークフローとチャットフローの使い分けを考えるうえでも重要な視点です。
変数集約器×ナレッジ検索:RAGワークフローへの応用
室谷実践的な話をもうひとつ。変数集約器とナレッジ検索(RAG)の組み合わせです。
これ、企業向けのAIアシスタントを作る時に必ず使うパターンなんですよね。
これ、企業向けのAIアシスタントを作る時に必ず使うパターンなんですよね。
テキトー教師RAGワークフローで変数集約器が活躍するシーンは主に2つあります。「複数ナレッジベースからの並列検索」と「検索失敗時のフォールバック」です。
室谷「複数ナレッジベースからの並列検索」から説明すると・・・例えば社内向けのAIアシスタントで「社内規程KB」「製品マニュアルKB」「サポートFAQ KB」の3つのナレッジベースがあるとします。
テキトー教師質問の種類によってどのナレッジベースを参照するかが違う。「給与明細の見方を教えて」なら社内規程KB、「製品の仕様は?」なら製品マニュアルKBといった具合です。
室谷このケースで問題分類器+変数集約器の構成を使うと、「どのカテゴリの質問でも最終的に1つのLLMで回答できる」設計が実現できる。
テキトー教師もう1つの「検索失敗時のフォールバック」パターンも便利です。If-Elseで「ナレッジ検索の結果が空かどうか」を判定して、「空でない場合→検索結果を使って回答」「空の場合→LLMの一般知識だけで回答」という2つのパスを作って、変数集約器でまとめる。
室谷このパターン、MYUUUで実際に使っています。ナレッジベースに情報がない場合でも「知識がありません」で終わらせず、LLMが持っている一般知識で補完して回答できる。
ユーザー体験が全然違うんですよ。
ユーザー体験が全然違うんですよ。
テキトー教師受講生さんでよくある誤解が「ナレッジ検索でヒットしなかった場合の処理が難しい」というものです。変数集約器とIf-Elseを組み合わせると、エラーケースのハンドリングも綺麗に設計できる。
室谷これは「変数集約器の応用」というより「Difyワークフロー設計の本質」に近い話ですよね。データの流れをきちんと設計することが、堅牢なAIアプリケーションにつながる。
変数集約器のデバッグ方法
テキトー教師変数集約器を使ったワークフローのデバッグのコツも共有しておきましょう。
室谷まずDifyのワークフローには「実行ログ」があって、各ノードの入力・出力をリアルタイムで確認できます。変数集約器ノードのログを見ると、どのブランチの変数がoutputに入ったかが確認できる。
テキトー教師デバッグで困るのが「変数集約器にデータが流れてこない」というケースです。原因は大抵、上流のノードが実行されていないか、接続する変数のパスが間違っているかのどちらかですね。
室谷変数のパスが間違っている場合は、設定画面で変数を選択し直すと解決することが多いです。ノードの名前を変えると参照パスが変わってしまうことがあるので。
テキトー教師あとは「型の不一致」。上流ノードの出力型が変わったのに変数集約器の設定が古いままというケースです。
変数集約器の設定を一度リセットして、改めて変数を設定し直すのが確実な対処法です。
変数集約器の設定を一度リセットして、改めて変数を設定し直すのが確実な対処法です。
室谷「変数集約器のoutputが空になる」というケースもあって・・・これは「実行されたブランチがない」場合に起きます。If-Elseのすべての条件に合致しない入力が来た場合とか。
テキトー教師そういう場合はIf-Elseに「それ以外」のブランチを追加して、デフォルトの出力を設定しておくのが安全設計ですね。
変数集約器の使い方:ステップバイステップで実際に組んでみよう
テキトー教師最後に、実際に手を動かしてもらえるよう、シンプルな変数集約器ワークフローの組み方を示します。「2種類の挨拶文を生成して集約する」という入門向けの例です。
室谷これは変数集約器の動作確認にも使えるシンプルな例ですね。構成はこうです。
- スタートノード(
nameとtypeを入力。typeは「formal」か「casual」) - If-Elseノード(
type == "formal"で分岐) - フォーマル分岐 → LLMノードA(丁寧な挨拶文を生成)
- カジュアル分岐 → LLMノードB(カジュアルな挨拶文を生成)
- 変数集約器(LLMノードAとBの出力textを集約)
- 回答ノード(変数集約器のoutputを返す)
テキトー教師このワークフローを実際に組んでテストすると、「typeがformalの時はLLMノードAの出力が、casualの時はLLMノードBの出力がoutputに入る」という動作を確認できます。
室谷動作を確認したら、次はナレッジ検索と組み合わせてみる、問題分類器と組み合わせてみる、というステップアップができます。基本を確認してから応用に進む学習ルートですね。
テキトー教師.AI認定講座でも、まずこのシンプルなパターンで変数集約器の動作を実感してもらってから、実践的なワークフローに進んでいます。「あ、こういう仕組みか」というファーストステップが大事なので。
室谷Difyのワークフロー設計は、変数集約器を含む各ノードの「役割」と「データの流れ」を理解することで、急速に設計力が上がります。最初は小さく始めて、実際に動かしながら学ぶのが一番確実な方法です。
変数集約器を使うべきシーンと使わなくてよいシーン
室谷変数集約器の使い方を覚えると「とりあえず全部集約器を通す」みたいな設計になりがちなんですよね。どういう時に使うべきで、どういう時に使わなくてよいかを整理しましょう。
テキトー教師確かに。講座でもたまに「変数集約器を使いすぎて逆に複雑になった」という相談が来ることがあります(笑)。
室谷使うべきシーンは明確で、「分岐(If-Else・問題分類器)の後、複数のブランチが同じ後続ノードに結果を渡す必要があるとき」です。これが変数集約器の設計意図通りの使い方。
テキトー教師逆に使わなくてよいシーンは、「ブランチが独立していて、それぞれ異なるアクションで終わる場合」ですね。例えばIf-Elseで「条件A→メール送信」「条件B→Slack通知」という場合、それぞれのブランチが独立して完結するので変数集約器は不要です。
室谷もう1つ使わなくてよいシーンとして、「単一パスのワークフロー」があります。分岐がなければ集約する必要がそもそもない。
テキトー教師あとは「順次処理ワークフロー」。A→B→C→D と直列につながっているだけなら変数集約器は不要です。
室谷まとめると、変数集約器が必要かどうかの判断基準は「ワークフロー内に分岐があって、その分岐の後で同じ処理を共有したいか」という1点につきますね。
変数集約器の設計パターン:上級テクニック
テキトー教師少し上級な使い方も紹介しましょう。「ガードクローズパターン」と呼んでいるものです。
室谷おっ、それ聞いたことないな。どういうパターンですか?
テキトー教師If-Elseで「条件を満たす場合のみ特別な処理をして、そうでない場合はデフォルト値を返す」というパターンです。例えば「入力テキストが1000文字以上なら要約処理をかける、それ未満はそのまま返す」という場合。
室谷なるほど。普通に書くとIf-Elseの2つのブランチに「要約LLM」と「そのまま出力」の2パスを作って、変数集約器でまとめる構成になりますよね。
テキトー教師そうです。これが「ガードクローズパターン」で、変数集約器があることで「いずれのパスでも同じ変数名で後続ノードにデータを渡せる」という設計が実現できる。
室谷こういう使い方、.AIのコミュニティでも紹介していきたいですね。ワークフロー設計のデザインパターンが整理されると、初心者が参考にしやすくなる。
テキトー教師もう1つの上級パターンが「並列評価パターン」です。複数のLLMやモデルで同じ入力を処理して、その結果を変数集約器でまとめる。
室谷これは品質評価やコンテンツの多様性が必要な時に使えますよね。同じ文章を複数のモデルで生成させて比較するワークフロー、みたいな。
テキトー教師複数集約グループを使うと「モデルAの出力(文字列)」「モデルBの出力(文字列)」「評価スコア(数値)」を1つの変数集約器で集約できる。
室谷この「並列評価パターン」、コンテンツ生成の品質管理に応用できそうですね。MYUUUでも試してみようかな・・・
Difyワークフロー全体設計における変数集約器の位置づけ
テキトー教師最後に、少し俯瞰した話をしましょう。Difyのワークフロー設計全体の中で、変数集約器はどんな位置づけにあるのか。
室谷ワークフロー設計には3つの構造要素があります。「分岐」「処理」「合流」があります。
変数集約器は「合流」を担当するノードです。
変数集約器は「合流」を担当するノードです。
テキトー教師この3つが揃って初めて「柔軟で拡張可能なワークフロー」が設計できる。分岐はIf-Elseや問題分類器、処理はLLMノードやコードノード、合流が変数集約器です。
室谷海外のDifyコミュニティでも、変数集約器(Variable Aggregator)はワークフロー設計の「必須ノード」として位置づけられているんですよね。
テキトー教師公式ドキュメントの構成を見ても、変数集約器は「変数操作関連ノード」の中でも重要なポジションに置かれています。変数アサイナーや変数代入と同じカテゴリですが、役割が全く違う。
室谷Difyのワークフロー機能は継続的にアップデートされていて、v0.6.10での複数集約グループ追加もその一例です。「より複雑なワークフローを簡潔に記述できるように」というDifyの設計思想が、変数集約器の進化に表れていますよね。
テキトー教師受講生さんから「DifyとLangChainの違いは?」とよく聞かれるんですが、変数集約器みたいな「視覚的にワークフローの合流点が見えるノード」の存在がDifyならではの強みだと説明しています。コードベースのLangChainと違って、設計意図が図として残るので。
室谷ノーコードでワークフローを組める強みはそこですよね。「データの流れが図で見える」という点が、チームで共有する時にも圧倒的にわかりやすい。
テキトー教師ぜひ今回学んだ変数集約器を、実際に自分のワークフローに組み込んでみてください。「分岐後の処理を1つにまとめられた!」という瞬間が、Difyワークフロー設計の腕が上がった証拠です。
室谷Difyのワークフロー設計については、でさらに詳しく学べます。また、.AI(ドットエーアイ)のコミュニティでは実際のワークフロー設計事例を共有しているメンバーも多いので、ぜひ参加してみてください。
よくある疑問:変数集約器のFAQ
Q. 変数集約器と変数アグリゲーターは同じものですか?
室谷同じです。日本語の公式ドキュメントで「変数アグリゲーター」という名称も使われていますが、機能は全く同じです。
DifyのUIバージョンによって表示名が異なる場合がありますが、同一ノードです。
DifyのUIバージョンによって表示名が異なる場合がありますが、同一ノードです。
Q. 集約できる変数の数に制限はありますか?
テキトー教師公式ドキュメントに制限値の記載はありません。実用上はブランチ数の制限(ワークフローのノード数の上限)に依存する形になります。
Q. 変数集約器の出力を複数のノードに渡せますか?
室谷渡せます。変数集約器の
outputは通常のノード出力と同じように扱えるので、後続のLLMノード、コードノード、テンプレート変換ノードなど複数のノードから参照できます。Q. 並列処理(並列ブランチ)と変数集約器は組み合わせられますか?
テキトー教師組み合わせられます。Difyの並列処理ノードで複数のブランチを同時実行して、その結果を変数集約器でまとめるパターンも使えます。
これはまた別のトピックになりますが、並列化と集約の組み合わせでワークフローの処理速度が大幅に上がることがあります。
これはまた別のトピックになりますが、並列化と集約の組み合わせでワークフローの処理速度が大幅に上がることがあります。
Q. 変数集約器でエラーが出た場合の対処法は?
室谷一番よくあるのが「型の不一致エラー」です。接続しようとしている変数のデータ型を確認してください。
文字列と数値が混在している場合は、コードノードで型変換するか複数集約グループを使います。
文字列と数値が混在している場合は、コードノードで型変換するか複数集約グループを使います。
テキトー教師次によくあるのが「変数が見つからない」エラー。前のノードが実行されていなかった場合(条件分岐で別のブランチが実行された場合)に出ることがあります。
変数集約器の動作仕様を確認して、どのブランチが実行されているかログで確認するといいですね。
変数集約器の動作仕様を確認して、どのブランチが実行されているかログで確認するといいですね。
まとめ:変数集約器でワークフローをシンプルに保つ
室谷まとめていきましょう。変数集約器は「分岐後の変数をひとつにまとめる」というシンプルな機能ですが、Difyのワークフロー設計において本質的な役割を持っています。
テキトー教師使う前と使った後で、ワークフロー全体の設計思想が変わりますよね。「重複ノードを増やさない」「後段はシンプルに統一する」という原則が自然に身についていく。
室谷変数集約器が活躍するシーンをまとめるとこうなります。
- If-Else分岐後の合流: 条件によって異なるナレッジを検索し、結果を1つのLLMに渡す
- 問題分類器との組み合わせ: カテゴリ別に処理して最終回答は1カ所で生成する
- 複数LLM出力の集約: 異なるモデルや異なるプロンプトの結果をまとめる
- 並列処理後の統合: 並列実行した複数ブランチの結果を合流させる
テキトー教師変数集約器を使うことで、ワークフローの「前段(多様性・柔軟性)」と「後段(統一・シンプルさ)」を明確に分けられる。これが大規模なワークフロー設計の基本原則です。
室谷Difyのワークフローをより深く学びたい方は、公式ドキュメント()も参考にしてください。図解入りで変数集約器の動作が説明されています。
テキトー教師.AIのコミュニティでもDifyのワークフロー設計について頻繁に議論しているので、「このケースはどう設計すれば?」という疑問があればぜひ聞いてみてください。実際の業務に近い事例でのフィードバックが得られますよ。