
Difyのテキスト抽出ノードとは?PDF・Excelをワークフローで読み込む完全ガイド
 室谷
室谷今回はDifyのテキスト抽出ツール(ドキュメントエクストラクター)について話しましょう。これ、地味に見えるんですけど、実はDifyのワークフローを使いこなす上でかなり重要なノードなんですよね。
 テキトー教師
テキトー教師そうですね。講座でDifyを教えていると、「PDFをAIに読み込ませたい」「ExcelのデータをLLMに処理させたい」という質問が毎回のように出てくるんですが、最初のつまずきポイントがまさにここなんです。
LLMはファイルをそのまま読めないので、テキスト抽出ノードが必要だと知らない人が多くて。
LLMはファイルをそのまま読めないので、テキスト抽出ノードが必要だと知らない人が多くて。
室谷そこはほんと大事な理解ですよね。LLMって基本的にテキストしか処理できないんです。
PDFをアップロードしても、LLMノードに直接渡してもそのままじゃ読めない。だからその間にテキスト抽出ノードを挟んでテキストに変換してからLLMに渡す、という流れが必要で・・・
PDFをアップロードしても、LLMノードに直接渡してもそのままじゃ読めない。だからその間にテキスト抽出ノードを挟んでテキストに変換してからLLMに渡す、という流れが必要で・・・
テキトー教師コミュニティのメンバーさんが最初にDifyでChatPDFを作ろうとして「なんでLLMがPDFを読んでくれないんだ」って詰まるのが、このステップをスキップしているからなんですよね(笑)。テキスト抽出ノードを挟むだけで解決するのに。
室谷この記事では、テキスト抽出ツールノードの基本から、PDF・Excel・画像それぞれの対応状況、実際のワークフロー構築手順、よくある文字化けの原因と対策まで全部解説します。Difyでファイル処理ワークフローを作りたい方は、ぜひ参考にしてみてください。
テキスト抽出ツールノードの基本:何をするノードか
室谷まずそもそもの話をすると、テキスト抽出ツールノードって何をするものかというと、アップロードされたファイルの内容をテキストデータに変換するノードです。シンプルといえばシンプルなんですが、これがないとLLMがファイルを処理できないんですよね。
テキトー教師Difyのには「LLMは文書の内容を直接読み取ることができません」とはっきり書いてあって、だからこそテキスト抽出ツールノードを介してテキストに変換してからLLMに渡す必要がある、と説明されています。
室谷ノードの構造を整理すると、入力変数と出力変数の2つで成り立っています。入力にはFileまたはArray[File]型の変数を指定して、出力は固定で
textという名前の変数になります。テキトー教師この出力の型が入力によって変わるところが少し注意が必要で、入力がFileだとstring、Array[File]だとarray[string]になるんですよね。複数ファイルをまとめて処理するときは配列になる、と覚えておくといいです。
対応ファイル形式一覧
室谷対応しているファイル形式についても整理しておきましょう。公式ドキュメントに記載されているサポートファイルタイプをまとめるとこうなります。
| カテゴリ | 対応形式 |
|---|---|
| テキスト系 | txt, md(Markdown) |
| ドキュメント系 | pdf, html, docx, doc |
| 表計算 | xlsx, xls, csv |
| その他 | xml, epub, pptx, htm, msg |
テキトー教師ここで重要なのが、テキスト抽出ツールはドキュメント系ファイルしか処理できないという点です。画像、音声、動画は処理できないんですよね。
画像ファイルをテキスト抽出ツールに入れても何も出てこないので、よく誤解が生まれるポイントです。
画像ファイルをテキスト抽出ツールに入れても何も出てこないので、よく誤解が生まれるポイントです。
室谷画像から文字を読み取りたい場合はOCRが必要になりますよね。Difyでは画像をLLMに渡してビジョン機能で読み取らせるか、別途OCRツールを組み込む必要があります。
テキスト抽出ツールはあくまでドキュメントの文字データを抜き出すためのものです。
テキスト抽出ツールはあくまでドキュメントの文字データを抜き出すためのものです。
テキトー教師dify テキスト抽出 画像というKWで検索してここに来た方が多いと思いますが、結論を先に言うと「テキスト抽出ツールノードでは画像の文字は読めない」です。画像内の文字を読みたい場合はLLMノードのビジョン機能を使う方法を後ほど解説します。
Difyテキスト抽出ツールの使い方:ワークフロー設定手順
室谷では実際の使い方を説明しましょう。典型的なChatPDFワークフローを例に取ると、設定は大きく4ステップです。
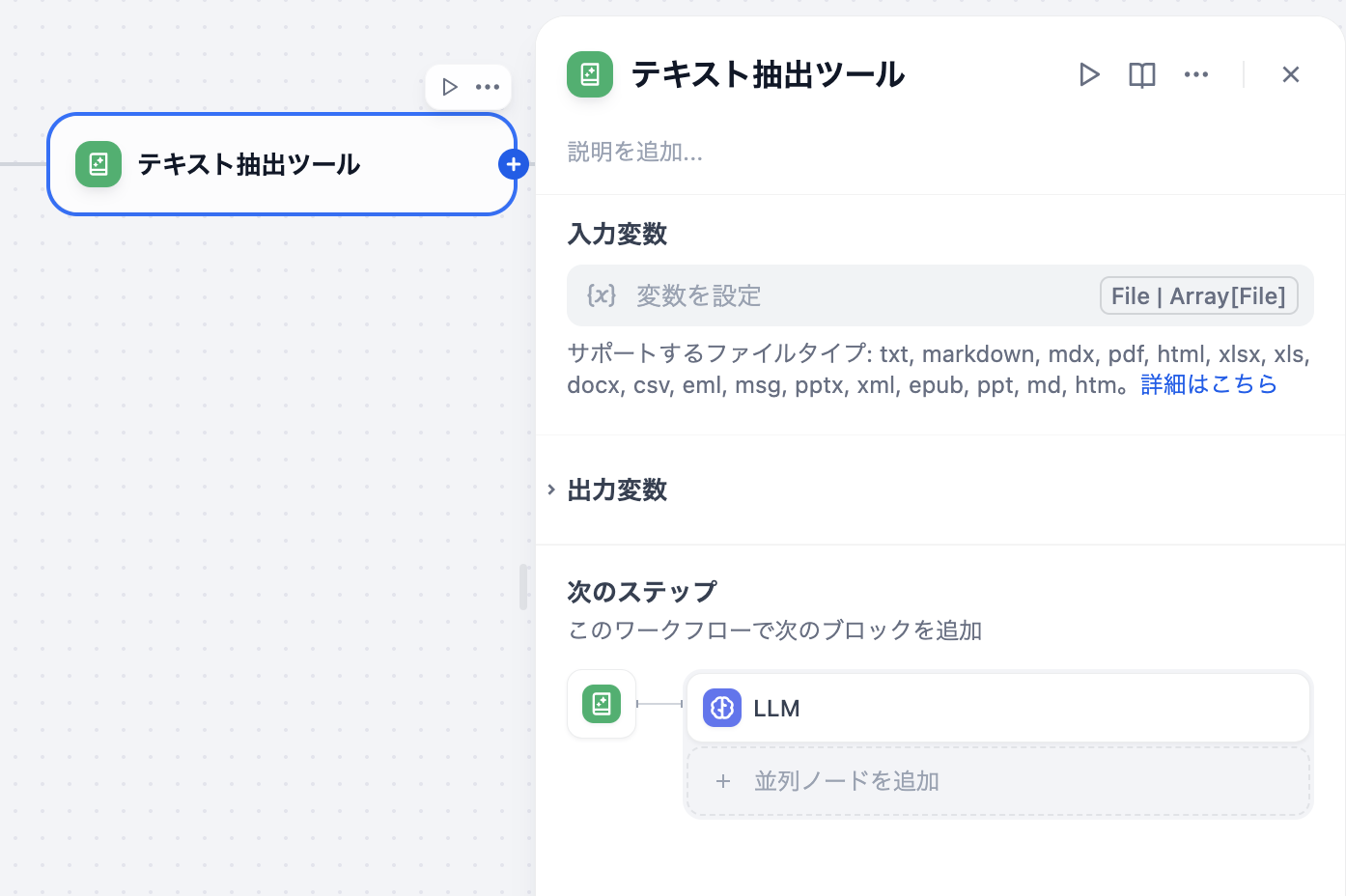
テキトー教師まずステップ1として、Startノード(開始ノード)でファイル変数を追加します。スタートノードの設定で「ファイル」型の変数を追加して、例えば
pdfという名前をつけるんですが、この変数名は後のノードで参照するので覚えておく必要があります。室谷ステップ2はテキスト抽出ツールノードの追加です。ノード一覧から「テキスト抽出ツール」を選んでワークフローに追加して、入力変数のところで先ほどStartノードで作った
これだけです。
pdf変数を選択します。これだけです。
テキトー教師ステップ3でLLMノードを追加します。ここでシステムプロンプトか入力変数の中に、テキスト抽出ツールノードの出力変数(
LLMはこの
text)を選択して渡してあげます。LLMはこの
text変数にアクセスすることで、アップロードされたPDFの内容を「読んだ」状態になります。室谷ステップ4は終了ノードの設定です。LLMの出力を終了ノードに渡して完成。
ワークフロー全体の流れは「開始 → テキスト抽出ツール → LLM → 終了」という4ノード構成が最もシンプルなパターンですね。
ワークフロー全体の流れは「開始 → テキスト抽出ツール → LLM → 終了」という4ノード構成が最もシンプルなパターンですね。
テキトー教師公式ドキュメントでもChatPDFをサンプルとして紹介しています。受講生さんに「まずこのテンプレートで手を動かしてみて」と言うと、ほとんどの人は30分以内に動くものを作れます。
Difyの良いところはノーコードで組めるので、プログラミング経験がなくても大丈夫なんですよね。
Difyの良いところはノーコードで組めるので、プログラミング経験がなくても大丈夫なんですよね。
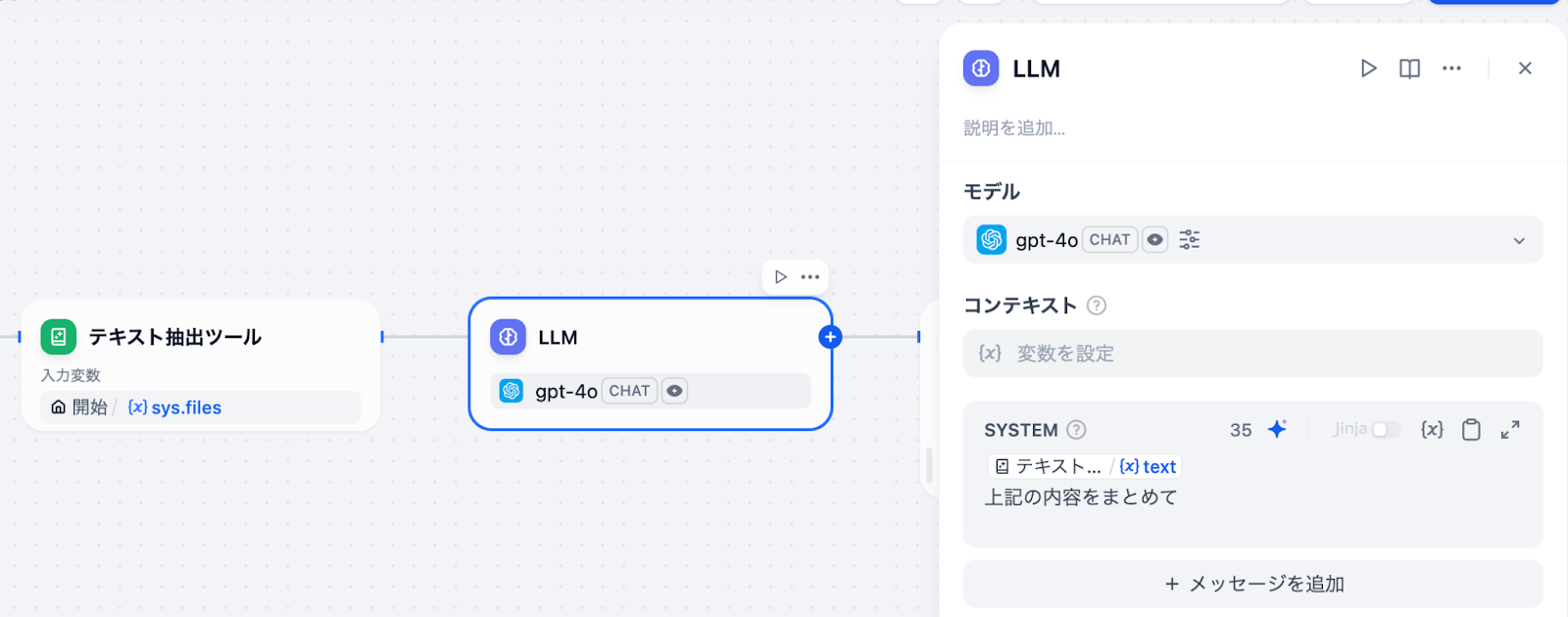
ファイルアップロード機能の有効化
室谷見落としがちなポイントなんですが、チャットフローでファイルをユーザーにアップロードさせたい場合は、アプリの公開設定で「ファイルアップロード」機能を有効にする必要があります。ワークフローを組んだだけではユーザー側からファイルを送れないんですよね。
テキトー教師これ、コミュニティのメンバーさんがよくハマるポイントで、「ワークフローは完成したけどチャット画面にファイルアップロードボタンが出ない」という相談が来るんですよね(笑)。「機能」タブを開いて「ファイルアップロード」をONにするだけで解決です。
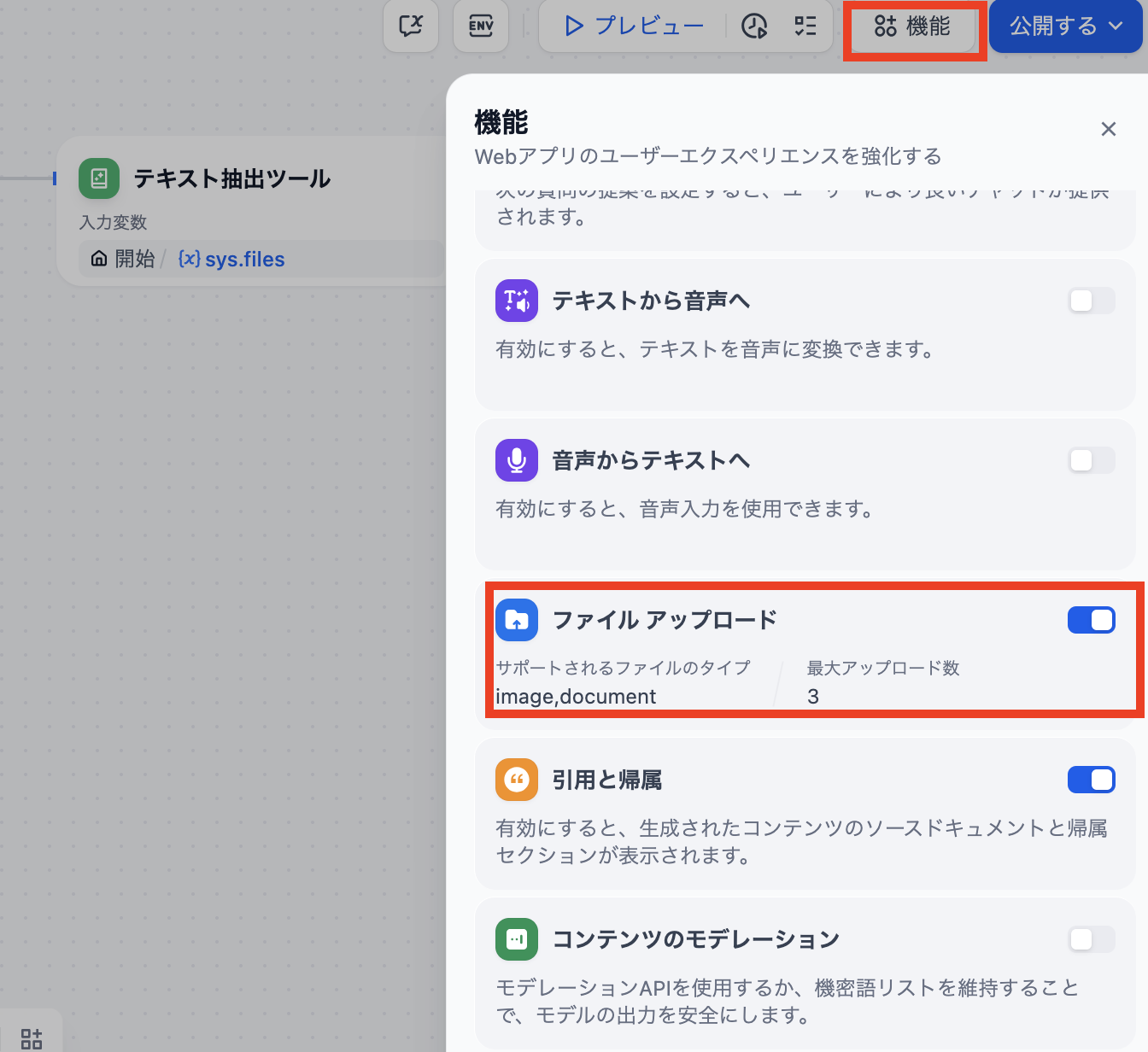
室谷ファイルアップロード機能の設定では、サポートするファイルタイプと最大アップロード数を設定できます。例えば「PDFだけ受け付ける」「最大3ファイルまで」といった制限をUIレベルで設定できる点は便利ですよね。
テキトー教師セキュリティ面でも重要で、本番運用するときは受け入れるファイルタイプを絞っておくのがベストプラクティスですね。「image,document」と両方設定することもできますが、テキスト抽出が目的であればdocumentだけにしておく方が意図が明確になります。
Dify ワークフロー テキスト抽出の実践パターン
室谷基本的な設定を覚えたら、次は実際のビジネス活用パターンを見ていきましょう。MYUUUでもDifyを使ってドキュメント処理を自動化しているんですが、いくつか代表的なパターンがあります。
テキトー教師大きく分けると「ChatPDF系(ファイルと会話する)」「一括処理系(複数ドキュメントをバッチ処理)」「変換・抽出系(構造化データとして取り出す)」の3パターンですね。それぞれ使うノードの組み合わせが変わってきます。
ChatPDF・ChatWord:ファイルと対話するワークフロー
室谷最もベーシックなパターンがChatPDFです。さっき説明した4ノード構成で、ユーザーがPDFをアップロードして質問すると、AIが内容に基づいて回答してくれます。
マニュアルや仕様書のQ&Aボットとして使えますし、MYUUUでも社内の規程集をChatボット化して使っています。
マニュアルや仕様書のQ&Aボットとして使えますし、MYUUUでも社内の規程集をChatボット化して使っています。
テキトー教師WordファイルやMarkdownも同じ構成で処理できるので、ChatWordやドキュメントレビューツールとしても応用できます。例えば契約書をアップロードして「このドキュメントに含まれるリスク条項を列挙して」と聞かせるワークフローは、法務部門での活用事例としてよく紹介しています。
室谷実際に僕の著書「お金を使わず、AIを働かせる『Dify』活用」でも具体的なワークフロー事例を紹介しているんですが、ファイル処理の基本はこのChatPDFパターンが土台になっています。ここを理解していると他の応用が一気に楽になりますよね・・・
Dify テキスト抽出 Excel・CSV:表データの活用
テキトー教師dify テキスト抽出 ExcelやDify テキスト抽出 CSVの処理は少し使い方が変わってきます。テキスト抽出ツールはExcelからテキストを取り出すことはできますが、表の構造はそのまま取り出せるわけではなくて、基本的には「テキストとして書き出した内容」になります。
室谷そうなんですよね。Excelを読み込ませてLLMが処理するときの精度は、データの量と構造に依存します。
100行程度の小さなシートならLLMが十分処理できますが、大量データの場合は「リスト処理ノード」と組み合わせて分割処理する方がいいです・・・
100行程度の小さなシートならLLMが十分処理できますが、大量データの場合は「リスト処理ノード」と組み合わせて分割処理する方がいいです・・・
テキトー教師実践的なアドバイスとして、CSVで分析系のタスクをするなら「テキスト抽出 → LLM(データ整理・構造化)→ コード実行ノード(計算)」のパターンが使いやすいですね。LLMでCSVの内容を理解させて、数値計算はPythonコードに任せる、という役割分担です。
室谷そのパターンは実際に使うと精度が安定するんですよね。LLMに計算させようとすると精度が落ちることがあるので、計算はコード実行ノードに任せるというのはMYUUUのワークフロー構築でも徹底しているルールです。
Dify テキスト抽出 LLM:パラメータ抽出パターン
テキトー教師「テキスト抽出 + LLM(パラメータ抽出ノード)」の組み合わせも非常に有用なパターンです。例えば請求書PDFからベンダー名、金額、日付を自動で取り出して構造化データとして出力するとか。
室谷これ、企業の業務自動化でめちゃくちゃ使われているパターンです。複数の請求書をまとめてアップロードして、各書類から同じフォーマットで情報を抜き出してCSVにまとめる、みたいなことができるんですよね。
人間がExcelに手で転記していた作業を完全に自動化できます。
人間がExcelに手で転記していた作業を完全に自動化できます。
テキトー教師dify テキスト抽出ノードと「パラメータ抽出ノード」の違いも整理しておくといいですね。テキスト抽出ツールは「ファイルの内容をテキストに変換する」という前処理担当で、パラメータ抽出はLLMを使って「テキストから特定の情報を構造化して取り出す」という処理担当です。
この2つを組み合わせることで強力なデータパイプラインが作れます。
この2つを組み合わせることで強力なデータパイプラインが作れます。
Dify テキスト抽出 文字化けの原因と対処法
室谷実際に使っていると出てくる問題として文字化けがあります。「PDFを読み込ませたけど出力がおかしい」という相談は結構多いですよね。
テキトー教師dify テキスト抽出 文字化けは本当によくある相談で、大きく分けると原因は2種類あります。「そもそもPDFにテキストデータが入っていない(画像PDF)」と「テキストデータはあるが文字コードの問題で化ける」です。
それぞれ対処法が違います。
それぞれ対処法が違います。
画像PDF(スキャンPDF)の場合:dify テキスト抽出 PDFが動かない原因
室谷スキャンした書類をPDFにしたもの、いわゆる「画像PDF」は、PDFファイルの中に実際には画像データしか入っていないんです。だからテキスト抽出ツールを使っても文字を取り出せません。
これはDifyの問題ではなくて、そもそもOCR処理が必要なケースです。
これはDifyの問題ではなくて、そもそもOCR処理が必要なケースです。
テキトー教師解決方法としては2つあります。一つは、PDF作成時にテキストレイヤーを付けること(Acrobatなどで事前にOCR処理する)。
もう一つは、DifyのLLMノードのビジョン機能を使って画像として読み込ませる方法です。GPT-4oやClaude 3.x系のビジョン対応モデルを使えば、画像PDFのページを画像として渡して文字を読み取ることができます。
もう一つは、DifyのLLMノードのビジョン機能を使って画像として読み込ませる方法です。GPT-4oやClaude 3.x系のビジョン対応モデルを使えば、画像PDFのページを画像として渡して文字を読み取ることができます。
室谷ただしビジョン機能でのPDF処理はコストが高いので、大量のページがある場合はコストと精度のトレードオフを考える必要がありますよね・・・ページ数が少ない場合はビジョン、大量ページならまず外部でOCR処理してからDifyに渡す、という使い分けが現実的です。
テキストPDFでも文字化けする場合
テキトー教師テキストデータは入っているのに文字化けする場合、日本語フォントの埋め込み設定が原因なことがあります。PDFが特殊なフォントエンコーディングを使っていると、テキスト抽出で文字が正しく認識されないんですよね。
室谷この場合の対処法としては、まずPDFを別のツール(Adobe Acrobatや各種コンバーター)で再度エクスポートしてテキスト埋め込みをやり直す方法があります。あとはDifyのLLMビジョン機能を使う手もあります。
ソースのPDFの作り方によるところが大きいので、「このPDFだけ化ける」という場合はソース側の問題を疑うといいです。
ソースのPDFの作り方によるところが大きいので、「このPDFだけ化ける」という場合はソース側の問題を疑うといいです。
テキトー教師実際のところ、主要な市販PDFツールで作ったPDFや、OfficeからエクスポートしたPDFは文字化けほとんどしないんですよ。問題が出やすいのは古い業務システムのPDF出力機能だったり、スキャナー直出しのPDFだったりします。
「最初に小さいテストファイルで動作確認する」のが一番の予防策です。
「最初に小さいテストファイルで動作確認する」のが一番の予防策です。
Dify テキスト抽出 画像:ビジョン機能との使い分け
室谷先ほど少し触れましたが、画像ファイルの処理については改めて整理しましょう。テキスト抽出ツールは画像ファイルを処理できないので、画像の内容をAIに読み取らせたい場合は別のアプローチが必要です。
テキトー教師Difyで画像のテキストを読み取る方法は主に2つあります。整理するとこうなります。
| 方法 | 対象 | 特徴 |
|---|---|---|
| テキスト抽出ツール | PDF, Word, Excel等のドキュメント | 高速・低コスト |
| LLMビジョン機能 | 画像ファイル、画像PDF | 柔軟だがコストが高め |
室谷ビジョン機能を使う場合は、スタートノードで画像変数を受け取って、LLMノードの入力に直接画像変数を渡します。「テキストに変換する」ステップは不要で、LLMが画像を直接認識できます。
テキトー教師注意点として、Difyで使うLLMモデルがビジョン対応モデルでないといけません。GPT-4o、Claude Sonnet、Gemini Pro等のビジョン対応モデルを選択してください。
モデルの選択を間違えると「このモデルは画像を処理できません」というエラーが出ます。LLMノードを開いたときに使えるモデルが表示されるので、そこでビジョン対応モデルを選んでください。
モデルの選択を間違えると「このモデルは画像を処理できません」というエラーが出ます。LLMノードを開いたときに使えるモデルが表示されるので、そこでビジョン対応モデルを選んでください。
室谷テキスト抽出ツールとビジョン機能、どっちを使えばいいかというと、ファイルタイプで判断するのが一番シンプルです。Word・PDF(テキスト埋め込みあり)・Excel・CSVならテキスト抽出ツール。
JPG・PNG・スキャンPDFならLLMビジョン機能。これだけ覚えておけばほとんどのケースに対応できます。
JPG・PNG・スキャンPDFならLLMビジョン機能。これだけ覚えておけばほとんどのケースに対応できます。
Dify テキスト抽出ツールと他のツールとの比較
テキトー教師Difyのテキスト抽出ツールと他のツールの違いもよく聞かれるので整理しておきましょう。「ChatPDFというサービスがあるけどDifyと何が違うの?」という質問が講座でよく出ます。
室谷大きく分けると「専用SaaS(ChatPDF等)」「OCRツール」「Difyのようなワークフロー型」の3種類がありますね。それぞれ得意な場面が違います。
ChatPDFなどの専用SaaSとの違い
室谷ChatPDFは「PDFと会話する」専用ツールで、使いやすさはピカイチです。でもそれしかできない。
Difyの強みはテキスト抽出した後の処理を自分でカスタマイズできることで、「PDFを読んで、特定フォーマットでJSON出力して、スプレッドシートに自動記入する」みたいなことが全部一つのワークフローで実現できます。
Difyの強みはテキスト抽出した後の処理を自分でカスタマイズできることで、「PDFを読んで、特定フォーマットでJSON出力して、スプレッドシートに自動記入する」みたいなことが全部一つのワークフローで実現できます。
テキトー教師あと企業利用を考えると、専用SaaSにドキュメントをアップロードすることへのセキュリティ懸念があります。Difyはセルフホストできるので、機密文書をオンプレミス環境で処理するというユースケースにも対応できます。
MYUUUのお客様でもセキュリティ要件でセルフホストを選択するケースが増えていますね。
MYUUUのお客様でもセキュリティ要件でセルフホストを選択するケースが増えていますね。
OCR系ツールとの違い
テキトー教師OCRツール(Adobe Acrobat、Google Document AI等)との比較ですが、これはそもそも役割が違います。OCRは「画像を文字データに変換する」もので、テキスト抽出の前処理担当です。
Difyのテキスト抽出ツールはすでにテキストデータになっているファイルからテキストを取り出す後処理担当、という違いがあります。
Difyのテキスト抽出ツールはすでにテキストデータになっているファイルからテキストを取り出す後処理担当、という違いがあります。
室谷なので実際の使い方としては「OCRでテキスト化 → Difyに渡してLLMで処理」という組み合わせが現実的なケースもあります。特にスキャンした書類を大量に処理する業務では、前段にOCRパイプラインを用意してDifyに送るアーキテクチャを取るんですよね・・・
テキトー教師それぞれのツールの得意分野を理解して組み合わせるのが、実務でのDify活用の勘どころですね。「Difyで全部やろう」と考えるより、「Difyが得意な部分にはDifyを使い、苦手な部分は専用ツールを組み合わせる」という発想の方が上手くいきます。
Dify テキスト抽出ツールの活用事例
室谷具体的な活用事例もいくつか紹介しましょう。MYUUUで実際に構築してきたものや、コンサルティングで提案してきた事例をベースに話します。
テキトー教師事例を聞くと「自分の仕事にも使えそう」とイメージが湧くので、受講生さんにも具体的な事例紹介から入るんですよね。抽象的な説明より圧倒的に理解が早い。
事例1:契約書・見積書の自動審査ワークフロー
室谷製造業のお客様で実際に構築したパターンです。取引先からPDFで届く見積書を自動的に読み込んで、自社の承認基準に沿ってチェックするワークフローを作りました。
「金額・条件・支払い期日」を自動で抽出して、基準外の項目があればアラートを出す仕組みです。
「金額・条件・支払い期日」を自動で抽出して、基準外の項目があればアラートを出す仕組みです。
テキトー教師これ、テキスト抽出ツールでPDFからテキスト化して、パラメータ抽出ノードで各項目を構造化して、条件分岐ノードで判定するパターンですね。最後にHTTPリクエストノードでSlackに通知を飛ばす。
このワークフローのパターン、講座でもかなり人気があります。
このワークフローのパターン、講座でもかなり人気があります。
事例2:研究論文の要約・データベース化
室谷以前Xでも投稿したんですが、Difyで論文調査を自動化できます。PDFをアップロードすると、要旨・手法・結論を構造化して取り出して、Notionのデータベースに自動追加するワークフローです。
テキトー教師研究者やアナリストの方々に刺さるユースケースですよね。月に何十本も論文を読まないといけない方が「週の論文確認時間が半分以下になった」という声をいただいたことがあります。
テキスト抽出ツールがあってこそのワークフローです。
テキスト抽出ツールがあってこそのワークフローです。
事例3:マニュアル・FAQのチャットボット化
室谷これが一番多いパターンかもしれません。製品マニュアルや社内規程、FAQドキュメントをPDFやWordでアップロードして、チャット形式で質問に答えるボットを作る。
RAGを使う方法もありますが、ドキュメントが1〜数本程度ならテキスト抽出ツールで全文をLLMのコンテキストに入れる方がシンプルで精度も出ることがあります。
RAGを使う方法もありますが、ドキュメントが1〜数本程度ならテキスト抽出ツールで全文をLLMのコンテキストに入れる方がシンプルで精度も出ることがあります。
テキトー教師ドキュメントの規模によって使い分けるのが大事ですね。「少数のドキュメントを深く理解させたい」ならテキスト抽出ツール、「大量のドキュメントから関連情報を検索させたい」ならナレッジベース(RAG)、という使い分けが基本です。
室谷テキスト抽出ツールはドキュメント全文をコンテキストに入れるので、長いPDFだとLLMのコンテキストウィンドウの制約に当たることがあります。100ページ超えるような大量のドキュメントはRAGの方が向いていますね。
Dify テキスト抽出ツール よくある質問(FAQ)
テキトー教師ここでよく出る質問をまとめておきましょう。講座で繰り返し聞かれる内容です。
Q1: テキスト抽出ツールとドキュメント抽出ノードは同じもの?
室谷はい、同じものです。英語ドキュメントでは「Document Extractor」と呼ばれています。
日本語UIでは「テキスト抽出ツール」と表示されます。「テキスト抽出ツールノード」「dify テキスト抽出ノード」「ドキュメントエクストラクター」すべて同じノードを指しています。
日本語UIでは「テキスト抽出ツール」と表示されます。「テキスト抽出ツールノード」「dify テキスト抽出ノード」「ドキュメントエクストラクター」すべて同じノードを指しています。
Q2: 複数ファイルを同時に処理できる?
テキトー教師できます。スタートノードで
その後、リスト処理ノードで各ファイルのテキストを個別に処理できます。
Array[File]型の変数を受け取るように設定して、テキスト抽出ツールに渡すと、複数ファイルのテキストがarray[string]として出力されます。その後、リスト処理ノードで各ファイルのテキストを個別に処理できます。
室谷ただし複数ファイルを一気に処理する場合、LLMに渡す情報量が大きくなりすぎることがあるので、大量ファイルはイテレーション(反復処理)ノードと組み合わせて1ファイルずつ処理する方がコントロールしやすいです。
Q3: テキスト抽出の精度を上げる方法は?
テキトー教師テキスト抽出自体の精度はファイルの品質に依存するので、ソースファイルを改善するのが根本解決です。PDFの場合「テキスト選択できるか確認する」のが最初のチェックです。
テキスト選択できないPDFは画像PDFなのでOCRが必要です。
テキスト選択できないPDFは画像PDFなのでOCRが必要です。
室谷あとはファイルのエンコーディング。日本語テキストの場合、UTF-8で保存されているかどうかで読み取り精度が変わることがあります。
特にCSVファイルは文字コードの設定に注意が必要ですね。
特にCSVファイルは文字コードの設定に注意が必要ですね。
Q4: Difyのバージョンによって機能が違う?
テキトー教師テキスト抽出ツールノードは比較的古くからあるノードで、現在のDifyでも基本的な動作は変わっていません。ただしサポートファイルタイプは版によって追加・変更されることがあるので、最新のを確認するのが確実です。
室谷Difyは更新が早いので、細かい仕様はバージョンに依存することがあります。最新情報は常にGitHubのを確認するのがベストですね。
まとめ:Difyテキスト抽出ツールを使いこなすポイント
室谷まとめとして重要なポイントを整理しましょう。テキスト抽出ツールノードはDifyでファイル処理ワークフローを作る上で必須のノードです。
「ファイルをアップしたのにLLMが読んでくれない」という問題の99%は、このノードを挟んでいないことが原因です。
「ファイルをアップしたのにLLMが読んでくれない」という問題の99%は、このノードを挟んでいないことが原因です。
テキトー教師覚えておくべきポイントをまとめるとこうなります。
- テキスト抽出ツールは「ドキュメントファイル → テキスト変換」専用。画像は処理不可
- 対応形式: PDF, Word, Excel, CSV, Markdown, HTML, EPUBなど
- 出力変数名は
text(固定)で、後続のLLMノードにこれを渡す - 画像PDFや文字化けはソースファイルの問題。LLMビジョン機能で代替可能
- チャットフローでユーザーにファイルアップロードさせるには「機能」タブで有効化が必要
- 少量ドキュメントはテキスト抽出ツール、大量ドキュメントはRAG(ナレッジベース)が向く
室谷Difyのテキスト抽出ツールを使いこなすと、「ドキュメントと会話する」「書類を自動処理する」といったワークフローが短時間で構築できます。MYUUUでも業務自動化の基礎として非常に多くのワークフローでこのノードを活用しています。
ぜひ試してみてください。
ぜひ試してみてください。
テキトー教師.AI(ドットエーアイ)では、このようなDifyの実践的な使い方を体系的に学べる講座を提供しています。「理論はわかったけど実際に手を動かして作ってみたい」という方は、ぜひコミュニティに参加してみてください。
ワークフロー設計から実運用まで、段階的に学べる環境が整っています。
ワークフロー設計から実運用まで、段階的に学べる環境が整っています。