ChatGPTとWhisperで音声文字起こし完全ガイド【2026年最新】:使い方・API・議事録・Python連携まで徹底解説
前回はChatGPTのタスク機能を取り上げましたが、今回はChatGPTと音声AIの組み合わせを深掘りしていきます。OpenAIのWhisperは文字起こしAIとして世界中で使われており、ChatGPT Appの音声入力もWhisperが支えています。この記事では、WhisperとChatGPTの関係から始まり、API連携・議事録自動化・Pythonでの実装まで、実際に使える情報を全部まとめていきます。
ChatGPTとWhisperの関係を整理する
 室谷代表取締役
室谷代表取締役Whisperの話、.AI(ドットエーアイ)コミュニティでもよく出てくるんですよね。でも「ChatGPTとWhisperって何が違うの?」という質問が一番多いんですよ・・・
 テキトー教師.AI認定講師
テキトー教師.AI認定講師講座でも初日に出てきますね。「ChatGPTに話しかけたら文字になるじゃないですか、あれってWhisper?」みたいな質問が来ます(笑)。
整理すると、WhisperはOpenAIが開発した音声認識専用のAIモデルです。音声をテキストに変換することに特化しています。
整理すると、WhisperはOpenAIが開発した音声認識専用のAIモデルです。音声をテキストに変換することに特化しています。
室谷代表取締役ChatGPTはLLM(大規模言語モデル)で、テキストの理解・生成が得意。WhisperはSTT(Speech to Text)、つまり音声からテキストへの変換が得意。
この2つはそもそも役割が違うんですよね。
この2つはそもそも役割が違うんですよね。
テキトー教師.AI認定講師ただ、実際のアプリとしてのChatGPTを使うと、話しかけたら文字に起こして、さらにGPTが返答してくれる、というのが一体化しているように見えますよね。あれはWhisperで音声を変換してから、GPTが処理している、という2段構えなんです。
室谷代表取締役そうなんですよ。ChatGPTのモバイルアプリやデスクトップアプリで「音声で話す」機能がありますが、あの裏では音声認識にWhisperが動いていたんですね。
ただ最近は、それがさらに進化していて・・・
ただ最近は、それがさらに進化していて・・・
テキトー教師.AI認定講師そこが面白いところですよね。2026年現在、OpenAIはWhisper単体モデル(whisper-1)に加えて、gpt-4o-transcribeとgpt-4o-mini-transcribe、さらに話者識別機能付きのgpt-4o-transcribe-diarizeという新しいモデルも提供しています。
室谷代表取締役whisper-1はオープンソースのWhisperをベースにしたAPIモデルで、2022年のリリース以来ずっと使われてきました。でも今は、GPT-4oの技術を音声認識に転用した新しいモデルが出てきていて、精度が上がっているんですよね。
テキトー教師.AI認定講師コミュニティのメンバーさんから「どのモデルを使えばいい?」とよく聞かれますが、用途によって使い分けが必要です。まとめるとこうなります。
| モデル | 特徴 | 対応出力形式 |
|---|---|---|
| whisper-1 | 実績あり・安定。タイムスタンプ対応 | json, text, srt, verbose_json, vtt |
| gpt-4o-transcribe | 高精度。プロンプト指定可能 | json, text |
| gpt-4o-mini-transcribe | 高コスパ。プロンプト指定可能 | json, text |
| gpt-4o-transcribe-diarize | 話者識別対応 | json, text, diarized_json |
室谷代表取締役whisper-1がSRT形式やVTT形式(字幕ファイル)に対応しているのは今でも強みですね。動画の字幕を自動生成したいケースではwhisper-1一択です。
テキトー教師.AI認定講師gpt-4o-transcribeは「プロンプトを指定できる」のが大きいですよね。「医療用語が多い会話です」と事前に伝えておくと、専門用語の認識精度が上がります。
室谷代表取締役MYUUUでも営業商談の録音を文字起こしする際に使っていますが、最初は「はい」「えっと」みたいなフィラー(言い淀み)をどうするか悩みました。プロンプトで「フィラーも含めて書き起こしてください」と指定できるのは助かりますね。
Whisperで文字起こしする基本的な使い方
テキトー教師.AI認定講師では実際の使い方を整理していきましょう。WhisperにはAPIを使う方法以外にも、いくつかのアプローチがあります。
室谷代表取締役まず一番シンプルなのは、ChatGPTのWebアプリやモバイルアプリのマイクボタンを使う方法ですよね。これはWhisperがバックエンドで動いていますが、技術的な知識は一切不要です。
テキトー教師.AI認定講師ただし、ChatGPTのUIから使う場合は、音声入力→テキスト変換→GPTの回答、というフローになるので、「文字起こし結果だけほしい」というニーズには向かないんですよ。
室谷代表取締役そうなんですよね。「会議の録音を文字に起こしたい」「インタビューの音声をテキスト化したい」という場合は、Whisper APIを直接使う必要があります。
テキトー教師.AI認定講師もうひとつの選択肢は、Whisperをローカルで動かす方法です。OpenAIはWhisperをオープンソースで公開しているので、自分のPCやサーバーにインストールして、ネット接続なしで使うことができます。
室谷代表取締役ただローカルで動かすには、それなりのPCスペック(特にGPU)が必要で、セットアップも複雑です。手軽に始めるなら、やっぱりAPIが一番ですね。
テキトー教師.AI認定講師まとめるとこういう選択肢があります。
| 方法 | コスト | 手軽さ | データプライバシー |
|---|---|---|---|
| ChatGPT UI(音声入力) | 無料〜(プランによる) | 最高 | OpenAIサーバーに送信 |
| Whisper API(OpenAI) | $0.003〜$0.006/分 | 中 | OpenAIサーバーに送信 |
| ローカル実行(オープンソース) | 無料(GPU代のみ) | 難 | 完全ローカル |
室谷代表取締役医療系とか法律系で「音声データを外部サービスに送れない」というケースだと、ローカル実行が必須になります。でも一般的なビジネス用途なら、APIで十分です。
テキトー教師.AI認定講師ChatGPTのWebアプリで「ファイルをアップロードして文字起こし」もできますが、これは実はWhisper APIを経由した処理ではなく、GPTのマルチモーダル機能で処理されています。仕組みが少し違うんですよ。
室谷代表取締役そういう細かい違いを知っておくと、「なぜかうまくいかない」というトラブルを防げますよね。SRTファイルを生成したいのにChatGPTのアップロード機能を使っても無駄、みたいな。
テキトー教師.AI認定講師WhisperのAPIを使う際の基本的な対応音声フォーマットも確認しておきましょう。mp3, mp4, mpeg, mpga, m4a, wav, webm に対応しています。
ファイルサイズの上限は1リクエストあたり25MBです。
ファイルサイズの上限は1リクエストあたり25MBです。
室谷代表取締役25MBって聞くと小さく感じますが、mp3形式ならだいたい30分〜45分相当ですね。会議1本くらいは普通に入ります。
それ以上の場合は分割が必要です。
それ以上の場合は分割が必要です。
テキトー教師.AI認定講師PyDubというPythonライブラリを使って分割する方法が公式でも紹介されていますね。25MBを超えたら自動的に10分ずつに分割してAPIに投げる、みたいなスクリプトを一度作っておくと便利です。
Whisper APIの使い方:Python・curlで実装する
室谷代表取締役では実際のAPI実装の話をしましょう。ここが「chatgpt whisper api」で検索してくる人が一番知りたいところだと思うんですよね。
テキトー教師.AI認定講師そうですね。まず前提として、Whisper APIを使うにはOpenAI APIキーとクレジットカードの登録が必要です。
Whisper APIには無料枠がなく、最初の1分から課金されます。
Whisper APIには無料枠がなく、最初の1分から課金されます。
室谷代表取締役「ChatGPT Plusに加入しているから使えるはず」と思っている人が多いんですが、それは別なんですよ。ChatGPT(chat.openai.com)の有料プランと、OpenAI API(platform.openai.com)の課金は完全に別管理です。
テキトー教師.AI認定講師室谷代表取締役では実装の話に入りましょう。一番シンプルなPythonでの実装はこうなります。
python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/audio.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file
)
print(transcription.text)model="gpt-4o-transcribe" の部分を "whisper-1" や "gpt-4o-mini-transcribe" に変えるだけでモデルを切り替えられます。精度重視なら gpt-4o-transcribe、コスト重視なら gpt-4o-mini-transcribe、SRTファイルが必要なら whisper-1、という使い分けですね。室谷代表取締役プロンプトを指定して精度を上げる場合はこうなります。
python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/meeting.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
response_format="text",
prompt="以下は日本語のビジネス会議の録音です。固有名詞:MYUUU、.AI(ドットエーアイ)"
)
print(transcription.text)promptパラメータに事前知識を入れておくと、固有名詞や専門用語の認識が大幅に改善されますよ。社名や製品名が多い会議録の場合は必須だと思いますね。
室谷代表取締役curlで試したい人向けには、こういう形になります。
bash
curl --request POST \
--url https://api.openai.com/v1/audio/transcriptions \
--header "Authorization: Bearer $OPENAI_API_KEY" \
--header 'Content-Type: multipart/form-data' \
--form file=@/path/to/file/audio.mp3 \
--form model=gpt-4o-transcribeAPIのエンドポイントは
https://api.openai.com/v1/audio/transcriptions です。これはWhisper APIも gpt-4o-transcribeも同じエンドポイントを使います。室谷代表取締役タイムスタンプ付きのSRTファイルを生成したい場合は、whisper-1モデルで
response_format="srt" を指定します。python
from openai import OpenAI
client = OpenAI()
audio_file = open("/path/to/file/audio.mp3", "rb")
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="srt"
)
# SRTファイルとして保存
with open("output.srt", "w", encoding="utf-8") as f:
f.write(transcription)SRTはgpt-4o-transcribeでは生成できない点に注意ですね。動画の字幕作成にはwhisper-1を使う必要があります。
室谷代表取締役話者識別(誰が話しているかの識別)が必要な場合は、
gpt-4o-transcribe-diarize モデルを使います。会議の議事録で「Aさんが言った」「Bさんが言った」を自動的に分けてくれるのはかなり実用的ですね。テキトー教師.AI認定講師ただし、diarizeモデルは30秒以上の音声の場合に
chunking_strategy="auto" パラメータが必要です。これを忘れるとエラーになるので注意してください。室谷代表取締役出力形式のパターンをまとめるとこうなります。
| response_format | 内容 | 対応モデル |
|---|---|---|
| json | テキスト(JSON形式) | 全モデル |
| text | テキスト(プレーンテキスト) | 全モデル |
| srt | 字幕ファイル(SRT) | whisper-1のみ |
| vtt | 字幕ファイル(VTT) | whisper-1のみ |
| verbose_json | 詳細情報付きJSON | whisper-1のみ |
| diarized_json | 話者識別付きJSON | gpt-4o-transcribe-diarizeのみ |
テキトー教師.AI認定講師このあたりの使い分けを最初に整理しておくと、「なんかうまくいかない」というトラブルがぐっと減ります。SRTが欲しいのにgpt-4o-transcribeを使っている、みたいなことが講座でもよくあるので(笑)
Whisper APIの料金と制限
室谷代表取締役料金の話は外せないですよね。「chatgpt whisper pricing」で検索してくる人も多いので、ちゃんと整理しましょう。
テキトー教師.AI認定講師| モデル | 料金(1分あたり) | 時間換算(1時間) |
|---|---|---|
| whisper-1 | $0.006/分 | $0.36/時間 |
| gpt-4o-transcribe | $0.006/分 | $0.36/時間 |
| gpt-4o-mini-transcribe | $0.003/分 | $0.18/時間 |
室谷代表取締役whisper-1とgpt-4o-transcribeが同じ$0.006/分というのは面白いですよね。精度が上がっているのに料金が同じ。
gpt-4o-mini-transcribeはその半額なので、コスト最優先ならこちらです。
gpt-4o-mini-transcribeはその半額なので、コスト最優先ならこちらです。
テキトー教師.AI認定講師具体的な月額コストを計算するとこうなります。
| 月の使用量 | gpt-4o-mini-transcribe | whisper-1 / gpt-4o-transcribe |
|---|---|---|
| 10時間/月 | $1.80 | $3.60 |
| 50時間/月 | $9.00 | $18.00 |
| 100時間/月 | $18.00 | $36.00 |
| 500時間/月 | $90.00 | $180.00 |
室谷代表取締役個人や小規模チームで使う分には、月$3〜$18くらいで十分収まりますよね。1日の会議が3〜4本あっても月30時間程度なので、$5〜$10の範囲です。
テキトー教師.AI認定講師重要な制限として覚えておいてほしいのは3点ですね。
- ファイルサイズ上限: 1リクエストあたり25MB
- 対応フォーマット: mp3, mp4, mpeg, mpga, m4a, wav, webm
- 無料枠: なし(クレジットカード必須)
室谷代表取締役25MBの制限は、mp3でだいたい30〜45分相当です。それ以上の長い音声は事前に分割する必要があります。
テキトー教師.AI認定講師分割にはPythonのPyDubライブラリを使うのが一般的ですね。公式ドキュメントでも紹介されています。
python
from pydub import AudioSegment
# 音声ファイルを読み込む
audio = AudioSegment.from_mp3("long_meeting.mp3")
# 10分ずつに分割
ten_minutes = 10 * 60 * 1000 # ミリ秒で指定
chunks = [audio[i:i+ten_minutes] for i in range(0, len(audio), ten_minutes)]
# 分割ファイルを書き出す
for i, chunk in enumerate(chunks):
chunk.export(f"chunk_{i}.mp3", format="mp3")分割するときのコツは「文の途中で切らない」こと。文の途中で切れると、その部分の精度が落ちることがあります。
PyDubで無音区間を検出して、そこで切るようにすると品質が上がりますよ。
PyDubで無音区間を検出して、そこで切るようにすると品質が上がりますよ。
テキトー教師.AI認定講師あとは、Whisper APIにはHIPAA(米国の医療情報プライバシー法)の対応が現時点でないことも覚えておいてほしいです。医療機関や患者情報を含む音声を扱う場合は、ローカル実行か、HIPAA対応サービスを選ぶ必要があります。
Whisper APIのレート制限
室谷代表取締役レート制限の話もしておきましょう。大量処理したい場合に詰まるポイントです。
テキトー教師.AI認定講師室谷代表取締役一般的な話として、並列リクエストを一度に大量に送ると制限に引っかかることがあります。バッチ処理で大量の音声を処理したい場合は、リクエストの間に少し待機時間を入れるか、OpenAIのBatch APIを活用するのが安全ですね。
ChatGPTとWhisperで議事録を自動化する
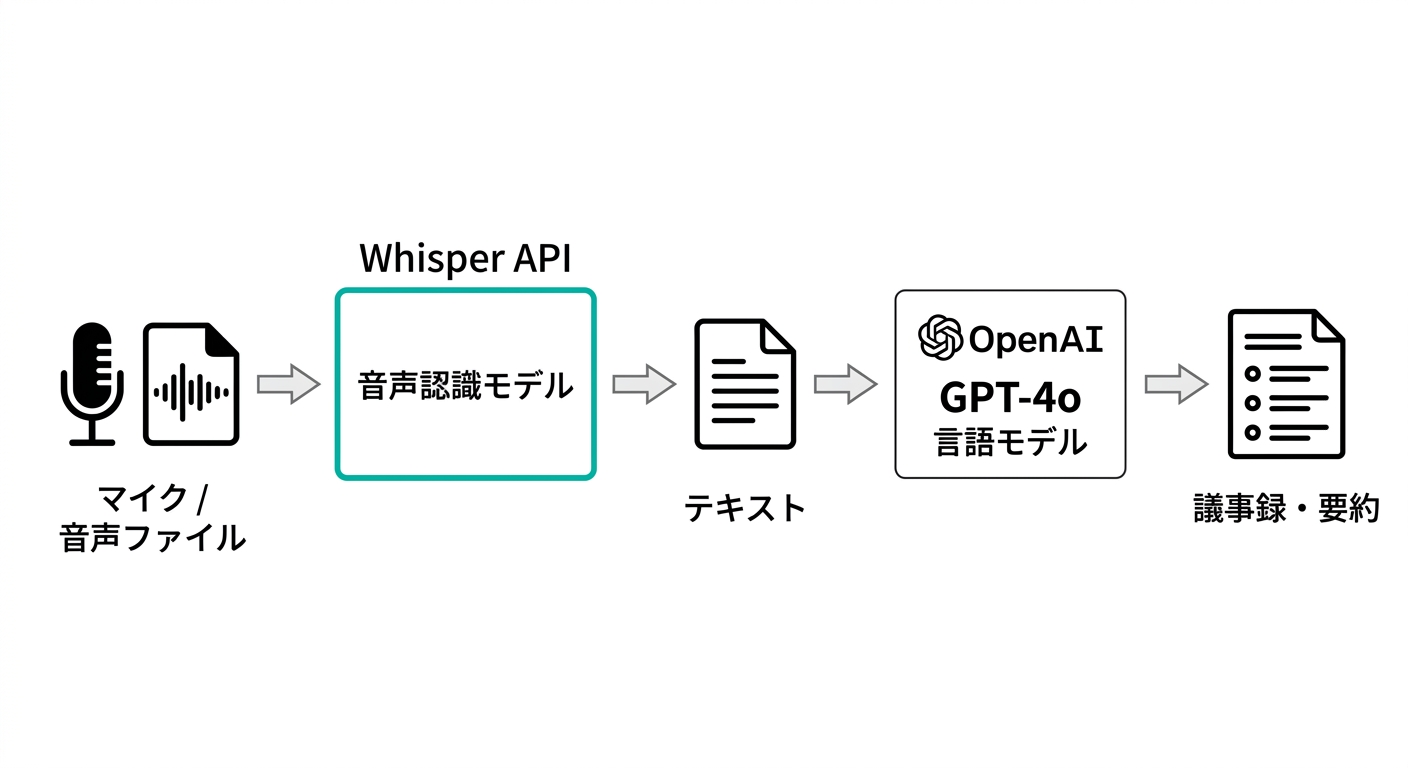
テキトー教師.AI認定講師ここが一番実用的なセクションですよね。「chatgpt whisper 議事録」の活用です。
室谷代表取締役MYUUUでも実際に導入しています。ZoomやMeet録画→Whisper文字起こし→GPTで議事録整形、という流れを自動化していて、会議後15分以内にSlackに議事録が届くようになっています。
テキトー教師.AI認定講師そのフローを詳しく教えてもらえますか?コミュニティのメンバーさんからも「具体的にどうやるの?」という声が多いので。
室谷代表取締役図解のとおり、大きく2段階のフローになっています。
code
音声録音(Zoom/Meet/手録り)
↓
音声ファイル取得(mp3/m4aなど)
↓
Whisper API(gpt-4o-transcribe)で文字起こし
↓
GPT-4o(または GPT-5.4 mini)で整形
・アジェンダ別に構造化
・アクションアイテム抽出
・決定事項のサマリー
↓
Slack / Notionに投稿このフローをPythonで書くとこうなりますね。
python
from openai import OpenAI
client = OpenAI()
def transcribe_meeting(audio_path: str) -> str:
"""音声ファイルを文字起こしする"""
with open(audio_path, "rb") as audio_file:
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
response_format="text",
prompt="以下はビジネス会議の録音です。話者の発言をできる限り正確に文字起こししてください。"
)
return transcription
def create_minutes(transcription: str) -> str:
"""文字起こしから議事録を生成する"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "あなたは優秀な秘書です。会議の文字起こしから、構造化された議事録を作成してください。"
},
{
"role": "user",
"content": f"""以下の会議文字起こしを元に、議事録を作成してください。
【フォーマット】
## 会議概要
## 決定事項
## アクションアイテム(担当者・期限付き)
## 次回会議の議題
【文字起こし】
{transcription}"""
}
]
)
return response.choices[0].message.content
# 使い方
transcription = transcribe_meeting("meeting.mp3")
minutes = create_minutes(transcription)
print(minutes)このコードをベースに、入力フォルダを監視して新しい音声ファイルが置かれたら自動実行する仕組みにすると、ほぼ完全自動化できます。
テキトー教師.AI認定講師話者識別(誰が何を言ったか)まで含めたい場合は、gpt-4o-transcribe-diarizeを使うのがいいですよね。ただ、対面会議より電話会議の方が音質が安定していて精度が出やすいです。
室谷代表取締役そうなんですよね。ザワザワした環境音があると精度が落ちます。
できるだけマイクを話者に近づけた録音環境を作ることが大事です。
できるだけマイクを話者に近づけた録音環境を作ることが大事です。
テキトー教師.AI認定講師プロンプトの工夫も重要で、「この会議の参加者はAさん・Bさん・Cさんです」と先に伝えておくと、話者の識別精度が上がります。
室谷代表取締役実際、MYUUUの社内での使い方で面白かったのは、営業の商談録音を文字起こしして、「このお客様が悩んでいるポイントは?」「次のステップとして提案すべきことは?」をGPTに分析させる使い方ですね。Whisperがベースにあるから、音声データがそのままビジネスインテリジェンスに変換されていくんですよ。
n8nやDifyとのWhisper連携
テキトー教師.AI認定講師コードを書かずにWhisperと連携したい場合は、n8nやDifyとの組み合わせも有効ですよね。「chatgpt n8n」の文脈でも注目されている領域です。
室谷代表取締役n8nだと「ファイルがDropboxに追加されたらWhisper APIに投げて文字起こし、その結果をNotionに保存する」みたいなフローをGUIで作れます。
テキトー教師.AI認定講師Difyでも、WhisperのAPIキーを環境変数に設定してワークフローに組み込むことができますね。「音声入力→文字起こし→LLMで処理→出力」の流れをノーコードで作れます。
室谷代表取締役ただ、DifyとWhisperの組み合わせはまだ設定が少し複雑で、ドキュメントも少ないんですよね。n8nの方がWhisper連携のテンプレートが充実していて始めやすいと思います。
Whisper vs ChatGPT Voice Mode:何が違うのか
テキトー教師.AI認定講師「whisper vs chatgpt」という検索をする人が結構いますが、これは「WhisperとChatGPTのVoice Modeは何が違うの?」という疑問だと思うんですよ。
室谷代表取締役そうですよね。一言で言うと、両者は「目的」が全然違います。
テキトー教師.AI認定講師まとめるとこうなります。
| 機能 | Whisper API | ChatGPT Voice Mode |
|---|---|---|
| 目的 | 音声→テキスト変換(STT) | 音声での会話(双方向) |
| 出力 | テキストのみ | テキスト + 音声(TTS) |
| 対話性 | なし(1回変換するだけ) | あり(続けて会話できる) |
| 用途 | 録音の文字起こし・バッチ処理 | リアルタイム音声アシスタント |
| プログラムからの利用 | API経由で可能 | Realtime API経由で可能 |
| コスト | $0.003〜$0.006/分 | より高い(入出力両方課金) |
室谷代表取締役Voice ModeはWhisperで音声を認識して、GPTが考えて、Text-to-Speechで音声で返す、という3段構えになっています。だからコストも高いし、レイテンシも大きい。
でも「話しかけたら話して返ってくる」という体験はWhisper単体ではできないんですよね。
でも「話しかけたら話して返ってくる」という体験はWhisper単体ではできないんですよね。
テキトー教師.AI認定講師用途で使い分けるとすると、こういう感じでしょうか。
- Whisper API: 録音ファイルを後処理で文字起こし、バッチ処理、字幕生成
- ChatGPT Voice Mode: リアルタイム音声会話、音声アシスタント、語学学習
室谷代表取締役「会議を録音してあとで文字起こしする」ならWhisper API一択。「打ち合わせしながらAIに聞きたい」ならVoice Mode、という感じですね。
テキトー教師.AI認定講師開発者向けに言うと、音声会話アプリを作りたい場合はOpenAIのRealtime APIを使うのが今のベストプラクティスです。Realtime APIでwhisper-1やgpt-4o-transcribeを使ったリアルタイム文字起こしも設定できます。
精度を上げるためのWhisperプロンプト活用法
室谷代表取締役Whisperの精度改善は、実は「プロンプトの使い方」で大きく変わるんですよね。これ、意外と知られていないポイントです。
テキトー教師.AI認定講師gpt-4o-transcribeとgpt-4o-mini-transcribeは、LLMと同じようにプロンプトで動作を制御できます。whisper-1も一定の制御はできますが、より限定的です。
室谷代表取締役具体的なプロンプト活用パターンをいくつか紹介しましょう。
固有名詞・専門用語を正確に認識させる
テキトー教師.AI認定講師一番よくあるユースケースですね。デフォルトだと社名や製品名を別の単語に変換してしまうことがあります。
python
# 固有名詞リストをプロンプトに埋め込む
prompt = """
この音声は、MYUUU株式会社の社内会議の録音です。
固有名詞: MYUUU、.AI(ドットエーアイ)、Claude Code、Dify、n8n
これらの単語は変換せず、そのまま書き起こしてください。
"""
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
prompt=prompt
)こうすると「エムワイユーユー」を「MYUUU」と正しく書き起こしてくれます。
句読点・フィラーワードを制御する
テキトー教師.AI認定講師デフォルトだと、Whisperは句読点を省略することがあります。議事録として使いたい場合は句読点が必要なので、こう指定します。
python
# 句読点を含めて書き起こすよう指示
prompt = "以下は会議の録音です。句読点(。、!?)を適切に含めて書き起こしてください。"フィラーワード(「えっと」「あの」「まあ」)を含めるか省略するかも、プロンプトで制御できます。クリーンな議事録にしたい場合は省略、逐語的な文字起こしが必要なケースは含める設定にします。
多言語音声への対応
テキトー教師.AI認定講師Whisperは98言語に対応していますが、日本語と英語が混在する音声は難しいケースがあります。
室谷代表取締役MYUUUのエンジニアMTGとか、英語の技術用語が普通に出てきますからね。「これはGPUのスペックで〜」みたいな会話を正確に書き起こすのは少し工夫が必要です。
テキトー教師.AI認定講師この場合は、
language="ja" パラメータで言語を明示的に指定した上で、プロンプトに「英語の専門用語はそのままアルファベットで書き起こしてください」と入れると改善されますよ。python
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
language="ja",
prompt="日本語と英語が混在する会話です。英語の専門用語はアルファベットのまま書き起こしてください。例:GPU、API、LLM、SaaS"
)Whisperは98言語で訓練されていますが、APIとして提供されているのは「WER(単語誤り率)が50%未満」の言語だけです。日本語は当然その基準を満たしていて、精度もかなり高いですよ。
実際の活用シーンとWhisper連携ツール
テキトー教師.AI認定講師ここまでAPI実装の話をしてきましたが、コードを書かずにWhisperを使えるツールも多くあります。
室谷代表取締役「chatgpt whisper app」や「chatgpt whisper ios」で検索してくる人は、スマートフォンから手軽に使いたいケースが多いですよね。
テキトー教師.AI認定講師代表的なツールと使い方をまとめるとこうなります。
| カテゴリ | ツール・方法 | 特徴 |
|---|---|---|
| スマートフォン | ChatGPTアプリの音声入力 | 最も手軽。文字起こし結果はチャット画面に表示 |
| Webブラウザ | Whisper Web(オープンソース) | ブラウザ上でローカル実行 |
| 議事録特化ツール | Otter.ai, tl;dv, Notionのミーティング録音 | Whisperベースのサービスが多い |
| 自動化ツール | n8n, Make(旧Integromat) | ノーコードでWhisper APIと連携可能 |
| Python | openaiライブラリ | 最も柔軟。バッチ処理も可能 |
| GitHub | various Whisper wrappers | オープンソースのラッパーツール多数 |
室谷代表取締役実務で一番使われているのはやはり議事録特化ツールですよね。Otter.aiやtl;dvはWhisperベースのエンジンを使っていて、Zoomとの連携も最初から組み込まれています。
テキトー教師.AI認定講師自分でコードを書きたくない場合は、n8nがおすすめです。Whisper APIのノードが用意されていて、「Zoomの録音が終わったら自動でWhisperに投げてNotionに保存する」というワークフローを視覚的に作れます。
室谷代表取締役ただ、カスタマイズの自由度はPythonスクリプトが一番高いですね。プロンプトのチューニングや後処理の柔軟性は自分でコードを書いた方が圧倒的に細かくコントロールできます。
GitHubで使えるWhisperツール
テキトー教師.AI認定講師「chatgpt whisper github」で検索してくる人向けに、参考になるリポジトリも紹介しておきましょう。
室谷代表取締役openai/whisper(公式オープンソース)は当然として、実用的なのはPyDub組み合わせや、長尺音声を自動分割してWhisper APIに投げるラッパー系のリポジトリですよね。
テキトー教師.AI認定講師OpenAIの公式CookbookレポジトリにもWhisperの活用例が多数あります。議事録作成から、音声データセット作成まで、実際のコードが公開されているので参考にしやすいと思いますよ。
室谷代表取締役ローカルでWhisperを動かしたい場合は
ただし、large-v3モデルを使うとVRAMが10GB近く必要になるので、スペックには注意が必要です。
openai-whisper パッケージをpipでインストールして使います。GPU(CUDA対応)があれば高速処理できますが、CPU環境でも動きます。ただし、large-v3モデルを使うとVRAMが10GB近く必要になるので、スペックには注意が必要です。
よくある質問(FAQ)
室谷代表取締役最後に、よくある質問にまとめて答えていきましょう。
テキトー教師.AI認定講師「what is chatgpt whisper」という検索に対する基本的な答えから入りましょうか。
室谷代表取締役Whisperは、OpenAIが2022年9月にオープンソースで公開した音声認識モデルです。680,000時間の多様な音声データで事前学習されており、98言語に対応しています。
ChatGPTと直接の関係はなく、OpenAIが開発した別のAIモデルです。
ChatGPTと直接の関係はなく、OpenAIが開発した別のAIモデルです。
テキトー教師.AI認定講師よく混同されますが、ChatGPTは言語モデル(LLM)で、Whisperは音声認識モデル(STT)です。「ChatGPT Whisper」と言う場合、多くの場合はOpenAI APIのWhisperエンドポイントを使う音声文字起こし機能を指しています。
室谷代表取締役以下によくある質問をまとめました。
Q: ChatGPT PlusでWhisper APIを無料で使えますか?
テキトー教師.AI認定講師使えません。ChatGPT Plusの月額料金はchat.openai.comのUI利用に対するものです。
Whisper APIを含むOpenAI APIは、platform.openai.comから別途課金設定が必要です。
Whisper APIを含むOpenAI APIは、platform.openai.comから別途課金設定が必要です。
Q: Whisperの精度はどのくらいですか?
室谷代表取締役英語では非常に高精度で、WERが数%レベルです。日本語も実用レベルで、静かな環境・クリアな発声であれば誤字はほとんどありません。
ただし、複数人の同時発話や背景ノイズが多い環境では精度が落ちます。
ただし、複数人の同時発話や背景ノイズが多い環境では精度が落ちます。
Q: リアルタイム文字起こしはできますか?
テキトー教師.AI認定講師Whisper APIにはストリーミング機能があります(
リアルタイムの双方向音声会話はOpenAIのRealtime APIが対応しています。
stream=True)。完全リアルタイムというよりは「音声が届いたらすぐ文字にする」に近いです。リアルタイムの双方向音声会話はOpenAIのRealtime APIが対応しています。
Q: 25MBを超える長い音声はどうすればいいですか?
室谷代表取締役PyDubで音声を分割してAPIに投げるのが一番確実です。分割する際は文の途中で切れないよう、無音区間を検出して切ることで精度を保てます。
Q: Whisperで日本語の精度を上げるコツは?
テキトー教師.AI認定講師3つあります。①録音品質を上げる(ヘッドセットやコンデンサーマイク)、②promptパラメータに固有名詞や専門用語を書いておく、③
この3つだけで体感できるくらい変わります。
language="ja" で言語を明示指定する。この3つだけで体感できるくらい変わります。
Q: 翻訳機能はありますか?
室谷代表取締役あります。
ただし現時点では英語への変換のみで、日本語→フランス語のような直接変換はできません。
/v1/audio/translations エンドポイントを使うと、任意の言語の音声を英語に変換できます。ただし現時点では英語への変換のみで、日本語→フランス語のような直接変換はできません。
Q: デモ・テストはどこでできますか?
テキトー教師.AI認定講師OpenAI Platform PlaygroundでWhisper APIのデモを試せます。APIキーがあれば、音声ファイルをアップロードするだけで文字起こし結果を確認できます。
まとめ
室谷代表取締役今回はChatGPTとWhisperの関係から始まり、API実装・議事録自動化・精度改善まで幅広く扱いました。一番大事なポイントを整理すると・・・
テキトー教師.AI認定講師WhisperはChatGPTの一部ではなく、OpenAIが別に開発した音声認識専用のモデルである、というのが出発点ですよね。そこが混乱の根本にあるので。
室谷代表取締役2026年現在は、whisper-1だけでなく gpt-4o-transcribe と gpt-4o-mini-transcribe という新しいモデルも選べます。用途によって使い分けるのがポイントです。
テキトー教師.AI認定講師実用面では、Whisper APIで文字起こし→GPTで構造化整形、という2段ステップが議事録自動化の基本です。これをn8nやPythonスクリプトで自動化すると、音声データがそのままビジネスの情報資産になっていきます。
室谷代表取締役.AIコミュニティでも「Whisperで議事録を自動化しました!」という事例が増えていますよ。技術的なハードルは想像よりずっと低くて、Pythonが少し書けるなら数十行のコードで実現できます。
ぜひ試してみてください。
ぜひ試してみてください。
テキトー教師.AI認定講師.AI(ドットエーアイ)でもWhisperを活用したAI業務自動化の講座を提供しています。コードを書かずにn8nでWhisperを使う方法も扱っていますので、興味のある方はチェックしてみてください。









