ChatGPT × VOICEVOXを連携させてAI音声会話ボットを作る方法【2026年最新】Pythonコード付き完全解説
 室谷代表取締役
室谷代表取締役今回はChatGPTとVOICEVOXを連携させる話をしましょう。これ、技術的に面白いテーマで・・・コミュニティでも「試してみたい」という声をよく聞くんですよね。
 テキトー教師.AI認定講師
テキトー教師.AI認定講師そうなんですよ。.AI(ドットエーアイ)の講座でも、プログラミング入門の受講生さんがこのテーマに興味を持つケースが多くて。
「ChatGPTの回答を好きなキャラクターに読み上げてもらいたい」という発想は自然ですよね。
「ChatGPTの回答を好きなキャラクターに読み上げてもらいたい」という発想は自然ですよね。
室谷代表取締役で、実際にやってみると「あ、思ったより簡単だ」ってなるんですよ。VOICEVOXがREST APIを公開していて、ローカルで動かせるので・・・ChatGPTのAPIと組み合わせるだけで音声会話ボットが作れます。
テキトー教師.AI認定講師整理すると、この記事で作るのは「ずんだもんやその他のキャラクターがChatGPTの回答を読み上げてくれるPythonスクリプト」ですね。必要なものは2つだけ:OpenAI APIキーと、ローカルで動かすVOICEVOX。
室谷代表取締役そうです。ユーザーがテキストを入力→ChatGPT APIが回答を生成→その回答をVOICEVOX APIに送って音声化→音声ファイルを再生、という流れです。
シンプルですが、応用次第でかなり面白いものが作れます。
シンプルですが、応用次第でかなり面白いものが作れます。
テキトー教師.AI認定講師この記事ではPythonでの実装を中心に、環境構築から実際に声が出るところまでを一通り解説していきます。VOICEVOXは無料で使えて、商用・非商用問わず利用できる(各キャラクターの利用規約に従う前提で)ので、個人のプロジェクトでも気軽に試せます。
VOICEVOXとは?特徴・キャラクター・利用規約を整理する
室谷代表取締役まずVOICEVOXについて整理しましょう。知らない人のために言うと、VOICEVOXは無料で使えるテキスト音声合成ソフトウェアで、オープンソースとして公開されています。
テキトー教師.AI認定講師最大の特徴は「ずんだもん」「四国めたん」「春日部つむぎ」など、個性的なキャラクターボイスが最初から用意されているところですね。キャラクターごとに声の雰囲気が全然違うので、用途に合わせて選べます。
室谷代表取締役さらに言うと、VOICEVOXはREST APIとしても動作するんですよ。デスクトップアプリを起動すると、バックグラウンドでHTTPサーバーが立ち上がって、
http://127.0.0.1:50021 でAPIにアクセスできるようになります。テキトー教師.AI認定講師ここがポイントで、Pythonからrequestsライブラリで普通にHTTPリクエストを送るだけで音声合成ができる。難しい設定は何もいらないんですよ。
講座でも「APIって難しそう」と思っていた受講生さんが、VOICEVOXのAPIを触って「あ、こんな感じか」と理解してくれることが多いです。
講座でも「APIって難しそう」と思っていた受講生さんが、VOICEVOXのAPIを触って「あ、こんな感じか」と理解してくれることが多いです。
室谷代表取締役2026年4月時点でのバージョンはv0.25.1です。Windows / Mac / Linux の全プラットフォームに対応しています。
VOICEVOXで使える主なキャラクター
各キャラクターには複数の「スタイル」(感情・話し方のバリエーション)があります。
| キャラクター名 | 声の特徴 |
|---|---|
| ずんだもん | 子供っぽい高めの声 |
| 四国めたん | はっきりした芯のある声 |
| 春日部つむぎ | 穏やかな女性の声 |
| 波音リツ | クールな女性の声 |
| 雨晴はう | 元気な女性の声 |
| WhiteCUL | 大人っぽい女性の声 |
| 後鬼 | 低い男性の声 |
テキトー教師.AI認定講師話者IDはVOICEVOXを起動した状態で
http://127.0.0.1:50021/speakers にアクセスすると全リストを取得できます。スタイルごとにIDが異なるので、「ずんだもんのノーマル」「ずんだもんのあまあま」といった細かい指定もできます。室谷代表取締役ちなみにVOICEVOX Nemoというキャラクターのいない音声ライブラリもあって、これはより汎用的な音声合成用途向けです。商用プロダクトに組み込む場合はNemoが使いやすいケースもありますね。
利用規約の要点
テキトー教師.AI認定講師利用する前に規約は確認しておきましょう。VOICEVOXソフトウェア自体は商用・非商用問わず無料で利用できます。
ただし、各キャラクターの音声ライブラリにはそれぞれ個別の規約があります。
ただし、各キャラクターの音声ライブラリにはそれぞれ個別の規約があります。
室谷代表取締役重要なのは「VOICEVOXを利用したことがわかるクレジット表記が必要」という点です。個人開発の作品でも、公開する場合はクレジットを入れましょう。
テキトー教師.AI認定講師環境構築:OpenAI APIキーの取得とVOICEVOXのインストール
室谷代表取締役環境構築の話をしましょう。必要なのは2つです。
OpenAI APIキーとVOICEVOXのインストール。順番にやっていきましょう。
OpenAI APIキーとVOICEVOXのインストール。順番にやっていきましょう。
テキトー教師.AI認定講師受講生さんに一番ハマるのがこのセットアップ段階で、「VOICEVOXをインストールしたのに起動を忘れていた」というケースが多いです(笑)。APIは起動中のVOICEVOXに接続しに行くので、実行前に必ずVOICEVOXを起動しておく必要があります。
OpenAI APIキーの取得
室谷代表取締役OpenAI APIキーはplatform.openai.comでアカウントを作成して取得します。2026年4月時点の最新モデルはGPT-5.4です。
APIの料金体系は以下の通りです。
APIの料金体系は以下の通りです。
| モデル | 入力(1Mトークン) | 出力(1Mトークン) |
|---|---|---|
| GPT-5.4 | $2.50 | $15.00 |
| GPT-5.4 mini | $0.75 | $4.50 |
| GPT-5.4 nano | $0.20 | $1.25 |
テキトー教師.AI認定講師個人で試す分にはGPT-5.4 nanoかGPT-5.4 miniで十分です。VOICEVOXとの連携だと1回の会話で使うトークン数はそれほど多くないので、かなりコストを抑えられます。
室谷代表取締役MYUUUではAPIコストの管理を結構シビアにやっていて・・・会話ボット系は基本的にminiクラスのモデルを使いますね。速度も速いし、コスト差が大きい。
VOICEVOXのインストール
テキトー教師.AI認定講師インストールの手順はシンプルです。
- 公式サイトにアクセスして「ダウンロード」をクリック
- お使いのOSに対応するインストーラーをダウンロード
- インストーラーを実行してインストール完了
- VOICEVOXを起動(起動するとバックグラウンドでAPIサーバーが立ち上がる)
- ブラウザで
http://127.0.0.1:50021/docsにアクセスしてAPIドキュメントを確認
室谷代表取締役5番のAPIドキュメント確認がポイントです。SwaggerUIでAPIの全エンドポイントが見れて、ブラウザ上で試し打ちもできます。
「とりあえず声を出してみたい」という人はここから始めると直感的にわかります。
「とりあえず声を出してみたい」という人はここから始めると直感的にわかります。
テキトー教師.AI認定講師Macの場合、GPUモードには非対応なのでCPUモードになります。音声生成に少し時間がかかりますが、テキストが短ければそれほど気にならないレベルです。
Python環境のセットアップ
室谷代表取締役Pythonは3.9以上を使ってください。必要なライブラリは3つだけです。
bash
pip install openai requests pyaudiopyaudioは音声ファイルを再生するために使います。環境によってはインストールが少し手こずることがあります。
Macの場合は以下のコマンドを先に実行しておくとスムーズです。
Macの場合は以下のコマンドを先に実行しておくとスムーズです。
bash
# Mac(Homebrewが入っている場合)
brew install portaudio
pip install pyaudioWindowsの場合、pyaudioのインストールでエラーが出ることがあります。そのときは
pip install pipwin のあとに pipwin install pyaudio を試してみてください。テキトー教師.AI認定講師音声の再生にpyaudioを使わずに済む方法として、生成した.wavファイルを保存してからOSのデフォルト再生アプリで開く方法もあります。コードをシンプルにしたい場合はそっちの方が楽なケースもありますね。
VOICEVOXのAPIの仕組みを理解する
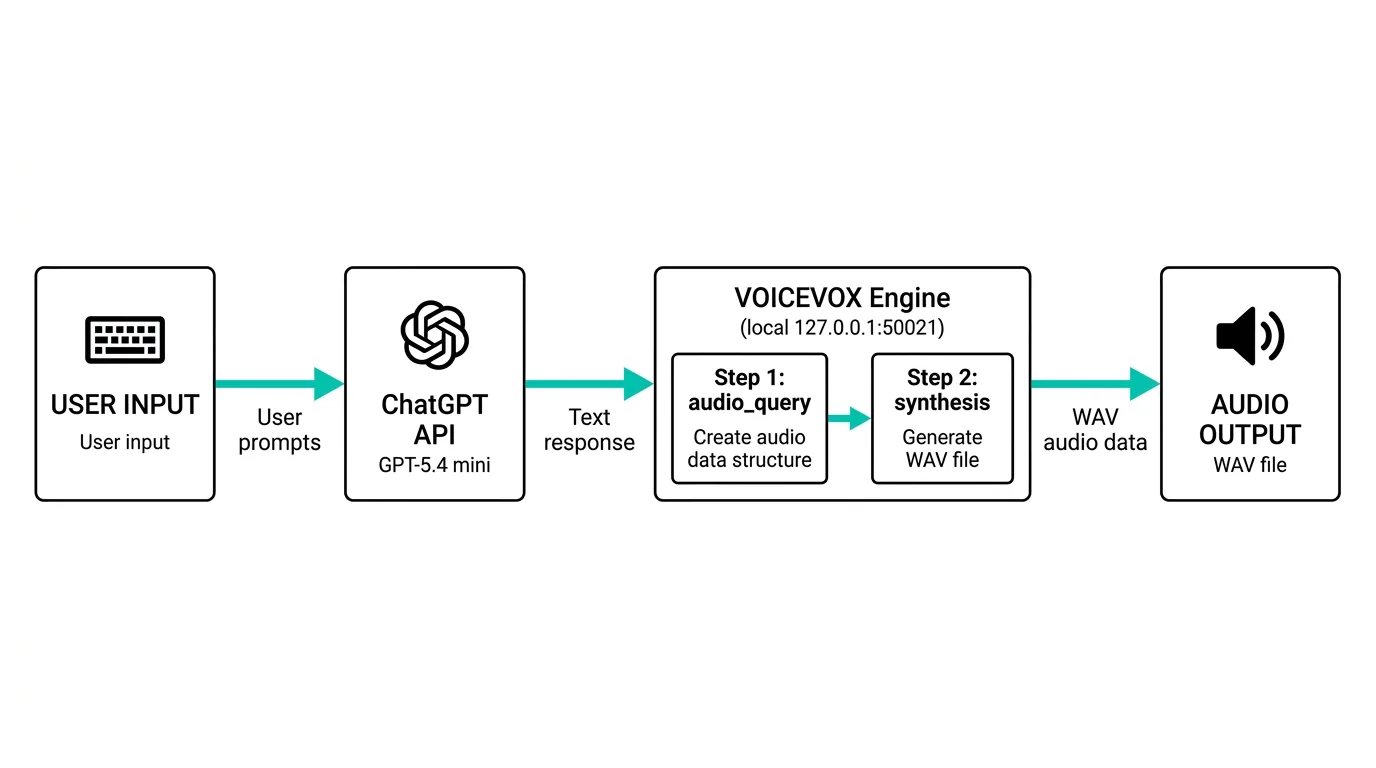
室谷代表取締役コードを書く前に、VOICEVOXのAPIの仕組みを理解しておきましょう。知っておくと後でトラブルシューティングがしやすくなります。
テキトー教師.AI認定講師VOICEVOXで音声合成を行うには、基本的に2つのAPIを順番に叩きます。これが最初わかりにくいところなんですが、理解すると「なるほど」ってなります。
室谷代表取締役2ステップ方式ですね。まずテキストから「音声合成クエリ」を作成して、次にそのクエリを使って音声ファイルを生成する。
音声合成の2ステップ
テキトー教師.AI認定講師具体的には、こういう流れです。
POST /audio_query: テキストを送ると、読み方・アクセント・話速などのパラメータが入ったクエリJSONが返ってくるPOST /synthesis: ↑のクエリJSONを送ると、音声データ(.wav)が返ってくる
室谷代表取締役2ステップを踏むのは、間に「調整」が入れられるからなんですよね。audio_queryで返ってきたJSONの
speedScale(話速)や pitchScale(音高)を編集してからsynthesisに渡せば、速度や高さを自由に変えられます。テキトー教師.AI認定講師VOICEVOX engineのGitHubリポジトリのREADMEにあるサンプルコードで、実際の使い方が確認できます。
bash
# ①テキストから音声合成クエリを生成
curl -s -X POST "127.0.0.1:50021/audio_query?speaker=1" \
--get --data-urlencode text@text.txt > query.json
# ②クエリから音声ファイルを生成(サンプリングレート24000Hz)
curl -s -H "Content-Type: application/json" \
-X POST -d @query.json \
"127.0.0.1:50021/synthesis?speaker=1" > audio.wavspeaker=1 というのが話者IDです。テキトー教師.AI認定講師注意点として、生成される音声はサンプリングレートが24000Hzと少し特殊です。一部の音声プレーヤーでは再生できない場合があります。
Pythonで再生する場合は後述のコードで対応します。
Pythonで再生する場合は後述のコードで対応します。
室谷代表取締役VOICEVOXのエンジンはHTTPサーバーとして動くので、Dockerを使ってクラウドサーバーにVOICEVOXを立てる構成も取れます。詳細はVOICEVOX engineのGitHubに記載されています。
ChatGPT APIとVOICEVOX APIを組み合わせる:基本コード
室谷代表取締役では実際にコードを書いていきましょう。まずは最小構成で「ChatGPTの回答をVOICEVOXが読み上げる」スクリプトを作ります。
テキトー教師.AI認定講師最小構成を先に作って動かしてから拡張するのが一番学習効率がいいです。最初から全部作ろうとするとどこでエラーが出たかわからなくなりますからね(笑)。
基本コード(最小構成)
python
import os
import json
import requests
import pyaudio
import wave
import io
from openai import OpenAI
# --- 設定 ---
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY", "your-api-key-here")
VOICEVOX_URL = "http://127.0.0.1:50021"
SPEAKER_ID = 3 # ずんだもん(ノーマル)
MODEL = "gpt-5.4-mini" # GPT-5.4 miniを使用
client = OpenAI(api_key=OPENAI_API_KEY)
def chat_with_gpt(user_message: str, conversation_history: list) -> str:
conversation_history.append({"role": "user", "content": user_message})
response = client.chat.completions.create(
model=MODEL,
messages=conversation_history,
max_tokens=500
)
assistant_message = response.choices[0].message.content
conversation_history.append({"role": "assistant", "content": assistant_message})
return assistant_message
def text_to_speech_voicevox(text: str, speaker: int = SPEAKER_ID) -> bytes:
# ステップ1: 音声合成クエリの生成
query_response = requests.post(
f"{VOICEVOX_URL}/audio_query",
params={"speaker": speaker, "text": text}
)
query_response.raise_for_status()
audio_query = query_response.json()
audio_query["speedScale"] = 1.1 # 少し速めに
# ステップ2: 音声ファイルの生成
synthesis_response = requests.post(
f"{VOICEVOX_URL}/synthesis",
params={"speaker": speaker},
headers={"Content-Type": "application/json"},
data=json.dumps(audio_query)
)
synthesis_response.raise_for_status()
return synthesis_response.content
def play_audio(wav_bytes: bytes):
wav_file = wave.open(io.BytesIO(wav_bytes))
p = pyaudio.PyAudio()
stream = p.open(
format=p.get_format_from_width(wav_file.getsampwidth()),
channels=wav_file.getnchannels(),
rate=wav_file.getframerate(),
output=True
)
chunk = 1024
data = wav_file.readframes(chunk)
while data:
stream.write(data)
data = wav_file.readframes(chunk)
stream.stop_stream()
stream.close()
p.terminate()
wav_file.close()
def main():
system_prompt = "あなたは親切なアシスタントです。回答は100文字以内にしてください。音声読み上げ用なので記号や絵文字は使わないでください。"
conversation_history = [{"role": "system", "content": system_prompt}]
print("ChatGPT x VOICEVOX 音声会話ボット")
print("終了するには quit と入力してください")
while True:
user_input = input("あなた: ").strip()
if user_input.lower() == "quit":
break
if not user_input:
continue
reply = chat_with_gpt(user_input, conversation_history)
print(f"ChatGPT: {reply}")
wav_data = text_to_speech_voicevox(reply)
play_audio(wav_data)
if __name__ == "__main__":
main()このコードで基本的な動作は全部カバーしています。conversation_historyで会話履歴を持っているので、文脈を踏まえた会話もできます。
テキトー教師.AI認定講師text_to_speech_voicevox() 関数で2ステップのAPIコールを行っています。audio_queryでクエリを作って、synthesisで音声を生成する流れです。speedScale を1.1にしているので、デフォルトより少し速い話し方になります。室谷代表取締役環境変数にAPIキーをセットする場合はこうすればOKです。
bash
# macOS / Linux
export OPENAI_API_KEY="sk-xxxxxxxxxxxx"
python3 voicevox_chatgpt.pyコード内にAPIキーをハードコーディングするのは絶対やめましょう。GitHubに間違えてアップしてしまうと大変なことになります。
環境変数か
環境変数か
.env ファイルで管理するのが鉄則です。キャラクターを切り替える:話者IDの指定とスタイル変更
室谷代表取締役基本コードが動いたら、次はキャラクターを変えてみましょう。話者IDを変えるだけでキャラクターが変わります。
テキトー教師.AI認定講師これが面白いところで、同じ文章でも話者を変えると全然印象が違う。受講生さんがいろんなキャラクターを試して「ずんだもん声で技術解説するのが一番好き」みたいな感想を言うのが定番ですよ(笑)。
使用可能な話者IDを確認する
python
import requests
def get_speakers():
response = requests.get("http://127.0.0.1:50021/speakers")
speakers = response.json()
for speaker in speakers:
print(f"■ {speaker['name']}")
for style in speaker['styles']:
print(f" - {style['name']} : ID={style['id']}")
get_speakers()このスクリプトを動かすと、全キャラクターとそのスタイルIDが一覧表示されます。ずんだもんのスタイルは「ノーマル」「あまあま」「ツンツン」「ヒソヒソ」などがあって・・・用途に合わせて選べます。
テキトー教師.AI認定講師応用として「返答の内容に合わせてスタイルを変える」という実装も面白いですよ。ChatGPTの回答が簡潔なら速いスタイル、詳細な説明なら落ち着いたスタイルに切り替えるとか。
複数キャラクターで掛け合いをさせる
室谷代表取締役もう少し発展した使い方として、複数のキャラクターに掛け合いをさせる実装も面白いですね。2つの話者IDを用意して、ロールを分けて会話させる。
テキトー教師.AI認定講師実際にやってみると結構面白くて、「AIキャスター2人が議論する」みたいなコンテンツが作れます。.AIのコミュニティでもこういうアイデアを実装して見せてくれるメンバーさんがいますね。
python
def generate_dialogue(topic: str):
"""2キャラクターで指定トピックについて掛け合いを生成する"""
system_prompt = """次のトピックについて、2人のキャラクターが話すセリフを生成してください。
形式:キャラA: セリフ / キャラB: セリフ(各50文字以内、記号なし)"""
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": topic}
]
)
dialogue_text = response.choices[0].message.content
for line in dialogue_text.strip().split("\n"):
if line.startswith("キャラA:"):
text = line.replace("キャラA:", "").strip()
speaker_id = 2 # 四国めたん
elif line.startswith("キャラB:"):
text = line.replace("キャラB:", "").strip()
speaker_id = 3 # ずんだもん
else:
continue
if text:
wav = text_to_speech_voicevox(text, speaker=speaker_id)
play_audio(wav)このコードで「今日の天気」「AIの未来」みたいなトピックを渡すと、2人のキャラクターが掛け合いする音声が生成されます。MYUUUのメンバーがポッドキャスト的なコンテンツをAIで作る実験をしていて・・・この仕組みを応用していたりします。
エラーハンドリングと実用的な改善ポイント
室谷代表取締役基本動作が確認できたら、次は実用レベルに上げていきましょう。エラーハンドリングが甘いと、VOICEVOXが起動していない状態で実行したときにそのままクラッシュします。
テキトー教師.AI認定講師ここが本質なんですよ。「動けばOK」な段階から、「安定して動く」段階へのステップアップですね。
講座でも「エラーハンドリングを入れたら突然プロっぽくなった」と言う受講生さんが多いです。
講座でも「エラーハンドリングを入れたら突然プロっぽくなった」と言う受講生さんが多いです。
よくあるエラーと対処
室谷代表取締役この連携でよく出るエラーをまとめると、こうなります。
| エラー内容 | 原因 | 対処 |
|---|---|---|
ConnectionRefusedError | VOICEVOXが起動していない | VOICEVOXを起動してから再実行 |
401 Unauthorized | OpenAI APIキーが無効 | APIキーを確認・更新 |
429 Too Many Requests | APIのレート制限超過 | 間隔を空けてリトライ |
HTTPError 422 | VOICEVOXへのリクエスト形式が不正 | textパラメータが空でないか確認 |
wave.Error | 音声ファイルが壊れている | synthesis APIの戻り値を確認 |
テキトー教師.AI認定講師ConnectionRefusedError が一番多いです。「VOICEVOXを忘れずに起動してください」という注意書きをスクリプトの冒頭に入れておくと親切ですね。エラーハンドリングを追加した改善版
python
import time
def text_to_speech_voicevox_safe(text: str, speaker: int = SPEAKER_ID) -> bytes | None:
"""エラーハンドリング付きのVOICEVOX音声合成"""
if not text or not text.strip():
return None
try:
query_response = requests.post(
f"{VOICEVOX_URL}/audio_query",
params={"speaker": speaker, "text": text},
timeout=10 # タイムアウト設定
)
query_response.raise_for_status()
audio_query = query_response.json()
audio_query["speedScale"] = 1.1
synthesis_response = requests.post(
f"{VOICEVOX_URL}/synthesis",
params={"speaker": speaker},
headers={"Content-Type": "application/json"},
data=json.dumps(audio_query),
timeout=30
)
synthesis_response.raise_for_status()
return synthesis_response.content
except requests.exceptions.ConnectionError:
print("[ERROR] VOICEVOXに接続できません。VOICEVOXが起動しているか確認してください。")
return None
except requests.exceptions.Timeout:
print("[ERROR] VOICEVOXとの通信がタイムアウトしました。")
return None
except requests.exceptions.HTTPError as e:
print(f"[ERROR] VOICEVOX APIエラー: {e}")
return None
def chat_with_gpt_safe(user_message: str, conversation_history: list) -> str | None:
"""エラーハンドリング付きのChatGPT API呼び出し"""
try:
conversation_history.append({"role": "user", "content": user_message})
response = client.chat.completions.create(
model=MODEL,
messages=conversation_history,
max_tokens=500,
timeout=30
)
assistant_message = response.choices[0].message.content
conversation_history.append({"role": "assistant", "content": assistant_message})
return assistant_message
except Exception as e:
print(f"[ERROR] ChatGPT APIエラー: {e}")
# エラーが出た場合は最後のユーザーメッセージを履歴から削除
if conversation_history and conversation_history[-1]["role"] == "user":
conversation_history.pop()
return Nonetimeoutを設定しているのがポイントで、応答が来ない場合に無限に待ち続けるのを防げます。VOICEVOX側はaudio_queryが10秒、synthesisが30秒を目安にしています。
テキトー教師.AI認定講師OpenAIのAPIで
429 Too Many Requestsが出た場合のリトライ処理も入れておくと安心です。python
import time
from openai import RateLimitError
def chat_with_retry(user_message: str, conversation_history: list, max_retries: int = 3) -> str | None:
"""レート制限対応のリトライ付きChatGPT API呼び出し"""
for attempt in range(max_retries):
result = chat_with_gpt_safe(user_message, conversation_history)
if result is not None:
return result
if attempt < max_retries - 1:
wait_time = (attempt + 1) * 5 # 5秒、10秒、15秒と段階的に待つ
print(f"リトライ待機中... ({wait_time}秒)")
time.sleep(wait_time)
return None実際にプロダクトに組み込む場合は、このあたりのエラーハンドリングをしっかり書いておかないと、ユーザー体験がガタガタになります。MYUUUのプロダクトでも、最初のバージョンはエラー処理が甘くてよく怒られました(笑)。
音声パラメータの調整:速度・音高・抑揚をカスタマイズ
室谷代表取締役VOICEVOXの面白いところの一つが、音声パラメータを細かく調整できることですね。デフォルトのまま使う人が多いんですが、チューニングすると一気に自然な感じになります。
テキトー教師.AI認定講師これ、受講生さんに見せると反応がいいんですよ。「同じ声なのに全然違う」って。
音声のパラメータを変えることで、キャラクターの個性をさらに引き出せます。
音声のパラメータを変えることで、キャラクターの個性をさらに引き出せます。
調整可能なパラメータ一覧
audio_queryで取得できるJSONには、以下のパラメータが含まれています。
| パラメータ | 説明 | デフォルト値 | 推奨範囲 |
|---|---|---|---|
speedScale | 話速 | 1.0 | 0.5〜2.0 |
pitchScale | 音高 | 0.0 | -0.15〜0.15 |
intonationScale | 抑揚 | 1.0 | 0.0〜2.0 |
volumeScale | 音量 | 1.0 | 0.0〜2.0 |
prePhonemeLength | 開始無音 | 0.1 | 0.0〜1.5 |
postPhonemeLength | 終了無音 | 0.1 | 0.0〜1.5 |
室谷代表取締役intonationScale を0にすると棒読みに、2.0にすると強烈な抑揚になります。ずんだもんの元気な感じを強調したい場合は1.2〜1.5くらいがちょうどいい印象ですね。テキトー教師.AI認定講師pitchScale は声の高さです。プラスにすると高くなり、マイナスにすると低くなります。男性キャラクターをさらに低くするとか、女性キャラクターを少し落ち着いた声にするとか、用途に合わせて調整できます。
ユースケース別のパラメータ設定例
python
# ナレーション用(落ち着いた読み上げ)
NARRATION_PARAMS = {
"speedScale": 0.95,
"pitchScale": -0.02,
"intonationScale": 0.85,
"volumeScale": 1.0
}
# チャットボット用(元気でフレンドリー)
CHATBOT_PARAMS = {
"speedScale": 1.1,
"pitchScale": 0.0,
"intonationScale": 1.2,
"volumeScale": 1.0
}
# ニュース読み上げ用(明瞭で聞き取りやすい)
NEWS_PARAMS = {
"speedScale": 1.0,
"pitchScale": -0.01,
"intonationScale": 0.9,
"volumeScale": 1.1
}
def apply_voice_params(audio_query: dict, params: dict) -> dict:
"""音声パラメータを適用する"""
audio_query.update(params)
return audio_queryユースケースによってプリセットを用意しておくと便利です。MYUUUでも社内ツールで音声読み上げを使う場合、この手のプリセットを複数用意しています。
応用事例:YouTube動画・ポッドキャスト・業務ツールへの展開
室谷代表取締役基本実装ができたら、次は「何に使うか」が大事なんですよね。ChatGPT × VOICEVOXの組み合わせは、使い方次第でいろんな用途に展開できます。
テキトー教師.AI認定講師教育系で言えば、「AIがテキストを読み上げながら解説する」という使い方が自然ですね。教材のナレーションをAIで自動生成するとか。
活用事例1:YouTube動画のナレーション自動生成
室谷代表取締役一番多い使い方が、YouTube動画のナレーションへの活用です。スクリプトを書いてChatGPTに台本を洗練させてもらい、VOICEVOXで読み上げて動画に当てはめる流れです。
テキトー教師.AI認定講師.AIのコミュニティでも、この方法でチャンネルを運営している方がいますね。「1日1動画」のペースで出し続けているのに、撮影も声の収録もゼロという。
室谷代表取締役台本の自動生成から音声ファイルの書き出しまでをPythonで一本化すると、かなり効率化できます。
python
def generate_narration_script(topic: str) -> str:
"""トピックからYouTube動画の台本を生成する"""
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": f"""以下のトピックについて、YouTube動画の台本を生成してください。
トピック: {topic}
要件:
- 3〜5分程度(文字数1000〜1500字)
- 音声読み上げ向けなので句読点を多め、記号は使わない
- 導入・本編・まとめの構成で
- 語り口はカジュアルかつ知的に"""
}]
)
return response.choices[0].message.content
def save_as_wav(wav_bytes: bytes, filename: str):
"""WAVファイルとして保存する"""
with open(filename, 'wb') as f:
f.write(wav_bytes)
print(f"音声ファイルを保存しました: {filename}")台本が長い場合は段落ごとに分割して音声合成し、後で動画編集ソフトで結合するのが実用的です。一度に長いテキストをVOICEVOXに送ると処理が重くなることがあります。
活用事例2:業務レポートの読み上げ
室谷代表取締役ビジネス用途で面白い使い方が、日次レポートや分析結果の音声読み上げです。毎朝KPIレポートを音声で聞けると、移動中や作業中でも情報をインプットできます。
テキトー教師.AI認定講師MYUUUさんで実際にやっているんですか?
室谷代表取締役試験的にはやっていますね・・・Slackで毎朝サマリーが来るんですが、それをそのままVOICEVOXで読み上げてPodcastアプリに自動配信するようにして。通勤中に聞けるようにしてみています。
テキトー教師.AI認定講師それは面白いですね。ChatGPTで「箇条書きのレポートを読み上げ向けの文章に変換する」というワンクッションを入れると、さらに聞き取りやすくなります。
活用事例3:語学学習アシスタント
室谷代表取締役海外でも注目されている使い方が、語学学習への応用です。英語のフレーズを入力したら日本語で解説して読み上げてくれる、みたいな。
テキトー教師.AI認定講師このあたりはWHISPER APIと組み合わせるとさらに完成度が上がりますね。ユーザーが英語で話す→WhisperAPIが文字起こし→ChatGPTが日本語で解説生成→VOICEVOXが読み上げ、という流れ。
室谷代表取締役WhisperAPIはOpenAIが提供している音声→テキスト変換APIです。マイクからの入力をリアルタイムでChatGPTに渡す構成が作れます。
VOICEVOXとの組み合わせで完全な音声会話システムができますね。
VOICEVOXとの組み合わせで完全な音声会話システムができますね。
よくあるトラブルと解決方法
テキトー教師.AI認定講師最後に、よくあるトラブルと解決方法をまとめておきましょう。これが一番役立つ情報だったりします。
室谷代表取締役「動かない」となったときに原因を特定できるかどうかで、時間のロスが全然違いますからね。
トラブルシューティングチェックリスト
テキトー教師.AI認定講師VOICEVOXが関連するエラーの場合、まずこのチェックをしてみてください。
- VOICEVOXのデスクトップアプリが起動しているか
- ブラウザで
http://127.0.0.1:50021/docsにアクセスできるか - Pythonからの接続をブロックするファイアウォールがないか
室谷代表取締役2番が一番簡単な確認方法ですね。ブラウザで開けるならAPIは生きているということです。
テキトー教師.AI認定講師OpenAI APIのエラーはだいたい認証周りです。APIキーが正しくセットされているか、APIキーに残高があるかを確認してください。
pyaudioの代替:simpleaudioを使う
室谷代表取締役pyaudioのインストールがどうしてもうまくいかない環境向けに、simpleaudioという代替ライブラリもあります。
bash
pip install simpleaudiopython
import simpleaudio as sa
def play_audio_simpleaudio(wav_bytes: bytes):
"""simpleaudioで音声ファイルを再生する"""
wave_obj = sa.WaveObject.from_wave_read(wave.open(io.BytesIO(wav_bytes)))
play_obj = wave_obj.play()
play_obj.wait_done() # 再生完了まで待つsimpleaudioはpyaudioよりインストールが簡単なケースが多いです。ただし、こちらもOS依存の部分があるので、万能ではないですが。
テキストが長すぎてVOICEVOXがエラーを出す場合
室谷代表取締役ChatGPTの回答が長すぎるとVOICEVOXが処理しきれないことがあります。その場合はテキストを分割して処理するといいです。
python
def split_text(text: str, max_length: int = 200) -> list[str]:
"""テキストを読点・句点で分割する"""
import re
# 句点・読点で分割
sentences = re.split(r'[。!?\n]', text)
chunks = []
current_chunk = ""
for sentence in sentences:
if not sentence.strip():
continue
if len(current_chunk) + len(sentence) <= max_length:
current_chunk += sentence + "。"
else:
if current_chunk:
chunks.append(current_chunk)
current_chunk = sentence + "。"
if current_chunk:
chunks.append(current_chunk)
return chunks
def speak_long_text(text: str, speaker: int = SPEAKER_ID):
"""長いテキストを分割して読み上げる"""
chunks = split_text(text)
for chunk in chunks:
wav = text_to_speech_voicevox_safe(chunk, speaker)
if wav:
play_audio(wav)200文字あたりを目安に分割するのがちょうどいいと思います。それ以上長いと、音声生成の待ち時間が気になりやすくなります。
まとめ:ChatGPT × VOICEVOXで広がる音声AIの可能性
室谷代表取締役改めて今回の内容を振り返ると、VOICEVOXとChatGPT APIを使えば、比較的少ないコードで音声会話ボットが作れることが確認できましたね。
テキトー教師.AI認定講師重要なポイントをまとめると、こうなります。
- VOICEVOXはローカルで動くREST APIで、音声合成は2ステップ(audio_query → synthesis)
- OpenAI APIの最新モデルGPT-5.4 miniはコスト・速度のバランスが良く、会話ボット用途に向いている
- エラーハンドリングとタイムアウト設定は最初から入れておく
- 音声パラメータ(speedScale、intonationScale等)を調整して自然な読み上げに仕上げる
- 応用次第でYouTubeナレーション、業務レポート読み上げ、語学学習ツールなど幅広く使える
室谷代表取締役個人的に面白いと思っているのは、「ローカルで完結する」という点なんですよね。音声データがクラウドに送られないので、プライバシーに敏感なユースケースでも使いやすい。
テキトー教師.AI認定講師そこは大事ですよね。企業の内部情報を読み上げさせる場合など、クラウド音声合成サービスだと懸念が出るケースでも、VOICEVOXならローカルで完結するのでハードルが下がります。
室谷代表取締役2026年時点でVOICEVOXはv0.25.1まで来ていて、キャラクターも増え続けています。今後さらに音声の品質や種類が充実することが予想されるので、継続的にウォッチしておく価値がありますね。
テキトー教師.AI認定講師.AIのコミュニティでも、VOICEVOXを使ったプロジェクトは定期的に出てくるテーマです。ぜひ試してみて、面白い使い方ができたら共有してほしいですね。
よくある質問(FAQ)
VOICEVOXは商用利用できますか?
テキトー教師.AI認定講師VOICEVOXソフトウェア自体は商用・非商用問わず無料で利用できます。ただし、各キャラクターの音声ライブラリには個別の利用規約があり、商用利用の条件がキャラクターによって異なります。
必ず公式サイトで各キャラクターの規約を確認してください。
必ず公式サイトで各キャラクターの規約を確認してください。
GPT-5.4以外のモデルは使えますか?
室谷代表取締役使えます。
用途に合わせて選んでください。レスポンス速度を最優先にするならnano、回答の品質を重視するならGPT-5.4を選ぶのが基本です。
MODEL 変数を "gpt-5.4" にすればより高性能なモデルが使えますし、"gpt-5.4-nano" にすればさらにコストを下げられます。用途に合わせて選んでください。レスポンス速度を最優先にするならnano、回答の品質を重視するならGPT-5.4を選ぶのが基本です。
Macで音が出ないのですが?
テキトー教師.AI認定講師まず
また、音声データをWAVファイルとして保存してから手動で再生する方法も有効です。
brew install portaudio → pip install pyaudio の順にインストールしてみてください。それでもうまくいかない場合は、simpleaudioライブラリで代替できます。また、音声データをWAVファイルとして保存してから手動で再生する方法も有効です。
VOICEVOXで英語テキストを読ませることはできますか?
室谷代表取締役英語テキストもある程度読めますが、日本語向けに最適化されているため、英語の発音はそれほど自然ではありません。英語テキストの音声合成が必要な場合は、OpenAIのTTS API(
tts-1 モデル)など英語対応の音声合成サービスを使う方が適切です。出典
- VOICEVOX 公式サイト
- VOICEVOX 利用規約
- VOICEVOX 使い方ドキュメント
- VOICEVOX engine GitHub
- OpenAI API 料金ページ
- OpenAI Platform



















