DifyはAIを「学習」させているのか?よくある誤解を解く
 室谷代表取締役
室谷代表取締役DifyでAIチャットボットを作ってみた人から、よく「Difyにドキュメントをアップロードすると、AIが学習するんですよね?」という質問が来るんですよね。
 テキトー教師.AI認定講師
テキトー教師.AI認定講師.AI(ドットエーアイ)のコミュニティのメンバーさんからも同じ質問を本当によくいただきます。「社内の機密資料を学習させたら外に漏れないか心配」という不安とセットで来ることが多いです。
室谷代表取締役これ、根本的に誤解している人が多いんですよ。Difyに資料をアップロードしても、AIモデル自体が「学習」しているわけじゃないんです。
DifyはRAG(Retrieval-Augmented Generation)という仕組みを使っているので、ファインチューニングや事前学習とは全く違う話なんですよね。
DifyはRAG(Retrieval-Augmented Generation)という仕組みを使っているので、ファインチューニングや事前学習とは全く違う話なんですよね。
テキトー教師.AI認定講師そうなんです。「学習させる」という言葉のイメージが一人歩きしているんだと思いますよ。
Stable Diffusionで独自モデルを学習させるとか、LLMをファインチューニングするというのは本当にモデルのパラメータを書き換える話なんですが、DifyのナレッジベースはAIモデルに何も書き込まないです。
Stable Diffusionで独自モデルを学習させるとか、LLMをファインチューニングするというのは本当にモデルのパラメータを書き換える話なんですが、DifyのナレッジベースはAIモデルに何も書き込まないです。
室谷代表取締役本質を言うと、Difyのナレッジ機能は「AIの記憶」ではなく「検索エンジン」に近い仕組みなんですよ。ドキュメントを検索インデックスに変換して、ユーザーが質問したときに関連する部分を取り出してAIに渡すだけです。
テキトー教師.AI認定講師そのあたりの仕組みをちゃんと理解しないまま使い始めると、「なんで覚えてくれないんだろう」「チャットを終了したら忘れてしまった」という問題にハマるんですよね。今回はこの「Difyと学習の関係」を丁寧に解説していきます。
DifyのRAGとは何か:学習ではなく「検索して渡す」仕組み
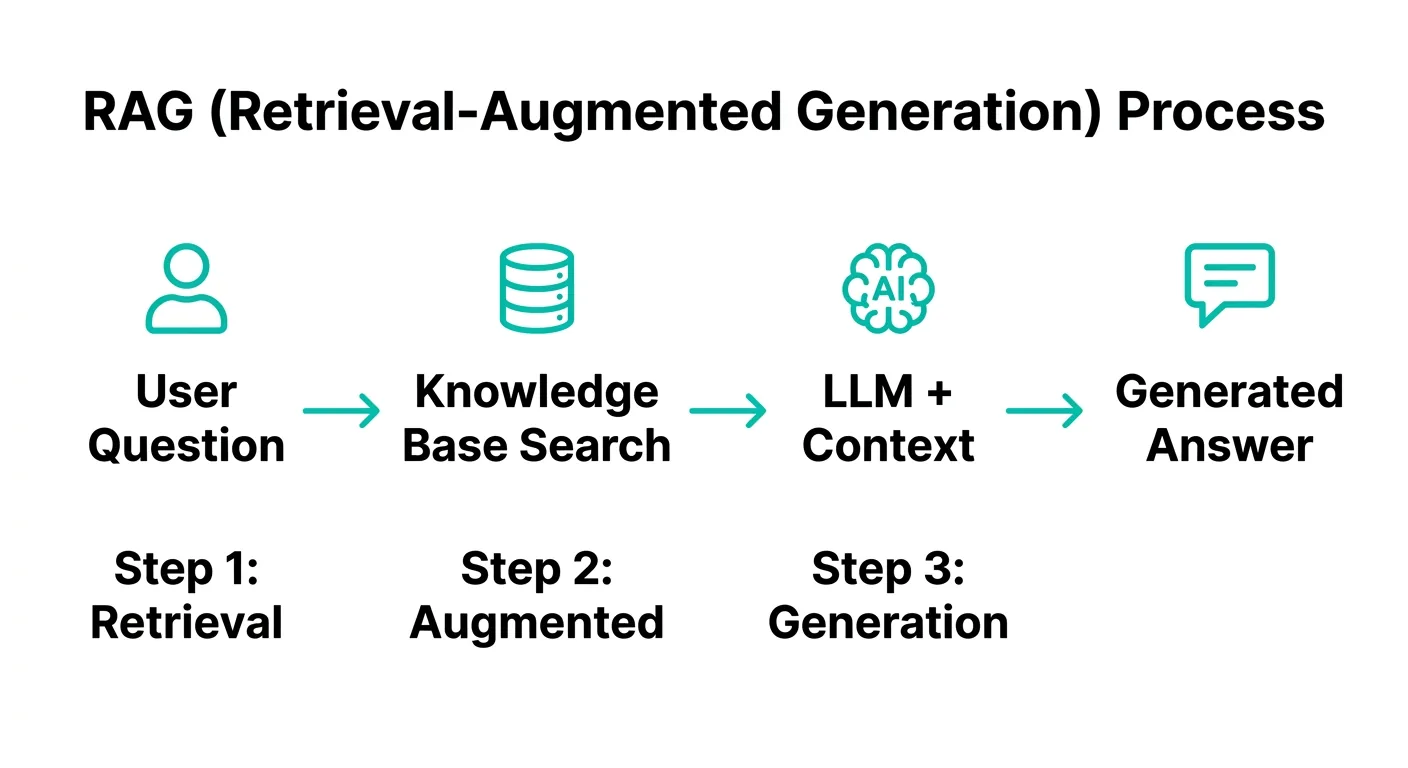
室谷代表取締役まずRAGの話から入りましょう。RAGはRetrieval-Augmented Generationの略で、日本語にすると「検索拡張生成」です。
MYUUUでDifyを使い始めたときに一番最初に理解した概念がこれでした。
MYUUUでDifyを使い始めたときに一番最初に理解した概念がこれでした。
テキトー教師.AI認定講師「検索拡張生成」というと難しく聞こえますが、仕組みは意外とシンプルです。整理するとこういう構造です。
| フェーズ | やること |
|---|---|
| 検索(Retrieval) | ユーザーの質問に関連するドキュメントの断片をナレッジベースから検索する |
| 拡張(Augmented) | 取り出した断片をユーザーの質問に付け加えてLLMに渡す |
| 生成(Generation) | LLMはその拡張されたコンテキストをもとに回答を生成する |
室谷代表取締役要するに、毎回「カンニングペーパーを渡す」みたいなイメージです。試験のたびにメモを見せてあげる感じで、AIのパラメータ自体は何も変わっていないんですよね。
テキトー教師.AI認定講師その例えわかりやすいです。ファインチューニングだと「脳みそに直接書き込む」感じで、RAGは「毎回メモを持たせる」感じですよね。
Difyが採用しているのは後者です。
Difyが採用しているのは後者です。
室谷代表取締役Difyの公式ドキュメントにも明確に書かれているんですが、ナレッジ機能は「LLMに特定分野の情報を文脈として提供し、より正確で関連性の高い回答を実現する仕組み」と説明されています。「学習させる」ではなく「文脈として提供する」という表現を使っているのがポイントです。
テキトー教師.AI認定講師ここ大事です。「文脈として提供する」ということは、その文脈がなければAIは知らないまま、ということでもあります。
毎回ナレッジベースから検索して渡す前提なので、「一度教えたら永遠に覚えている」という状態にはなりません。
毎回ナレッジベースから検索して渡す前提なので、「一度教えたら永遠に覚えている」という状態にはなりません。
RAGとファインチューニングの違い
室谷代表取締役RAGとファインチューニングの違い、これは経営者として結構重要な判断軸なんですよね。ファインチューニングはモデルを書き換えるので、コストも時間もかかる。
RAGはドキュメントを追加するだけだから、即日で運用できる。
RAGはドキュメントを追加するだけだから、即日で運用できる。
テキトー教師.AI認定講師講座でも「どっちを選べばいいですか?」という質問が来るんですが、ほとんどのユースケースではRAGで十分です。社内ドキュメントの検索、FAQ対応、マニュアルへの問い合わせ、これらは全部RAGでカバーできます。
室谷代表取締役ファインチューニングが必要なケースは、特定のトーンや文体を徹底的に覚えさせたいときとか、特殊なドメイン専門用語の使い方をモデルレベルで修正したいときですね。それ以外はRAGの方がコスパも良いし、ドキュメントの更新も柔軟にできます。
テキトー教師.AI認定講師ドキュメントを更新したときの話が大事で、RAGだとナレッジベースのドキュメントを差し替えればすぐ反映されます。ファインチューニングだと再学習が必要になりますから。
| 比較項目 | RAG(Difyナレッジ) | ファインチューニング |
|---|---|---|
| 実装コスト | 低い(ドキュメントをアップロードするだけ) | 高い(GPU、時間、専門知識が必要) |
| 情報更新 | 即時(ドキュメントを差し替えるだけ) | 再学習が必要 |
| 機密データのリスク | 低い(モデルに書き込まれない) | 高い(モデルに埋め込まれる) |
| 精度 | 検索精度に依存 | 学習データの質に依存 |
| 向いているユースケース | 社内FAQ、ドキュメント検索、カスタマーサポート | 文体統一、専門用語修正、特定タスクの最適化 |
室谷代表取締役このテーブルを見てもらえるとわかるんですが、機密データのリスクという観点でもRAGは優れているんですよね。ファインチューニングだとデータがモデルのパラメータに埋め込まれてしまうので、意図せず出力に混入するリスクがある。
RAGはあくまで参照するだけなので、ドキュメントを削除したら参照できなくなります。
RAGはあくまで参照するだけなので、ドキュメントを削除したら参照できなくなります。
テキトー教師.AI認定講師「社内の機密資料を学習させたら情報漏洩しないか」という不安の答えがここにあるんですよ。DifyのRAGはモデルに書き込まない。
だからモデルに情報が漏れるリスクはありません。ただし、Difyのクラウドサービスにデータを置く場合は、プライバシーポリシーをちゃんと確認する必要はありますよね。
だからモデルに情報が漏れるリスクはありません。ただし、Difyのクラウドサービスにデータを置く場合は、プライバシーポリシーをちゃんと確認する必要はありますよね。
室谷代表取締役DifyのナレッジベースでAIに「知識を持たせる」方法
室谷代表取締役では実際にどうやってDifyのナレッジ機能を使うか話しましょう。誤解を整理したところで、正しい使い方を理解しておくのが大事です。
テキトー教師.AI認定講師Difyのナレッジ機能、正式には「Knowledge(ナレッジ)」と呼ばれていますが、ナレッジベースにドキュメントをアップロードする→アプリに接続するという2ステップが基本です。
ナレッジベースの作成手順
テキトー教師.AI認定講師整理すると、ナレッジベースを作ってアプリに繋ぐ基本フローはこうなります。
- DifyのStudioから「Knowledge」をクリック
- 「ナレッジを作成」から新しいナレッジベースを作成
- PDFやMarkdown、テキストファイル等のドキュメントをアップロード
- チャンク分割の設定をする(自動推定または手動設定)
- インデックスモードを選択(ハイクオリティかエコノミー)
- 埋め込みモデルを選択
- 処理が完了したら、アプリの「コンテキスト」にナレッジベースを追加
室谷代表取締役ここで重要なのがチャンク分割とインデックスモードの設定ですね。この2つを適切に設定しないと、後で「知識検索ができない」「ヒットしない」問題が起きます。
テキトー教師.AI認定講師チャンクというのは、アップロードしたドキュメントを分割する単位のことです。Difyはドキュメントを小さな断片(チャンク)に分割してベクトル化するんですが、この分割が適切でないと検索精度が落ちます。
室谷代表取締役ドキュメントの性質によって最適なチャンクサイズが変わるんですよ。社内マニュアルみたいに1項目が短いものは小さいチャンクで良いですが、法律文書とか技術仕様書みたいに文脈が長く繋がるものは大きいチャンクにしないとうまく取れないんですよね。
テキトー教師.AI認定講師インデックスモードは「ハイクオリティ」と「エコノミー」の2種類があって、ハイクオリティはLLMを使ったセマンティック検索、エコノミーはキーワードベースの検索です。精度を求めるならハイクオリティ一択ですが、APIコストがかかります。
室谷代表取締役MYUUUでは基本ハイクオリティを使ってます。エコノミーはコストが低い分、検索精度が落ちるので・・・実際に試してみると明確に差が出るんですよね。
知識検索ができない・ヒットしないときの対処法
テキトー教師.AI認定講師コミュニティのメンバーさんから「Difyのナレッジ機能を設定したのに、AIが知識を参照してくれない」という相談が来ることがあります。これはいくつかのよくある原因があります。
室谷代表取締役「知識検索 できない」「知識検索 ヒットしない」という問題ですね。原因を整理するとこうなります。
| 原因 | 症状 | 対処法 |
|---|---|---|
| インデックスモードがエコノミー | セマンティックな質問に対してヒットしない | ハイクオリティに変更して再インデックス |
| チャンクサイズが大きすぎる | 回答の精度が低い、関係ない内容が混じる | チャンクサイズを小さくして再分割 |
| スコア閾値が高すぎる | 関連するドキュメントがあるのにヒットしない | 検索設定のスコア閾値を下げる |
| ナレッジベースがアプリに接続されていない | 設定したはずなのに参照されない | アプリのコンテキスト設定を確認 |
テキトー教師.AI認定講師一番多いのが4番目の「ナレッジベースがアプリに接続されていない」ケースです。ナレッジベースを作ったけど、アプリの「コンテキスト」に追加するステップを忘れているパターンが本当に多いんですよ(笑)。
室谷代表取締役あとTopKの設定も結構重要です。TopKというのは「ユーザーの質問に対して上位何件のチャンクを返すか」という設定で、これが低いと必要な情報が含まれない可能性があります。
テキトー教師.AI認定講師デフォルトは大体2〜3件になっていることが多いんですが、複雑な質問に答えるためにはもっと多くの断片を取ってきた方が良い場合があります。ただし多すぎるとコンテキストが長くなってAPIコストが上がるトレードオフがあります。
DifyのLLM学習とは?DifyでLLMを「使う」仕組み
室谷代表取締役ここで一度立ち止まって確認したいんですが、「dify llm 学習」というキーワードで調べてくる人が一定数いるんですよね。これはDifyがLLMに何かを学習させるということじゃなくて、「DifyでLLMをどう活用するか学ぶ」という意味で調べている人が多いと思います。
テキトー教師.AI認定講師そうですね。DifyはLLMを学習させるツールではなく、LLMを活用するためのプラットフォームです。
OpenAIのGPT-4.1やAnthropicのClaudeなど、既に学習済みのLLMをDifyのアプリの「エンジン」として使う形ですね。
OpenAIのGPT-4.1やAnthropicのClaudeなど、既に学習済みのLLMをDifyのアプリの「エンジン」として使う形ですね。
室谷代表取締役Difyのモデルプロバイダー設定でAPIキーを入れると、そのLLMをアプリで使えるようになります。これはDifyがLLMを学習させているわけじゃなく、外部のLLM APIを呼び出しているだけです。
テキトー教師.AI認定講師用途によってどのLLMを選ぶかも重要な設定ポイントですよね。MYUUUさんはどのLLMをメインで使っていますか?
室谷代表取締役用途によって変えてますね。複雑な推論が必要なタスクはClaude、一般的なチャットボットはGPT-4o系という感じで・・・最近はコスト最適化でGeminiも積極的に試しています。
テキトー教師.AI認定講師複数のLLMを用途ごとに切り替えられるのがDifyの強みの一つですよね。ワークフローの中でもノードごとに違うモデルを使えるので、コスパと精度のバランスを取りやすいです。
Ollamaを追加できないときの対処法
テキトー教師.AI認定講師「dify ollama 追加 できない」という問題もよくある質問です。OllamaはローカルのLLMを動かすためのツールですが、DifyでOllamaを設定するときに詰まる人が多いんですよ。
室谷代表取締役Ollamaを使いたい場合、Difyをセルフホストしている前提になりますよね。クラウド版のDifyからローカルのOllamaにはアクセスできないので。
テキトー教師.AI認定講師そこが一番の落とし穴で、Dify Cloudを使っている人がOllamaを設定しようとしてもできないんですよ。OllamaはローカルのLLMサーバーなので、セルフホスト版のDifyから接続する形になります。
室谷代表取締役セルフホスト版でもOllamaへの接続でよくあるのが、ネットワークの設定問題です。Dockerで動かしている場合、DifyコンテナからOllamaへのホスト名設定が必要になります。
テキトー教師.AI認定講師具体的には、Docker Compose環境でOllamaを使う場合、
extra_hostsの設定でホストマシンのIPを指定するか、OllamaのエンドポイントURLを正しく設定する必要があります。yaml
# docker-compose.ymlの例(extra_hosts設定)
services:
api:
extra_hosts:
- "host.docker.internal:host-gateway"あとはモデルの名前が完全に一致しているかも確認したほうが良いですね。
llama3じゃなくてllama3:8bみたいに正確なタグが必要な場合があります。Dockerで起動しないときのトラブルシューティング
室谷代表取締役Difyをセルフホストするときの「dify docker 起動 しない」問題も頻繁に相談が来ますね。MYUUUでもオンプレミスでDifyを動かしている顧客の技術サポートをすることがあるんですが、Dockerの問題が一番多いです。
テキトー教師.AI認定講師セルフホスト版のDifyはDockerで起動するんですが、環境によって詰まりポイントが違います。よくある原因を整理しましょう。
| 原因 | 確認方法 | 対処法 |
|---|---|---|
| ポートの競合(80, 443, 5432, 6379) | docker ps または netstat -tulnp | 競合しているポートを止めるかDifyのポートを変更 |
| メモリ不足 | docker stats | スペック確認(最低4GB RAM推奨) |
| .envファイルの設定漏れ | .env.example と .env を比較 | 必須変数を設定 |
| Dockerバージョンが古い | docker --version | 最新のDockerをインストール |
| PostgreSQLの初期化失敗 | docker compose logs db | データボリュームを削除して再起動 |
室谷代表取締役一番多いのがポートの競合ですね。PostgreSQLの5432やRedisの6379が既に別のサービスで使われているケースが多いです。
テキトー教師.AI認定講師docker compose logs でログを確認するのが基本です。どのコンテナが起動失敗しているかを特定するのが最初のステップですね。室谷代表取締役あとよくあるのが、
.envファイルの設定をそのままにしているケース。特にSECRET_KEYをデフォルトのままにして本番運用している人は要注意です・・・セキュリティ面で問題になります。Difyのナレッジ機能でよくある「保存できない」「公開できない」問題
室谷代表取締役「dify 保存 されない」「dify 保存 できない」問題も聞かれることがありますね。これはどんなケースが多いですか?
テキトー教師.AI認定講師アプリの設定を変更したのに保存されないというケースは主に2つのパターンがあります。一つはネットワークの問題でAPIのリクエストがタイムアウトしているケース、もう一つはセッションが切れていて再ログインが必要なケースです。
室谷代表取締役あとはブラウザのキャッシュが原因で古い状態が表示されていることもありますね。実際は保存されているのに、キャッシュで古いバージョンが表示されているパターンです。
テキトー教師.AI認定講師「dify 公開 できない」「dify 公開 しない」問題も似たようなところがあって、アプリの公開ステータスとWebアプリのURLの関係で混乱している人が多いです。
室谷代表取締役Difyのアプリを公開すると「Web App URL」が発行されますが、この設定が正しくないとアクセスできないことがあります。セルフホスト版の場合はドメイン設定も絡んでくるので少し複雑になりますね。
Difyのアノテーションシステム:AIの回答品質を継続的に改善する仕組み
室谷代表取締役ここからが本当に重要な話で、「学習させたい」という気持ちに応える機能があります。それがDifyのアノテーションシステムです。
テキトー教師.AI認定講師アノテーションは「注釈」という意味ですが、DifyのアノテーションシステムはAIの回答を人間が修正して、次から同じ質問が来たときにその修正済み回答を使うようにする仕組みです。
室谷代表取締役これは準「学習」といえる機能ですね。厳密にはLLMのパラメータを変えるわけじゃないんですが、「この質問にはこの回答を出す」というルールを蓄積していく仕組みです。
テキトー教師.AI認定講師整理するとこういう仕組みです。
- AIが回答を出す
- 運用者がその回答を確認し、不適切なら修正する
- 修正した回答をアノテーションとして登録する
- 次回以降、同じまたは類似の質問が来たとき、アノテーションの回答が優先的に使われる
室谷代表取締役ポイントは、アノテーションにも埋め込みモデルを使ってベクトル化しているので、完全に同じ質問じゃなくても「似た質問」に対して適切な回答を返せることです。
テキトー教師.AI認定講師これがDifyの「学習」に最も近い機能ですね。ファインチューニングや事前学習ではなく、「回答例の蓄積」による精度改善です。
コミュニティのメンバーさんにも「AIに正しい回答を教えたい」という場合はアノテーションを使ってくださいとおすすめしています。
コミュニティのメンバーさんにも「AIに正しい回答を教えたい」という場合はアノテーションを使ってくださいとおすすめしています。
室谷代表取締役MYUUUのカスタマーサポートbot的な活用でも、最初の1ヶ月はアノテーションをひたすら積み上げるフェーズが重要です。100件くらいアノテーションが溜まると、回答精度が目に見えて上がってきますよ。
テキトー教師.AI認定講師アノテーションを活用するときのポイントは、回答を修正するだけじゃなく「なぜその回答が正しいか」を踏まえた形で修正することです。AIが類似質問にも対応できるようにするためには、回答の質が重要です。
アノテーションとナレッジベースの使い分け
室谷代表取締役アノテーションとナレッジベース、この2つをどう使い分けるかは結構重要ですね。
テキトー教師.AI認定講師使い分けのポイントはこうです。
| 機能 | 向いているケース |
|---|---|
| ナレッジベース | ドキュメントや資料をもとに回答させたい。情報量が多い。更新頻度が高い |
| アノテーション | 特定の質問に対して決まった回答を出させたい。FAQ的な用途。エッジケースの対応 |
室谷代表取締役両方組み合わせて使うのが一番効果的なんですよね。ナレッジベースで幅広い質問をカバーして、アノテーションで「絶対にこの回答を出したい」という重要なケースを固定する形です。
テキトー教師.AI認定講師例えばカスタマーサポートbotを作るとき、商品の仕様書をナレッジベースに入れて、よくある問い合わせへの模範回答をアノテーションで登録するという組み合わせが強いですよ。
「dify 再学習」「dify 追加学習」とは何か:ナレッジの更新と再インデックス
室谷代表取締役「dify 再 学習」や「dify 追加 学習」というキーワードで調べてくる人の多くは、「ナレッジベースに新しい資料を追加したい」「既存の資料を更新したい」という意図だと思うんですよね。
テキトー教師.AI認定講師おっしゃる通りです。Difyには「再学習」という機能は存在しませんが、ナレッジベースのドキュメントを追加・更新・削除するという操作がそれに相当します。
室谷代表取締役Difyのナレッジ管理では、ドキュメントを後から追加することも、既存のドキュメントを差し替えることも、特定のチャンクだけを修正することもできます。
テキトー教師.AI認定講師ドキュメントを更新するときの注意点は、更新後に自動でインデックスが再生成される設定になっているかどうかです。手動でインデックスを再生成しないといけない場合は、更新しても古い情報が返ってくることがあります。
室谷代表取締役「追加学習」という言葉で捉えると、ナレッジベースにドキュメントを追加するのは本当に気軽にできるんですよ。毎週新しい製品マニュアルができたら追加するとか、社内でFAQが増えたら逐次更新するとか、そういう運用が普通にできます。
テキトー教師.AI認定講師これが従来のファインチューニングとの決定的な違いですよね。ファインチューニングは「再学習」にGPUと時間が必要ですが、DifyのRAGは「ドキュメントを追加→即座に検索対象に」という流れです。
ナレッジベースのドキュメント管理のコツ
室谷代表取締役ドキュメント管理のコツを話すと、まずドキュメントの構造が重要です。Difyは目次や見出しを意識したMarkdown形式のドキュメントが一番精度が高いんですよね。
テキトー教師.AI認定講師PDFでも対応していますが、PDFは中のテキストがきれいに抽出できるかどうかに依存するんです。スキャンPDFとかデザインPDFは文字が認識されない場合があるので、Markdownかテキスト形式の方が確実ですよ。
室谷代表取締役あとは1ファイルに全部の情報を詰め込まない方が良いですね。テーマごとにファイルを分けた方が、チャンク分割の精度が上がります。
テキトー教師.AI認定講師メタデータを設定するのも重要です。Difyのナレッジ管理では各ドキュメントにメタデータ(タグ、カテゴリ、更新日など)を設定できるので、検索時のフィルタリングに使えます。
「2026年のマニュアルのみ検索する」みたいな絞り込みが可能です。
「2026年のマニュアルのみ検索する」みたいな絞り込みが可能です。
Difyで「英語学習ツール」を作る事例:チャットボット学習の具体例
室谷代表取締役ちょっと違う角度の話をすると、「dify 英語 学習」というキーワードで調べてくる人の中には、Difyを使って英語学習ツールを作りたいという意図の人もいますよね。
テキトー教師.AI認定講師はい、これはコミュニティのメンバーさんからもよく聞くユースケースです。Difyで英語学習チャットボットを作るというのは、実際かなり実用的なアプリが作れます。
室谷代表取締役簡単な例を出すと、英語の例文集をナレッジベースに入れて、「この表現を使った例文を見せて」とか「このシチュエーションに合う表現は?」という形で質問できるチャットボットが作れます。
テキトー教師.AI認定講師さらに応用すると、英語の会話練習相手としてのチャットボットも作れます。システムプロンプトで「英語の先生として振る舞い、ユーザーの英語の間違いを優しく指摘してください」という設定をするだけで、会話練習の相手になってくれます。
室谷代表取締役.AI(ドットエーアイ)のコミュニティでもDifyを使った学習支援ツールの事例が出てきていますよ。英語に限らず、特定の試験対策の問題を出してくれるbotとか、専門知識の解説をしてくれるアシスタントとか。
テキトー教師.AI認定講師「dify チャットボット 学習」というキーワードに対する答えとしては、DifyはAI自体を学習させるのではなく、「AIを使った学習支援ツール」を作るためのプラットフォームとして使うのが正解ですね。
Difyを使ったRAG強化:事前学習との違いと実用的な活用法
室谷代表取締役「dify 事前 学習」というワードも気になります。これは「Difyに事前に何かを学習させておきたい」という意図だと思うんですが、実はこれもナレッジベースで実現できるんですよ。
テキトー教師.AI認定講師そうですね。「事前に学習させておく」というのをRAGの文脈で言い換えると「ナレッジベースをあらかじめ充実させておく」ということです。
室谷代表取締役MYUUUがDifyを使い始めた頃に気づいたことなんですが、Difyのナレッジ機能の本質は「マイクロナレッジとAPI」なんですよね。
テキトー教師.AI認定講師このツイートの内容、本当に核心をついていますよね。大きい知識のかたまりをRAGにするんじゃなくて、細かい専門知識をRAG化してAPIで公開するという発想が重要で。
室谷代表取締役例えば、医療系のサービスなら「内科」「外科」「皮膚科」のような大カテゴリ一つをRAGにするのではなく、「風邪の症状と対処法」「インフルエンザとの見分け方」みたいな粒度でナレッジベースを作る。そっちの方が精度が断然高いです。
テキトー教師.AI認定講師これは講座でも強調しているポイントです。ナレッジベースは大きく作ればいいわけじゃなくて、用途に特化させた方が精度が上がります。
室谷代表取締役「dify 自己 学習」というワードで調べてくる人に対して言うと、Difyのアプリが自律的に知識を学習・蓄積していく機能は現時点では基本的にありません。自動化したい場合は、ワークフローやAPIを使って定期的にドキュメントを追加するような仕組みを自分で組む必要があります。
テキトー教師.AI認定講師ただし、アノテーションを使えば「良い回答を蓄積していく」という形での準学習は実現できます。完全自動ではないですが、運用しながら精度を上げていくことは可能です。
Difyの強化学習・機械学習との関係:LLMとの正確な位置づけ
室谷代表取締役「dify 強化 学習」「dify 機械 学習」というキーワードも見受けられますが、これらはDifyというよりもDifyが使っているLLM自体の学習方式の話になってきます。
テキトー教師.AI認定講師LLMはRLHF(人間のフィードバックに基づく強化学習)という手法で学習しているものが多いですよね。ChatGPTやClaudeもRLHFを使っています。
ただしこれはDifyとは別レイヤーの話です。
ただしこれはDifyとは別レイヤーの話です。
室谷代表取締役Difyはそのように学習済みのLLMを「使う」ためのプラットフォームなので、強化学習や機械学習をDifyで行うというわけではありません。DifyはLLMの上に乗るアプリケーション層ですね。
テキトー教師.AI認定講師「DifyでAIをトレーニングする」という文脈ではなく、「DifyでトレーニングされたAIを使ったアプリを作る」という理解が正しいです。
室谷代表取締役ただし、将来的にはDifyのプラグインエコシステムが発展して、ファインチューニングをワークフローに組み込むようなことができるようになるかもしれないですね・・・今はまだそこまでではないですが。
テキトー教師.AI認定講師Difyのセルフホスト版のメリット:データを完全にコントロールする
室谷代表取締役クラウド版とセルフホスト版の話を改めてしておきたいんですよ。学習・データ管理の観点から、これは結構重要な選択です。
テキトー教師.AI認定講師セルフホスト版のメリットは何といってもデータが自分のサーバーに閉じることですよね。クラウド版はDifyのサーバーにデータが保存されますが、セルフホスト版は自分のインフラで完結します。
室谷代表取締役医療、法律、金融のような機密性が高い業界では、セルフホスト版一択ですね。クラウド版はDifyのプライバシーポリシーに従ってデータが扱われますが、セルフホスト版はその制約がないです。
テキトー教師.AI認定講師セルフホスト版はDockerで動かすので、ある程度の技術知識が必要になります。さっき話したDockerのトラブルシューティングもセルフホスト特有の問題です。
室谷代表取締役コスト的にはセルフホスト版の方がランニングコストを抑えられる場合がありますね。ただしサーバーの維持管理コストや構築工数が入ってくるので、規模によってはクラウド版の方が安い場合もあります。
テキトー教師.AI認定講師企業での導入判断としては、「データの管理責任をどこに置くか」が一番の分岐点だと思います。社内のデータガバナンスポリシーと照らし合わせて判断するのが大事ですよ。
| 比較項目 | クラウド版(Dify.ai) | セルフホスト版 |
|---|---|---|
| データ管理 | Difyのプライバシーポリシーに従う | 完全に自社管理 |
| 構築コスト | 無料で始められる | サーバー費用・構築工数が必要 |
| 技術要件 | なし | Docker、サーバー管理の知識が必要 |
| カスタマイズ性 | 制限あり | ソースコードレベルで自由にカスタマイズ可能 |
| 向いている用途 | 個人・スモールビジネス・プロトタイプ | 機密データを扱う企業・大規模運用 |
室谷代表取締役MYUUUでは用途によって使い分けていますよ。プロトタイプや検証はクラウド版で素早く試して、本番運用に移すときにセルフホスト版に切り替えるという流れが多いです。
Difyを使った新人教育・業務自動化の実例
室谷代表取締役実例の話をしましょう。DifyのRAGを使った新人教育の自動化は、すでに実際の企業で成果が出ていますよね。
テキトー教師.AI認定講師実際に講座の受講生さんの中でも、Difyで社内の作業マニュアルをRAG化して新入社員向けのQAシステムを作った方がいます。「新入社員が直接AIに聞ける環境を作ることで、既存社員への質問が大幅に減った」という報告をもらいました。
室谷代表取締役MYUUUでもこれは実感していますね。企業の作業マニュアルが入っているGoogleドライブをRAG化して、チャットボットに搭載することで新入社員は会話しながら定型業務の学習ができる。
テキトー教師.AI認定講師AIを使えば既存社員の時間を奪わず新人教育ができるというのは、採用コストや教育コストの観点からも非常に価値が高いですよね。
室谷代表取締役ポイントは「マニュアルの質」なんですよ。Difyに入れるドキュメントがしっかりしていないと、AIの回答も質が低くなる。
Difyを導入するタイミングで社内マニュアルを整備し直すという副次効果もあります。
Difyを導入するタイミングで社内マニュアルを整備し直すという副次効果もあります。
テキトー教師.AI認定講師そこは本当に重要で、「Difyが答えられないから社内マニュアルを充実させた」という形で、マニュアルの品質が上がった事例もありますよ。ツールを導入することで社内の情報整理が進むという嬉しい副作用です。
Difyの「簡単な例」:初めての人向けガイド
室谷代表取締役「dify 簡単 な 例」で調べてくる人向けに、一番シンプルな使い方を紹介しましょう。全部の機能を一気に使おうとしないで、まず基本の形から始めることが重要です。
テキトー教師.AI認定講師一番シンプルな例は「FAQチャットボット」です。会社のFAQドキュメントをテキストで用意して、Difyのナレッジベースに入れて、チャットボットに接続する。
これだけで質問に答えてくれるbotができます。
これだけで質問に答えてくれるbotができます。
室谷代表取締役最初の一歩としてはこの流れです。
- Dify.ai でアカウントを作成(無料)
- モデルプロバイダーでOpenAIかAnthropicのAPIキーを設定
- Knowledgeで新しいナレッジベースを作成し、FAQのテキストファイルをアップロード
- Studioでチャットボットアプリを作成
- コンテキストに作成したナレッジベースを追加
- Web App URLを共有して完成
テキトー教師.AI認定講師これ、早ければ30分以内でできますよ。プログラミング知識は一切不要です。
室谷代表取締役Difyは「Do It For You(あなたのためにそれを行う)」という意味から名前がついているんですが、まさにそのコンセプト通りで、プログラマーじゃなくてもAIアプリが作れるというのが最大の強みです。
テキトー教師.AI認定講師.AI(ドットエーアイ)の講座でもDifyを最初に触る人に「とにかく1個作ってみる」ことを推奨しています。完璧なものを目指すより、まずシンプルなものを動かして仕組みを体感するのが大事です。
よくある質問
Q. Difyにドキュメントをアップロードすると、OpenAIやAnthropicのモデルが学習してしまいますか?
室谷代表取締役しません。DifyのナレッジベースはDifyのシステム内に保存され、OpenAIやAnthropicのAPIに渡されるのは「チャットの文脈」としてだけです。
RAGの仕組みを使って質問に関連するドキュメントの断片を取り出し、その断片と質問を合わせてAPIに送っています。モデル自体のパラメータは変わりません。
RAGの仕組みを使って質問に関連するドキュメントの断片を取り出し、その断片と質問を合わせてAPIに送っています。モデル自体のパラメータは変わりません。
テキトー教師.AI認定講師また、OpenAIのAPIを使用する場合、OpenAIのAPIポリシーでは「APIから受け取ったデータを使ってモデルをトレーニングしない」と明記されています。ただし最新のポリシーは必ず公式サイトで確認してください。
Q. チャット履歴を参照して、次の会話で覚えていてほしいのですが可能ですか?
室谷代表取締役デフォルトでは、会話ごとに「メモリ」がリセットされます。ただし、Difyにはメモリ機能があり、特定の会話の文脈を保持する設定ができます。
アプリ設定の「会話開放型」を選択し、過去の会話を参照する設定をオンにすることで実現できます。
アプリ設定の「会話開放型」を選択し、過去の会話を参照する設定をオンにすることで実現できます。
テキトー教師.AI認定講師ただしこれも「モデルが学習している」わけじゃなくて、「過去の会話ログを文脈として渡している」だけです。会話が長くなるほどコンテキストウィンドウを消費するので、コストとのバランスを考えながら設定することをおすすめします。
Q. セルフホスト版でデータを完全にプライベートにしたいのですが、注意点はありますか?
室谷代表取締役セルフホスト版で使用する際も、LLMのAPIを外部サービス(OpenAI、Anthropic等)に接続する場合は、そのAPIにデータが送信されます。完全にプライベートにしたい場合は、Ollamaなどを使ってローカルのLLMをセルフホストするか、セルフホスト可能なLLMサービスを使う必要があります。
テキトー教師.AI認定講師完全なオンプレミスAIを実現したい場合は、Difyのセルフホスト + ローカルLLM(Ollama等)という組み合わせが最強です。ただし、ローカルLLMはクラウドのLLMと比べて性能が劣るケースが多いので、どこまで精度が必要かとのトレードオフになります。
Q. ナレッジベースの情報が古くなったらどうすればいいですか?
室谷代表取締役DifyのKnowledge管理画面から、該当のドキュメントを削除して新しいものをアップロードするか、ドキュメントの内容を直接編集できます。更新後は自動でインデックスが再生成されます。
テキトー教師.AI認定講師定期的なドキュメント更新が必要な場合は、DifyのAPIを使って自動更新の仕組みを組むことも可能です。例えば社内Wikiのドキュメントが更新されたときに自動でDifyのナレッジベースも更新するような連携が作れます。
まとめ:DifyはAIを「学習させない」からこそ使いやすい
室谷代表取締役今回の記事のポイントをまとめると、「DifyはAIに学習させない」ということが逆に最大の強みだということです。
テキトー教師.AI認定講師そうなんですよね。モデルのパラメータを変えないからこそ、ドキュメントをいつでも更新できる。
機密データがモデルに埋め込まれるリスクがない。そして高額なGPUや専門知識なしにAIアプリが作れる。
機密データがモデルに埋め込まれるリスクがない。そして高額なGPUや専門知識なしにAIアプリが作れる。
室谷代表取締役RAGは「毎回カンニングペーパーを渡す」仕組みだと言いましたが、この仕組みのおかげで情報を常に最新の状態に保てるし、不要になった情報はナレッジベースから削除するだけで参照されなくなります。
テキトー教師.AI認定講師「学習させたい」という気持ちに応えるためには、アノテーションシステムを活用する。そしてナレッジベースを丁寧に整備して、チャンク分割とインデックスの設定を最適化する。
これが実質的な「精度向上」につながります。
これが実質的な「精度向上」につながります。
室谷代表取締役DifyでできないことはLLMの根本的なトレーニングですが、それ以外の「ビジネスで使えるAIアプリを作る」という目的においては、DifyのRAGで十分すぎるほど対応できます。
テキトー教師.AI認定講師まだDifyを試したことがない方は、まずシンプルなFAQチャットボットを作ってみることをおすすめします。30分もあれば動くものが作れるので、まず体験してみてください。



















