
Difyのナレッジ機能とは?RAGで社内資料をAIに読ませる完全ガイド
 室谷
室谷今回はDifyのナレッジ機能を深掘りしていきましょう。これ、.AI(ドットエーアイ)コミュニティでも「ナレッジが使いこなせない」「RAGって難しそう」って声が本当に多いんですよね・・・
 テキトー教師
テキトー教師ですよね。講座でも「ナレッジをチャットボットに繋いだけど、ちゃんと答えてくれない」って悩む方が続出してます。
設定の順番を間違えると、せっかくアップロードしたPDFを全然参照してくれないんですよ。
設定の順番を間違えると、せっかくアップロードしたPDFを全然参照してくれないんですよ。
室谷MYUUUでも最初はそれで苦労したんです。社内のマニュアルをDifyに食わせようとして、チャンク設定を適当にやったら全然精度が出なくて。
正直「Difyのナレッジって使えない」と思いかけましたよ(笑)
正直「Difyのナレッジって使えない」と思いかけましたよ(笑)
テキトー教師でも正しく設定すればめちゃくちゃ強力なんですよね。今回はナレッジ機能に絞って、基礎から実践まで徹底的にやっていきます。
室谷まず「ナレッジって何をしてくれる機能なのか」というところから確認しましょう。これを理解すると、チャンクの設定方法やインデックスの選び方も自然と腑に落ちてくるので。
ナレッジ機能とRAGの仕組み
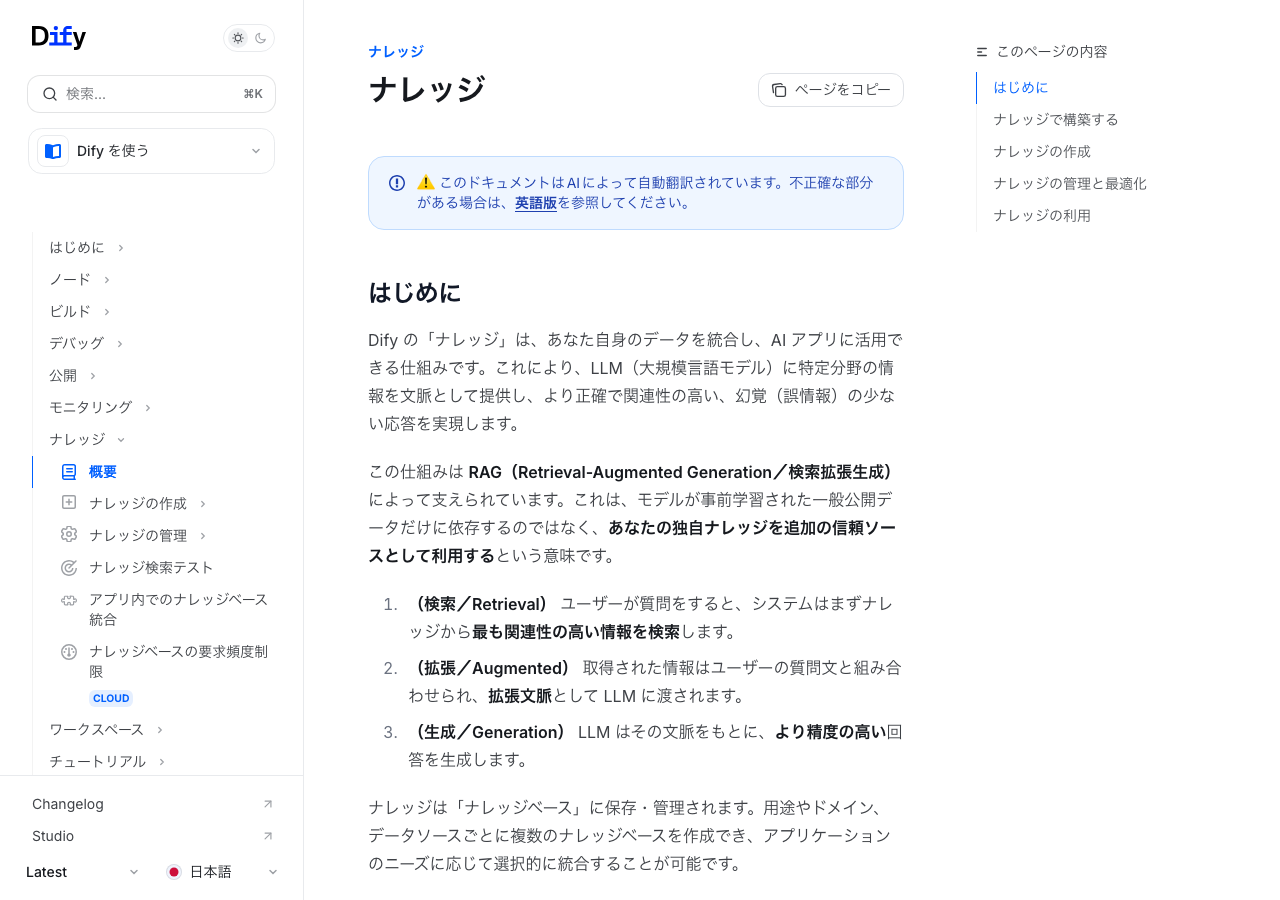
テキトー教師Difyのナレッジ機能というのは、ひと言で言うと「自分のデータをAIに渡す仕組み」です。通常のLLM(大規模言語モデル)は学習データの範囲でしか回答できませんが、ナレッジ機能を使えば自社のPDFや社内マニュアルを参照した回答が返せるようになります。
室谷これがRAG(Retrieval-Augmented Generation)と呼ばれる技術ですね。「検索して取ってきた情報を使って回答を生成する」という仕組みです。
RAGという言葉は知ってるけど具体的に何をしてるか、というのをDifyは視覚的にわかりやすく実装してくれてる。
RAGという言葉は知ってるけど具体的に何をしてるか、というのをDifyは視覚的にわかりやすく実装してくれてる。
テキトー教師技術的に整理すると、RAGは3つのフェーズで動いています。
- Retrieval(検索): ユーザーが質問すると、まずナレッジベースから最も関連性の高いチャンク(情報のかけら)を検索する
- Augmented(拡張): 取得したチャンクをユーザーの質問と組み合わせ、LLMへのプロンプトを拡張する
- Generation(生成): 拡張された文脈をもとにLLMが回答を生成する
室谷この仕組みで何がよくなるかというと、LLMが「知らないはずの情報」について正確に答えられるようになるんですよ。例えば、2026年に改訂した自社の就業規則を質問しても、学習データにはないから通常のLLMだと答えられない。
でもナレッジに入れておけばちゃんと答えてくれる。
でもナレッジに入れておけばちゃんと答えてくれる。
テキトー教師しかも「でたらめな情報をそれっぽく言う」ハルシネーションも減るんですよね。根拠となる文書が手元にある状態で回答するので。
室谷ユースケースとしては、Difyの公式ドキュメントにも書いてありますが、カスタマーサポートBot、社内ナレッジポータル、コンテンツ生成ツール、リサーチ・分析アプリ、この4つが主なところです。MYUUUでも社内FAQをナレッジに入れてチャットボット化しています。
テキトー教師講座の受講生さんだと「会社のPDF規程集をAIに読ませたい」という用途が一番多いですね。何百ページもある規程集を全部読んで回答できるAIアシスタントを作りたい、というケースです。
ナレッジベースの作成方法:ステップバイステップ
室谷では実際の作り方に入りましょう。Difyのダッシュボードで「ナレッジ」タブをクリックするところから始めます。
テキトー教師画面の上部ナビに「ナレッジ」というメニューがありますね。クリックすると既存のナレッジベース一覧が表示されて、右上に「ナレッジベースを作成」ボタンがあります。
室谷作成ボタンを押すと、データソースの選択画面が出てきます。ここで3つの選択肢があって、これが最初の分岐点ですね。
| データソース | 説明 | 用途 |
|---|---|---|
| ローカルファイルをアップロード | PDF、TXT、Markdown等をアップロード | 社内マニュアル、規程集、技術文書 |
| Notionデータをインポート | Notionのページを同期 | Wiki、ドキュメント管理 |
| Webサイトからデータをインポート | 指定URLのWebページを取込 | 公式サイト、FAQページ |
テキトー教師「空のナレッジベースを作成」という4つ目の選択肢もあって、後からデータを追加していく場合はこちらを使います。
室谷対応ファイル形式も把握しておくといいですね。PDFだけじゃなくて、TXT、Markdown、HTML、DOCXも使えます。
業務でよく使う資料の形式はだいたいカバーされてますね。
業務でよく使う資料の形式はだいたいカバーされてますね。
テキトー教師注意点として、ファイルアップロードには容量制限があります。大きなPDFは分割してアップロードするのが安全です。
チャンク設定:精度を左右する最重要パラメーター
室谷データを選んだら次に「チャンク設定」が出てきます。ここが一番重要で、しかも一番つまずくところです。
テキトー教師チャンクというのは「長い文書をどのくらいの大きさの塊に分割するか」の設定です。RAGは文書全体を一度に検索するんじゃなくて、小さな単位(チャンク)に分割してから、質問に近いチャンクだけを取ってくる仕組みです。
室谷分割する意味は何かというと、例えば500ページのPDFを丸ごとLLMに渡すのはコスト的にも処理的にも無理なんですよね。だから「質問に関係ある部分だけ」を切り出して使う。
テキトー教師チャンク設定には主にこれらのパラメーターがあります。
- チャンク識別子: どの区切り文字でテキストを分割するか(デフォルトは段落区切り)
- 最大チャンク長: 1つのチャンクの最大トークン数(デフォルト500程度)
- チャンクのオーバーラップ: 前のチャンクの末尾を次のチャンクの先頭に重ねる量
- テキストの前処理ルール: 余分なスペースやURLを除去するなどのクリーニング設定
室谷オーバーラップって地味に大事なんですよ。チャンクの境界でちょうど重要な文章が切れるケースがあって、オーバーラップを設定しておくと文脈が途切れにくくなる。
テキトー教師最適な設定値は文書の性質によって違うので、「プレビュー」機能を使って実際にどう分割されるか確認しながら調整するのがおすすめです。Difyはチャンクのプレビューができるので、設定してすぐ確認できる。
室谷MYUUUでの経験だと、マニュアル系のPDFは最大チャンク長500〜1000、オーバーラップ50〜100くらいが精度よかったですね。長文の論文やレポートはもう少し大きめにした方がいい場合もあります。
テキトー教師「プレビューしたらチャンクが途中で意味不明なところで切れてた」というのはよくある失敗パターンですよね。その場合はチャンク識別子を調整するか、最大チャンク長を増やす方向で対処します。
インデックス方法の選択:高品質か経済的か
室谷チャンク設定の次が「インデックス方法」の選択です。「高品質」と「経済的」の2択です。
テキトー教師高品質モードは埋め込みモデルを使ってドキュメント全体をベクトル化します。意味的な検索ができるので、言い換えやあいまいな質問にも強い。
精度重視の用途には必ずこちらを選びます。
精度重視の用途には必ずこちらを選びます。
室谷経済的モードは各チャンクからキーワードを抽出する方式で、ベクトル化はしません。コストを抑えたい場合や、プロトタイプをサクッと試したい場合向けですね。
ただし精度は落ちます。
ただし精度は落ちます。
テキトー教師本番で実際に使うシステムなら、高品質モード一択だと思います。コストの差は実はそんなに大きくないので、ここでケチると精度で痛い目を見ます(笑)
室谷あと、高品質モードを選ぶと「埋め込みモデル」も選択できます。OpenAIやCohere、Mistralなど複数のモデルが使えますが、後から埋め込みモデルを変えるとインデックスを作り直す必要があるので、最初に慎重に決めるのがポイントです。
テキトー教師日本語を扱うなら日本語の精度が高いモデルを選ぶと検索精度が上がります。
検索設定のカスタマイズ
室谷インデックス方法を決めたら次が「検索設定」です。ここで「ベクトル検索」「全文検索」「ハイブリッド検索」の3つから選びます。
これが地味に重要なんですよ。
これが地味に重要なんですよ。
テキトー教師3つの違いを比べると、こうなります。
| 検索方法 | 仕組み | 強み | 弱み |
|---|---|---|---|
| ベクトル検索 | 意味的な類似度でマッチング | 言い換え・あいまい表現に強い | 完全一致が弱い場合も |
| 全文検索 | キーワードの完全一致でマッチング | 正確なキーワード検索に強い | 意味が似てても表現が違うと見つからない |
| ハイブリッド検索 | ベクトルと全文を組み合わせてRerankモデルで再評価 | バランスが良く最も高精度 | 追加コストがかかる |
室谷実践では「ハイブリッド検索」が最強ですね。意味的な類似度とキーワードマッチの両方をカバーして、さらにRerankモデルが最終的な順位付けをしてくれる。
テキトー教師ただしRerankを使うにはCohereやJina AIなどのRerankモデルのAPIキーが必要です。DifyのモデルプロバイダーページでAPIキーを追加すれば使えるようになります。
室谷コストをかけたくない場合は「重み設定」という選択肢もあって、セマンティック(意味的)とキーワードの重み比率を自分でカスタマイズできます。外部のRerankモデルなしで使えるので、まずはこれで試してみるのもいいですね。
テキトー教師重みの調整は「どういう質問が来ることが多いか」で決めます。正確なキーワードで検索する用途ならキーワード寄り、あいまいな言い換えが多い用途はセマンティック寄りに。
室谷TopKとスコアの閾値も設定できます。TopKは「検索結果の何件をLLMに渡すか」、スコア閾値は「類似度が一定以上のものだけを使う」という設定です。
TopKを増やしすぎるとコンテキストが膨れ上がるので、3〜5くらいが現実的なラインですね。
TopKを増やしすぎるとコンテキストが膨れ上がるので、3〜5くらいが現実的なラインですね。
アプリにナレッジベースを統合する方法
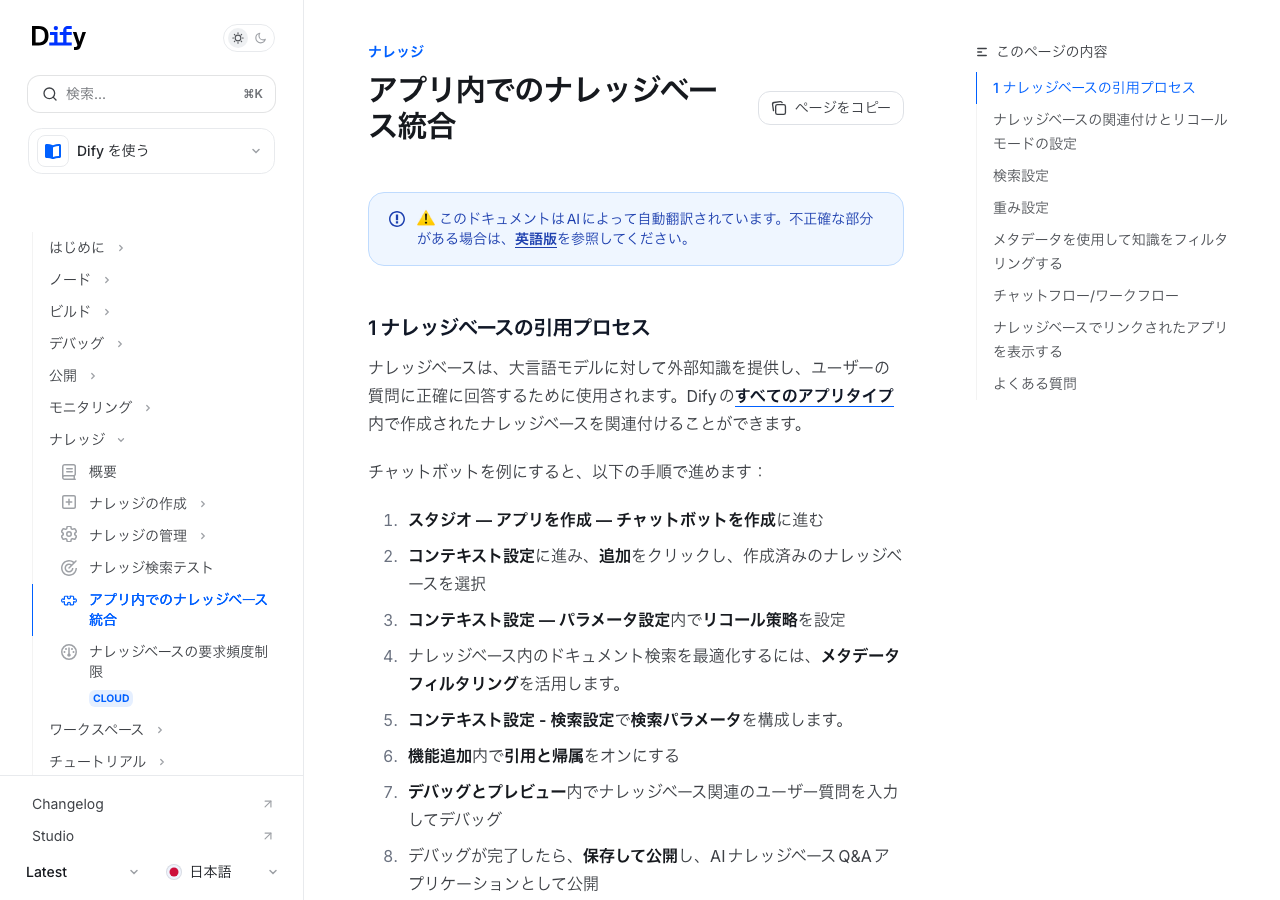
テキトー教師ナレッジベースを作ったら、次はアプリに繋ぎましょう。チャットボットを例に説明します。
室谷Difyのスタジオから「アプリを作成」でチャットボットを選びます。オーケストレーション画面が開いたら、左ペインの「コンテキスト」セクションを確認してください。
「追加」ボタンから、さっき作ったナレッジベースを選べます。
「追加」ボタンから、さっき作ったナレッジベースを選べます。
テキトー教師ここで複数のナレッジベースを選ぶこともできるんですが、複数選ぶと「リコールモード」の設定が必要になります。
室谷リコールモードの設定は「コンテキスト → パラメータ設定 → リコール設定」から入れますね。選択肢は「単一リコール」と「複数リコール」の2つです。
テキトー教師複数のナレッジベースを使う場合は「複数リコール」を選んで、さらにRerankモデルを設定するのが推奨です。複数のナレッジから最適な情報を選び出してくれます。
室谷ナレッジを繋いだら、「機能追加」から「引用と帰属」をオンにすることもできます。これをオンにすると、回答の末尾にどのドキュメントのどの部分を参照したかが表示されます。
テキトー教師「引用と帰属」は信頼性を上げる意味でも大事ですよね。「この情報はページ5の第2段落から」みたいな形で出典が示されるので、ユーザーが元文書を確認できる。
室谷特に社内利用のツールだと「根拠はどこ?」というのが必ず聞かれますからね。法規制対応とか、コンプライアンス関連の文書をナレッジにする場合は必ずオンにした方がいいです。
メタデータフィルタリングで検索精度を高める
テキトー教師最近Difyに追加された機能で、メタデータフィルタリングというのがあります。これがかなり強力なんですよ。
室谷ドキュメントにタグやカテゴリなどのメタデータを付けておくと、検索時にそのメタデータで絞り込めるんですよね。例えば「部署=人事」「年度=2026」みたいなタグを付けておくと、「人事部門の2026年の規程だけ検索して」という絞り込みができる。
テキトー教師フィルタリングモードは「無効」「自動」「手動」の3つです。「自動」にすると、ユーザーの質問の内容からシステムが自動でフィルタ条件を判断します。
「手動」だと自分でルールを設定できる。
「手動」だと自分でルールを設定できる。
室谷チャットフロー/ワークフローの場合は、ナレッジ検索ノードの設定の中にメタデータフィルタリングの設定があります。変数を使って動的にフィルタ条件を変えることもできるので、ユーザーの入力に応じて検索対象のドキュメントを絞り込むみたいなことが可能です。
テキトー教師大規模なナレッジベースを扱う場合は特に効いてくる機能ですね。100個のドキュメントから全部検索するより、関連するカテゴリに絞ってから検索する方が精度も速度も上がります。
ナレッジ検索テストの活用方法
室谷ナレッジベースを作ったら、必ず「検索テスト」を使って精度を確認してください。これ、スキップしてる人が多いんですが、超重要なんですよ。
テキトー教師ナレッジベースの左サイドバーに「検索テスト」という項目があります。ここでユーザーが実際に投げそうな質問を入力すると、どのチャンクがヒットするか、スコアはどれくらいかが確認できます。
室谷スコアが高いチャンクが上に出てくるはずで、実際にユーザーが質問したときに返ってくる情報の候補がリアルタイムで見えるわけです。「あれ、全然違うチャンクがヒットしてる」というのをここで発見できる。
テキトー教師検索テストで「スコアが低い」「関係ないチャンクがヒットする」という場合は、チャンク設定かインデックス設定、あるいは検索方法を見直す必要があります。
室谷特に「キーワード検索で正確にヒットするか」と「セマンティック検索で意味的に近い内容がヒットするか」を両方テストすると、どちらの設定が適しているかがよくわかります。
テキトー教師本番リリースの前にこのテストをやっておくと、「なんで答えてくれないの?」というクレームを事前に防げるので、必ず実施するようにしています。講座でもここは強調してます。
ナレッジパイプライン 使い方
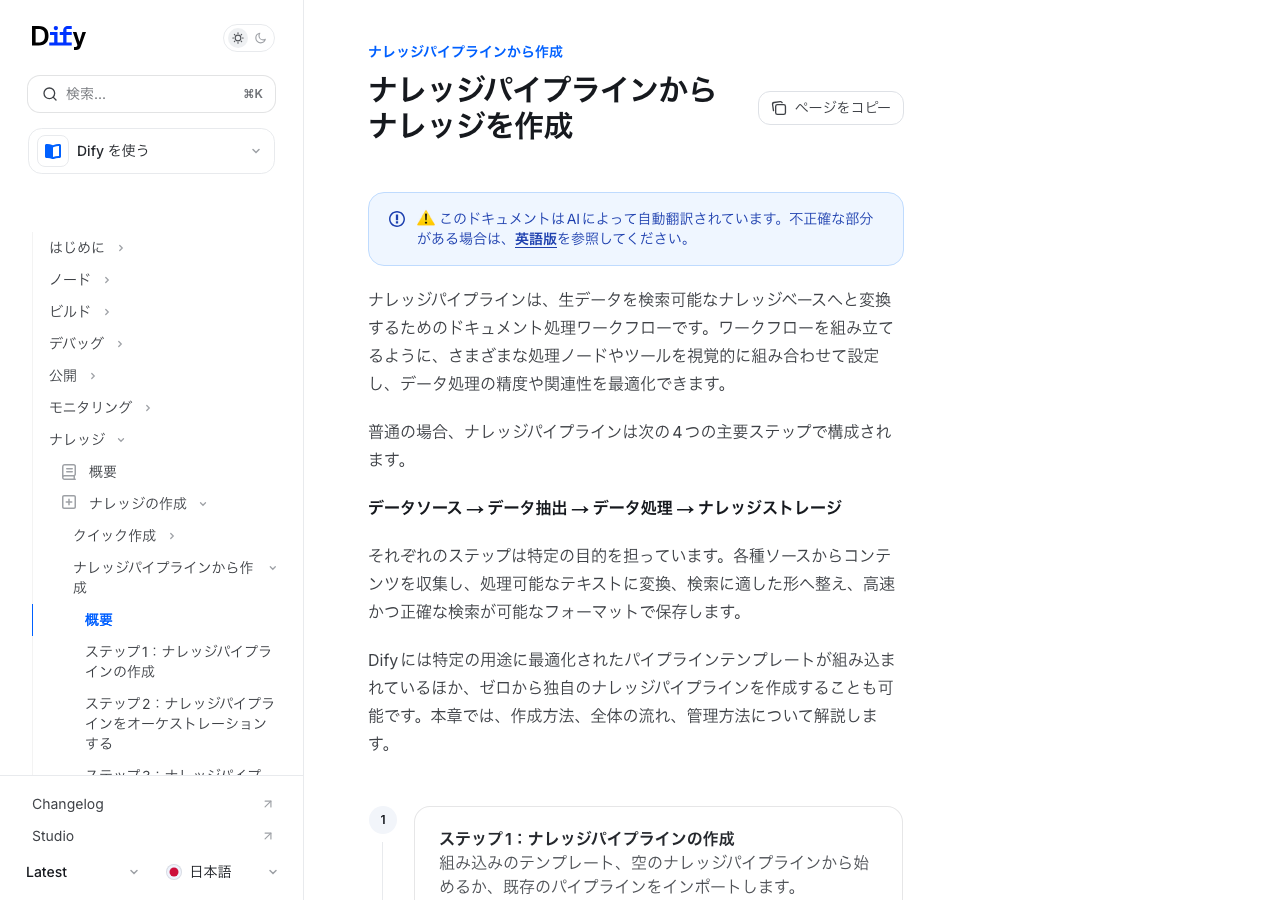
室谷次に「ナレッジパイプライン」という機能を説明しましょう。これ、かなり上級者向けの機能ですが、知ってると一気にできることが広がります。
テキトー教師ナレッジパイプラインというのは、「データの取り込みから加工、保存まで」を視覚的なワークフローで組める機能です。公式ドキュメントによると「生データを検索可能なナレッジベースへと変換するためのドキュメント処理ワークフロー」という定義です。
室谷基本の「クイック作成」ではできなかった、複雑なデータ処理を組み込めるんですよ。例えば「PDFを取り込む前にOCR処理を挟む」「Webスクレイピングで定期取得した内容を自動でナレッジに追加する」みたいなことができる。
テキトー教師パイプラインの構成は「データソース → データ抽出 → データ処理 → ナレッジストレージ」という流れです。各ステップにノードを置いて処理内容を組み立てます。
室谷作り方は、ナレッジベースを作成するときに「ナレッジパイプラインから作成」を選択します。テンプレートから始めることもできるし、ゼロから組み立てることもできます。
ナレッジパイプラインの作成ステップ
テキトー教師公式ドキュメントを見ると、パイプラインの作成は5つのステップで整理されています。
- ナレッジパイプラインの作成: テンプレートを使うか、ゼロから作成する
- パイプラインの構築: ノードを組み合わせてデータ処理フローを作る
- パイプラインの公開: テスト後に公開してドキュメント処理の準備をする
- ファイルのアップロード: 処理するドキュメントをアップロードする
- ナレッジベースの管理と活用: メンテナンス・テスト・設定変更を行う
室谷クイック作成と違うのは「2の構築」のところで、独自のデータ処理ロジックを差し込める点ですね。例えばPDFからテキストを抽出した後に不要な情報を削除するフィルタリング処理を入れたり、テキストを特定フォーマットに変換してからチャンクに分割したりできます。
テキトー教師ビジネス用途で特に使えるのが「Webサイトから定期的に情報を取得して自動更新するパイプライン」ですね。製品の仕様ページが更新されたら自動的にナレッジが更新される、みたいな仕組みが作れます。
室谷MYUUUでも、社内のConfluenceページをスクレイピングして定期的にナレッジを更新するパイプラインを検討してます。手動でドキュメントを更新するコストがけっこうかかってたので・・・
ナレッジベースの管理と最適化
テキトー教師ナレッジベースを作ったら終わりじゃなくて、継続的なメンテナンスが必要です。「作ったけど精度が落ちてきた」というのは、データが古くなってることが多いです。
室谷ドキュメントの追加・削除・編集はナレッジベースの管理画面から直接できます。チャンク単位での編集もできるので、特定のチャンクの内容が古い場合はそこだけ修正する、ということも可能です。
テキトー教師よくあるのが「引っ越しました」とか「担当者が変わりました」みたいな情報のアップデートですね。古い情報が残っているとナレッジが間違った回答を返してしまう。
チャンクの確認と更新を定期的にやるルーティンを作っておくといいです。
チャンクの確認と更新を定期的にやるルーティンを作っておくといいです。
室谷ドキュメントにはステータスがあって、「有効」「無効」の切り替えができます。一時的に使わないドキュメントは削除しなくても無効化できるので、後でまた使いたいときに便利ですね。
テキトー教師メタデータの管理も大事ですよ。後からメタデータフィルタリングを使いたくなったときに、ドキュメントにメタデータが設定されていないと使えません。
作成時から「どういう属性で絞り込みたいか」を考えてメタデータを設計しておくのがおすすめです。
作成時から「どういう属性で絞り込みたいか」を考えてメタデータを設計しておくのがおすすめです。
よくあるトラブルと解決方法
室谷最後に「ナレッジを設定したのにうまく動かない」という場合のトラブルシューティングをまとめておきましょう。
テキトー教師一番多いのが「アップロードしたPDFの内容をAIが認識できていない」というパターンです。原因として多いのが、PDFが画像化されていて文字として認識できないケース。
スキャンしたPDFはOCR処理が必要なので、テキストとして保存されたPDFを使うか、OCR処理を挟む必要があります。
スキャンしたPDFはOCR処理が必要なので、テキストとして保存されたPDFを使うか、OCR処理を挟む必要があります。
室谷次に多いのが「検索テストではヒットするのに、実際のチャットボットでは答えてくれない」というケースです。これはアプリのコンテキスト設定でナレッジベースが紐付いていないことが多い。
設定画面でちゃんとナレッジが選択されているか確認してください。
設定画面でちゃんとナレッジが選択されているか確認してください。
テキトー教師「複数のナレッジベースを使っているのに重み設定が変更できない」というエラーも見ます。これは複数のナレッジベースで埋め込みモデルが異なる場合に起きます。
同じ埋め込みモデルを使うか、Rerankモデルを設定することで解決できます。
同じ埋め込みモデルを使うか、Rerankモデルを設定することで解決できます。
室谷「ハイブリッド検索を使いたいのに選択肢が出てこない」という場合は、インデックス方法が「経済的」モードになっていないか確認してください。経済的モードではハイブリッド検索は使えません。
高品質モードに切り替えると解択肢が出てきます。
高品質モードに切り替えると解択肢が出てきます。
テキトー教師こういうトラブルのほとんどは、作成時の設定ミスか、複数ナレッジベース間の設定の不一致から来ています。エラーメッセージをよく読めば原因の見当がつくことが多いので、焦らず確認する癖をつけるといいですね。
外部ナレッジベースとの連携
室谷実は、Difyには「外部ナレッジベースと連携」という選択肢もあります。既にWeaviateやPineconeなどのベクターDBを社内で運用している場合、そのデータをDifyから直接使えるようになります。
テキトー教師エンタープライズで既にRAG基盤を持っている企業が、Difyのフロントエンドだけを使いたいというケースで活用されてますね。APIを介して外部のナレッジベースにアクセスする設定をします。
室谷外部ナレッジベース連携のメリットは「既存の資産を生かしつつDifyを使える」点です。移行コストをかけずに済む。
デメリットは設定の手間がかかること。エンジニアが必要になることも多いです。
デメリットは設定の手間がかかること。エンジニアが必要になることも多いです。
テキトー教師セキュリティ要件が厳しい企業だと、データをDifyのクラウドに置きたくないというケースもあります。その場合は外部ナレッジベースを社内に置いておいて、APIで繋ぐという構成がありですね。
室谷まずはDify標準のナレッジベースで試してみて、スケールアウトが必要になったら外部ナレッジベースへの移行を検討、というのが現実的な進め方だと思います。
ナレッジベース活用の実践事例
テキトー教師実際にどんな使い方をしている人が多いか、講座での事例をいくつか紹介します。
室谷まず多いのが「社内マニュアルQ&ABot」ですね。入社した社員が「有給の申請はどうすればいい?」「経費精算の方法は?」みたいな質問をBotに投げると、社内規程集から正確な情報を引いて答えてくれる。
テキトー教師MYUUUさんでもやってる事例ですね。「〇〇の手続きを人事に聞く」という無駄な時間が削減されて、人事担当者の負荷も下がる。
室谷次に多いのが「製品仕様照会Bot」です。複数の製品の仕様書をナレッジに入れておいて、顧客からの問い合わせに対して「こちらの製品のこの仕様は〇〇です」と回答する。
カスタマーサポートの現場で使われてますね。
カスタマーサポートの現場で使われてますね。
テキトー教師「競合他社分析アシスタント」も面白い使い方です。競合の公式サイト情報をWebクローリングでナレッジに取り込んでおいて、「競合Aと競合Bの価格差は?」みたいな質問に答えさせる。
室谷法律・規制関連の文書をナレッジに入れて「コンプライアンスチェッカー」を作るケースも増えています。「この文書はGDPRに準拠しているか?」みたいな質問に、法規制の条文を参照しながら回答させる。
テキトー教師ただしこういった法的判断が絡む用途では、AIの回答をそのまま信じるんじゃなくて、専門家の確認と組み合わせて使うことが大事ですよね。AIの補助ツールとして位置付けるのが適切です。
室谷MYUUUでやってみて特に効果的だったのは「過去のプロジェクト知識ベース」です。完了したプロジェクトの議事録や成果物をナレッジに入れておいて、新しいプロジェクトで「以前似たようなことをやったか?」「どう解決したか?」を検索できるようにする。
組織の知識の継承に使えます。
組織の知識の継承に使えます。
テキトー教師「ノウハウが退職した人に頭の中にある」という問題、どの企業でも悩んでますよね。退職前にドキュメントを整備してもらってナレッジに入れておく、という使い方はかなり現実的だと思います。
チャットフローとワークフローの使い分け
室谷ナレッジを使うアプリを作るとき、「チャットボット」「チャットフロー」「ワークフロー」のどれを使うか迷う人もいますよね。ここを整理しておきましょう。
テキトー教師アプリタイプを比較すると、それぞれこういう特徴があります。
| アプリタイプ | 特徴 | ナレッジとの相性 |
|---|---|---|
| チャットボット | 会話形式のシンプルな実装 | コンテキストにナレッジを追加するだけ |
| チャットフロー | 会話形式、細かい制御が可能 | ナレッジ検索ノードで柔軟な処理 |
| ワークフロー | バッチ処理・自動化向け | ナレッジ検索ノードを他のノードと組み合わせ |
室谷「とにかく早く作りたい」なら チャットボット。「少し凝った処理をしたい、でも会話形式で使いたい」ならチャットフロー。
「バッチ処理や自動化ルーティンの一部としてナレッジを使いたい」ならワークフロー、という使い分けです。
「バッチ処理や自動化ルーティンの一部としてナレッジを使いたい」ならワークフロー、という使い分けです。
テキトー教師初めてナレッジ機能を試すなら、絶対にチャットボットから始めることをお勧めします。設定が最もシンプルで、ナレッジの精度検証もしやすい。
慣れてきたらチャットフロー、ワークフローへとステップアップしていけばいいと思います。
慣れてきたらチャットフロー、ワークフローへとステップアップしていけばいいと思います。
室谷本番運用を考えると、チャットフローがバランスいいですね。会話の履歴管理、ナレッジ検索の細かい設定、分岐処理なんかが全部できて、インターフェースとしてはユーザーに使いやすいチャット形式で提供できる。
テキトー教師エンドユーザーに直接見せるツールを作るなら、「引用と帰属」の設定もしっかりしておくと信頼性が上がります。どの文書のどの部分を参照したかが明示されるので、「AIが勝手に言ってるんじゃなくて、ちゃんとした根拠があるんだ」とユーザーが安心できます。
室谷精度の高いナレッジBotを作るためのチェックリストをまとめると、こんな感じになります。
- ドキュメントは適切なフォーマットで準備する(スキャンPDFはOCR処理が必要)
- チャンク設定はプレビューで確認してから確定する
- インデックス方法は本番では高品質モードを選ぶ
- 検索方法は最初はハイブリッドか重み設定で試す
- TopKは3〜5から始める
- リリース前に検索テストで精度確認
- メタデータは最初から設計しておく
- 定期的にドキュメントのメンテナンスをする
テキトー教師このチェックリストを頭に入れておくと、「動かない」「精度が出ない」というつまずきをかなり防げますよ。Difyのナレッジ機能、ぜひ使いこなしてください。
ワークフローでナレッジ検索ノードを使う
室谷最後にワークフロー・チャットフローの「ナレッジ検索ノード」についても触れておきましょう。チャットボットで単純にナレッジを参照するだけじゃなくて、複雑な処理の一部としてナレッジ検索を組み込みたい場合に使います。
テキトー教師ナレッジ検索ノードをワークフローに追加すると、「入力に対してナレッジベースを検索し、その結果を次のノードに渡す」という処理ができます。例えば「ユーザーの入力 → ナレッジ検索 → 検索結果をLLMに渡してまとめる → 回答を返す」というパイプラインを組めます。
室谷普通のチャットボットのコンテキスト設定でナレッジを繋ぐより、このノードを使う方が細かい制御ができます。TopKやスコア閾値をノードの設定として明示的に設定できるのと、検索結果を一度確認してから次の処理に渡すことができる。
テキトー教師メタデータフィルタリングも、ワークフローのナレッジ検索ノードで使えます。前のノードから受け取った変数を使ってフィルタ条件を動的に設定するとか、ユーザーが選んだカテゴリに応じて検索対象を変えるとかが実現できる。
室谷実際に活用事例として面白いのが、「FAQ振り分けBot」ですね。ユーザーの質問を質問分類器ノードで分類してから、カテゴリに合ったナレッジベースを使って回答するというフロー。
複数のナレッジを使い分けることで、それぞれのナレッジの精度を上げられるんです。
複数のナレッジを使い分けることで、それぞれのナレッジの精度を上げられるんです。
テキトー教師全部を1つのナレッジベースに詰め込むより、用途別に分けた方が検索精度が上がることが多いですよね。「人事FAQ」「IT FAQ」「経営情報」みたいに分けておいて、質問に応じて適切なナレッジを検索する設計です。
よくある質問
室谷じゃあFAQもまとめておきましょう。ナレッジ周りでよく聞かれる質問をいくつか答えていきます。
テキトー教師まず「ナレッジベースのデータはリアルタイムで更新されますか?」という質問。Notionやウェブサイトのインポートは同期のタイミングを設定できますが、完全なリアルタイムではありません。
最新情報を反映したい場合は定期的に手動または自動で再インポートが必要です。
最新情報を反映したい場合は定期的に手動または自動で再インポートが必要です。
室谷「無料プランでもナレッジ機能は使えますか?」という質問も多いです。Difyの無料プランでもナレッジ機能自体は使えます。
ただし、高品質インデックスを使う場合はOpenAIなど埋め込みモデルのAPI利用料がかかります。経済的モードを使えば追加コストを抑えることもできます。
ただし、高品質インデックスを使う場合はOpenAIなど埋め込みモデルのAPI利用料がかかります。経済的モードを使えば追加コストを抑えることもできます。
テキトー教師「ナレッジベースに入れたデータはDifyに学習されますか?」という不安の声もよく聞きます。ナレッジに入れたデータはDifyのサーバー上に保存されますが、LLMの学習データには使われません。
機密情報を扱う場合はセルフホスト版のDifyを使うことを検討してください。
機密情報を扱う場合はセルフホスト版のDifyを使うことを検討してください。
室谷「1つのナレッジベースに入れられるドキュメント数の上限は?」という質問。Difyのクラウド版では上限があり、プランによって異なります。
大量のドキュメントを管理したい場合はセルフホスト版が現実的です。
大量のドキュメントを管理したい場合はセルフホスト版が現実的です。
テキトー教師「Difyのナレッジベースと外部のベクターDBの違いは?」という技術的な質問もあります。Difyのナレッジベースは内部的にベクターDBを使っていますが、それをDifyが管理してくれます。
WeaviateやMilvusなどの外部ベクターDBと連携させる「外部ナレッジベース」という選択肢もあって、既にベクターDBを使っている場合はAPI経由で統合できます。
WeaviateやMilvusなどの外部ベクターDBと連携させる「外部ナレッジベース」という選択肢もあって、既にベクターDBを使っている場合はAPI経由で統合できます。
まとめ:Difyのナレッジ機能を使いこなすポイント
室谷最後にまとめましょう。今回のポイントをざっと振り返ります。
テキトー教師ナレッジ機能の肝は、チャンク設定とインデックス方法の選択です。ここを適切に設定するだけで、「全然答えてくれない」が「精度高く答えてくれる」に変わります。
室谷検索方法はハイブリッド検索が最強ですが、コストとのバランスで重み設定から始めるのも合理的です。TopKは3〜5、スコア閾値は状況に応じて調整する。
テキトー教師作ったら必ず「検索テスト」を実行してください。実際のユーザーが投げそうな質問で試して、意図したチャンクがヒットするか確認するのがナレッジ精度向上の近道です。
室谷本番運用に入ったら定期的なメンテナンスも忘れずに。古いドキュメントは更新するか削除する。
メタデータを活用した絞り込みで、大規模なナレッジベースでも精度を維持できます。
メタデータを活用した絞り込みで、大規模なナレッジベースでも精度を維持できます。
テキトー教師ナレッジパイプラインを使いこなせば、定期的なデータ更新の自動化や複雑なデータ前処理も実現できます。ある程度Difyに慣れてきたら挑戦してみてください。
室谷Difyのナレッジ機能、最初は敷居が高く見えますが、仕組みを理解して順番通りに設定すれば確実に動かせます。社内の情報資産をAIに読ませることで、業務効率は大きく変わりますよ。
ぜひ試してみてください。
ぜひ試してみてください。