
ChatGPT RAGとは?自社データをAIに読ませる仕組みと実装方法を完全解説【2026年最新】
 室谷
室谷今回はChatGPT RAGの話をしましょう。「RAGってなんですか?」という質問、.AI(ドットエーアイ)コミュニティで毎週来るんですよね・・・
 テキトー教師
テキトー教師わかります。講座でも序盤で必ず出てきますね。
「RAGってAIと何が違うんですか?」から始まって、最終的に「じゃあどうやって自社の資料を読ませるんですか?」という流れになるんですよ。
「RAGってAIと何が違うんですか?」から始まって、最終的に「じゃあどうやって自社の資料を読ませるんですか?」という流れになるんですよ。
室谷そうそう。RAGって聞くと難しそうに思えるんですけど、本質はシンプルなんですよね。
「ChatGPTに自分の情報を渡してから質問する」、それだけなんです。
「ChatGPTに自分の情報を渡してから質問する」、それだけなんです。
テキトー教師正確に言うと「Retrieval-Augmented Generation(検索拡張生成)」の略ですよね。AIが自分の学習データだけで答えるんじゃなくて、外部の情報を検索して持ってきてから答えを生成するという仕組みです。
室谷「自分の情報を渡してから質問する」で8割伝わりますよ(笑)。MYUUUでも社内の議事録とかナレッジドキュメントをRAGで読ませて、新人が「このプロジェクトってどういう経緯だっけ?」って聞けるシステムを作ってますから。
テキトー教師それが一番わかりやすいユースケースですよね。会社の情報って量が多すぎてどこに何があるか把握できない。
そこにAIを組み合わせると、「あの資料どこだっけ?」じゃなくて「この内容について教えて」で済むようになる。
そこにAIを組み合わせると、「あの資料どこだっけ?」じゃなくて「この内容について教えて」で済むようになる。
室谷ChatGPTでRAGをやろうとすると、大きく2つのアプローチがあるんですよ。「ChatGPT本体の機能を使う」か「OpenAI APIでRAGシステムを自作する」か。
テキトー教師そこが混乱するポイントなんですよね。コミュニティのメンバーさんがよくハマるのが「RAGとファイルアップロードって違うんですか?」という質問です。
室谷違いますね。ファイルアップロードは「そのチャットの中だけで使える」。
RAGは「システムとして仕組みを作って、継続的に使える」というイメージです。
RAGは「システムとして仕組みを作って、継続的に使える」というイメージです。
ChatGPT RAGとは?仕組みをわかりやすく解説
テキトー教師まず「ChatGPT RAG」という言葉の整理から始めましょう。これ、実は2種類の意味で使われているんですよ。
室谷ですね。「ChatGPTをRAGのLLMとして使うシステム」と「ChatGPTのRAG機能(ファイル検索)を使う」、この2つが混在してます。
テキトー教師整理するとこういう構造になります。
RAGの基本的な仕組みは以下の通りです。
- ユーザーが質問する
- 検索エンジンが関連する情報を取得する(自社DB、ドキュメント、ベクトルDBなど)
- 取得した情報+質問をAIに渡す
- AIが情報を元に回答を生成する
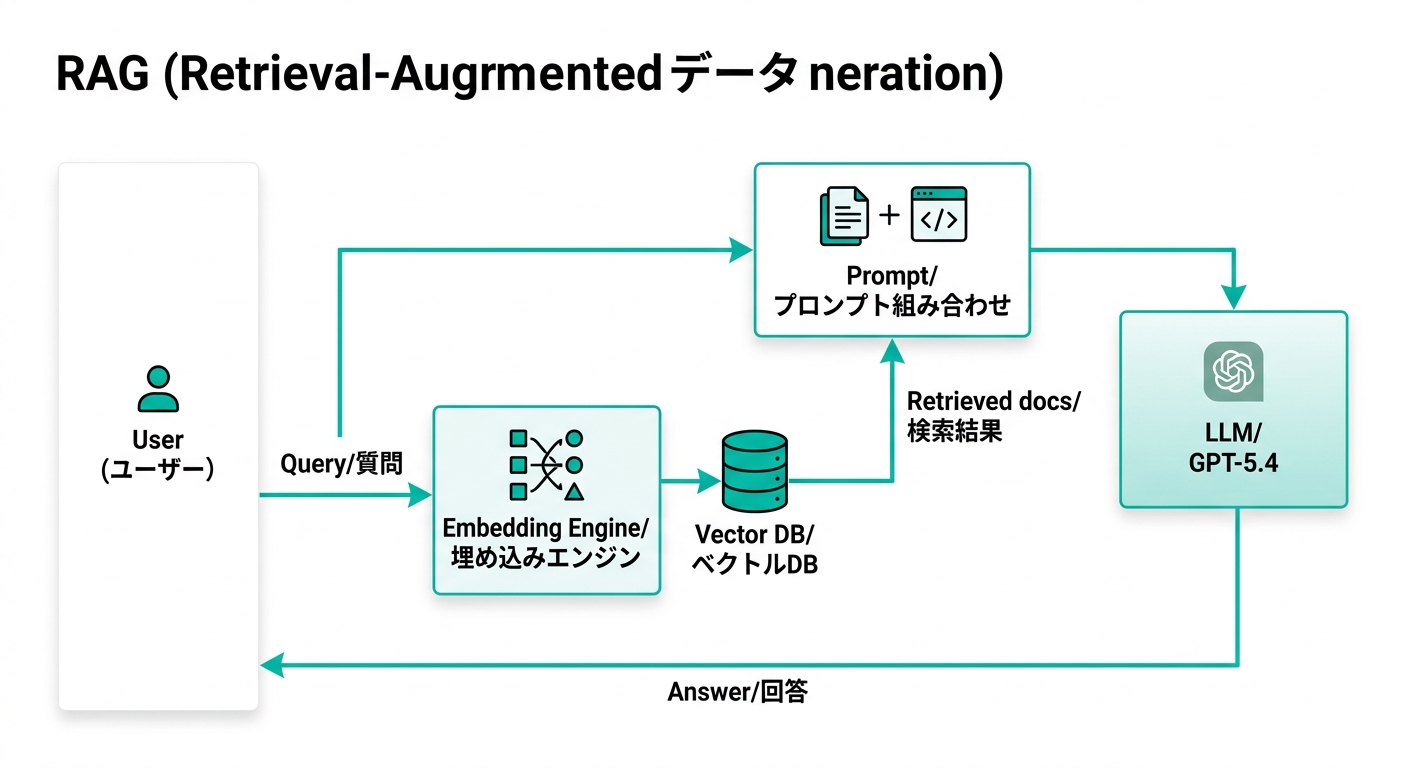
室谷この「2のステップ」がRAGの肝なんですよね。普通のChatGPTは1→4を直結させてる。
RAGは2と3を間に挟むことで、AIが知らない情報(社内資料・最新情報・独自データ)に基づいて答えられるようになる。
RAGは2と3を間に挟むことで、AIが知らない情報(社内資料・最新情報・独自データ)に基づいて答えられるようになる。
テキトー教師なぜこれが重要かというと、ChatGPT単体だと「あなたの会社のことは知らない」「社外秘の資料は見たことがない」という限界がありますよね。RAGはその限界を突破する手法なんです。
室谷ハルシネーション(AIの嘘)も減るんですよ。「このソースに書いてあることを元に答えて」と指定できるので、AIが知ったかぶりしにくくなる。
テキトー教師そこは講座で強調するポイントですね。RAGは「精度を上げる仕組み」でもある。
ただ情報量を増やすだけじゃなくて、「根拠のある回答」を引き出せる。
ただ情報量を増やすだけじゃなくて、「根拠のある回答」を引き出せる。
室谷海外でも「独自データを活用したプロダクト」が増えてきたという流れがあって、RAGが注目されるのも自然な流れですよ。単純にLLMのAPIをラップしただけのプロダクトは差別化が難しくなってきてる。
ChatGPT本体で使えるRAG的な機能(APIなしでできること)
室谷まず「APIとか技術的な話は置いといて、今すぐ使いたい」という人向けの話をしましょう。ChatGPT本体にもRAG的な使い方ができる機能が複数あります。
テキトー教師代表的なのは「ファイルアップロード」「プロジェクト機能のナレッジ」「ChatGPTコネクター」の3つですね。
ファイルアップロード
室谷一番手軽なのはファイルアップロードです。PDF、Word、ExcelをそのままChatGPTに渡して「この資料の〇〇を教えて」と聞ける。
テキトー教師ただ、これは「そのチャットのみ有効」なんですよね。次のチャットを開いたらもう一度ファイルを渡さないといけない。
継続的に使えるという意味では制限があります。
継続的に使えるという意味では制限があります。
室谷プラン別の制限もあります。OpenAIのサポートページ()で確認した範囲では・・・
ChatGPTのファイルアップロード制限は次のとおりです(2026年4月時点)。
| 項目 | 制限 |
|---|---|
| ファイルサイズ上限 | 512MB / 1ファイル |
| テキスト・ドキュメント | 200万トークン / ファイル |
| CSV・スプレッドシート | 約50MB |
| 画像 | 20MB |
| 1チャット内のアップロード数 | 80ファイル / 3時間 |
| 無料ユーザー | 3ファイル / 日 |
| Plusプロジェクト | 20ファイル / プロジェクト |
| Pro・Team・Business | 40ファイル / プロジェクト |
テキトー教師無料ユーザーは1日3ファイルというのが意外と知られてないんですよ。「さっきまでアップできたのになぜ?」って困っている人がいます。
室谷Plusから一気に使いやすくなりますね。プロジェクトに40ファイルまで入れておけるのは実用的です。
プロジェクト機能でのナレッジ管理
テキトー教師プロジェクト機能が使えるようになってから、RAG的な使い方が一気に手軽になったと思います。プロジェクトに資料を置いておけば、そのプロジェクト内の全チャットで参照できる。
室谷MYUUUでも事業別にプロジェクトを分けて、それぞれに関連ドキュメントを入れてます。「.AIプロジェクト」には講座資料やコミュニティのFAQを入れておいて、チームメンバーが質問できるようにしてる。
テキトー教師RAGシステムを自作しなくても同じ体験ができる、という意味で価値が高いですね。ただ、ファイル数の制限があるので「数百の社内資料を全部入れたい」というニーズには対応しきれない。
室谷ちょうどいい規模感があって、「チームで資料を共有して、ChatGPTに聞ける状態にする」というユースケースは、プロジェクト機能で十分カバーできます。
ChatGPTコネクター(Business・Enterprise)
室谷ここが海外で注目されているんですよ。ChatGPTのBusinessプランやEnterpriseプランには、外部サービスとの連携機能があります。
テキトー教師OpenAIの公式サイトで確認したところ、対応しているのはMicrosoft SharePoint、GitHub、Google Drive、Box、Atlassianなどです。60以上のアプリに対応していると記載されていました(参照)。
室谷つまり「GoogleドライブにあるファイルをChatGPTから直接検索できる」ということです。RAGシステムを自分で構築しなくても、コネクターを設定するだけで自社データにアクセスできる。
テキトー教師ただしBusinessプランは1ユーザーあたり月額課金で、Enterpriseはさらに大規模向けでコンタクト営業が必要です。「ちょっと試してみたい」個人や小規模チームには向かない。
室谷そこなんですよね・・・。「手軽に試したい」という場合はプロジェクト機能、「本格的に自社データと連携したい」という場合はAPIでRAGを組む、という使い分けが現実的だと思います。
OpenAI APIでChatGPT RAGを実装する方法
テキトー教師ここからが「chatgpt rag 実装」「chatgpt rag やり方」を調べている人向けの話ですね。OpenAI APIを使ってRAGシステムを自作する方法です。
室谷API経由だと、自社のデータベースやファイルサーバーと繋いで、かなり本格的なシステムが作れます。コストもコントロールしやすい。
RAGシステムの基本構成
テキトー教師整理すると、APIでRAGを実装する場合の基本構成はこうなります。
[ユーザーの質問]
↓
[Embedding APIで質問をベクトル化]
↓
[ベクトルDBで類似ドキュメントを検索・取得]
↓
[関連ドキュメント + 質問をプロンプトに組み込む]
↓
[GPT-5.4などが回答を生成]
キーワードは「埋め込み(Embedding)」と「ベクトルDB」です。難しく聞こえますが、「文章の意味を数字に変換して、似た意味の文章を素早く探せるデータベース」というイメージです。
テキトー教師ここが最初の壁なんですよね。「ベクトルDBって何を使えばいいんですか?」という質問も多い。
ベクトルDBの選択肢
室谷ベクトルDBは選択肢が多いんですが、代表的なものとして Pinecone、Weaviate、Chromaなどがあります。ローカルで手軽に試すならChromaが入門向きです。
テキトー教師ただ、環境構築で「難しくて挫折した」という人が多いのも事実ですよね。そういう場合はOpenAIのAssistants APIに内蔵されているFile Searchが便利です。
室谷そうですね。OpenAIがベクトル化からストレージまで全部面倒を見てくれるので、自分でベクトルDBを立てなくていい。
Assistants APIのFile Searchを使う場合
テキトー教師OpenAIのAssistants APIには「File Search」というツールが内蔵されていて、これを使うと比較的簡単にRAGを実装できます。Pythonでの基本的な流れを見てみましょう。
from openai import OpenAI
client = OpenAI()
# 1. Vector Storeを作成(ドキュメントの保存先)
vector_store = client.vector_stores.create(
name="社内ナレッジベース"
)
# 2. ドキュメントをアップロード
with open("company_manual.pdf", "rb") as f:
file = client.files.create(file=f, purpose="assistants")
# 3. Vector StoreにFileを追加
client.vector_stores.files.create(
vector_store_id=vector_store.id,
file_id=file.id
)
# 4. Assistantを作成(File Searchツールを有効化)
assistant = client.assistants.create(
model="gpt-5.4",
tools=[{"type": "file_search"}],
tool_resources={
"file_search": {
"vector_store_ids": [vector_store.id]
}
}
)
# 5. 質問する
thread = client.threads.create()
message = client.threads.messages.create(
thread_id=thread.id,
role="user",
content="会社の有給休暇ルールを教えて"
)
run = client.threads.runs.create_and_poll(
thread_id=thread.id,
assistant_id=assistant.id
)
これで「company_manual.pdf」の内容をChatGPTが参照して答えてくれるわけです。自分でベクトルDBを管理しなくていいのは楽ですね。
テキトー教師Assistants APIを使ったRAGは入門として最適だと思います。「もっと大規模に」「もっと細かく制御したい」という段階になったら外部ベクトルDBを検討すれば良い。
室谷実際のシステムになると「どのドキュメントをどう分割するか(チャンキング)」「どのEmbeddingモデルを使うか」「検索の精度をどう上げるか」という話になってくるんですが、最初はこのシンプルな構成で動かしてみるのがいいです。
ChatGPT RAG 無料でできるのか?コスト比較
室谷よく聞かれるのが「chatgpt rag 無料でできますか?」という質問ですね。
テキトー教師結論から言うと「ChatGPT本体の機能を使うなら無料でもできる、APIを使うなら一定のコストがかかる」ですね。
室谷もう少し詳しく整理すると・・・
| 方法 | コスト | 難易度 | 規模 |
|---|---|---|---|
| ChatGPTファイルアップロード(無料プラン) | 無料(1日3ファイル) | 低 | 小 |
| ChatGPTプロジェクト機能(Plusプラン) | $20/月 | 低 | 中 |
| ChatGPT Business(コネクター) | 要問い合わせ | 中 | 中〜大 |
| OpenAI Assistants API(File Search) | 使用量課金 | 中 | 中〜大 |
| OpenAI API + 外部ベクトルDB | 使用量課金 + DB費用 | 高 | 大 |
テキトー教師「無料で試したい」という場合、まずはChatGPTの無料プランでファイルをアップロードして試してみるのが一番です。1日3ファイルという制限はあるけど、RAGの感覚を掴むには十分です。
室谷APIを使う場合のコストですが、OpenAI APIの料金(2026年4月時点、より)はGPT-5.4がInput $2.50 / 100万トークン、Output $15.00 / 100万トークンとなっています。
テキトー教師テキストをベクトルに変換するEmbeddings APIも別途かかりますが、こちらは非常に安いです。大量のドキュメントを処理しても、コストは数百円レベルで済むことが多い。
室谷コストで悩む前に「まず動かしてみる」ことが大事なんですよ。MYUUUの初期の社内RAGも、Pythonで50行くらいで作りましたから。
ChatGPT RAG 構築のステップと実践的なやり方
テキトー教師「chatgpt rag 構築」を検討している方向けに、実際に進める手順をまとめてみましょう。
室谷最初に決めることは「ChatGPT本体の機能を使うか、APIで作るか」ですね。
ステップ1: 目的と規模を決める
テキトー教師まず「何のためにRAGを使いたいか」を明確にします。
- 社内のFAQ対応: プロジェクト機能 or Assistants APIで十分
- 顧客向けチャットボット: API + ベクトルDB が必要
- 大量のドキュメント(数百〜数千件): API + 本格的なベクトルDB
- リアルタイム更新が必要: API + データパイプラインが必要
室谷「どのくらいのドキュメント数か」と「更新頻度」が判断の軸になりますね。社内FAQ10〜20件くらいなら、ChatGPTのプロジェクト機能で本当に十分だと思います。
ステップ2: ドキュメントを整える
テキトー教師よく見落とされるのがここなんですよ。RAGの精度は「入れるドキュメントの質」に大きく依存します。
室谷「ゴミを入れたらゴミが出てくる」んですよ。情報が整理されていないドキュメントを入れると、精度が全然出ない。
テキトー教師ドキュメントを整えるポイントとして、見出しや箇条書きで構造化されているか、重複や矛盾がないか、最新の情報かどうかを確認しておくのが大事です。
室谷MYUUUでは事前に「RAG用のドキュメント整備」を専用タスクとして設定してますね。ここをサボると、後でRAGの精度が出なくて困ります。
ステップ3: チャンキングを考える
テキトー教師ドキュメントをRAGに入れるときに「どう分割するか」、これをチャンキングと言います。
室谷Assistants APIのFile SearchはOpenAIが自動でチャンキングしてくれるので、最初は気にしなくていいです。自分でベクトルDBを使う場合は考える必要があります。
テキトー教師基本的には「意味のある単位で分割する」のが原則です。長すぎると検索精度が下がり、短すぎると文脈が失われる。
よく使われるのは300〜500トークンくらいの単位で、前後に少し重複を持たせる手法です。
よく使われるのは300〜500トークンくらいの単位で、前後に少し重複を持たせる手法です。
ステップ4: 検索精度を上げる工夫
室谷最初に動かしてみると「思ったより精度が出ない」と感じることが多いんですよ。
テキトー教師そのときによく効くのが「ハイブリッド検索」です。ベクトル検索(意味の近さで検索)と全文検索(キーワードで検索)を組み合わせる手法で、どちらか一方よりも精度が出やすい。
室谷あとは「プロンプトの設計」も大事です。「以下のドキュメントにない情報については、わからないと答えてください」という指示を入れることで、ハルシネーションをさらに抑えられます。
ChatGPT RAG APIとの組み合わせ事例
テキトー教師「chatgpt api rag」という検索をしている方向けに、実際の活用事例を見てみましょう。
室谷実際に企業がChatGPT RAGを使っているケースをいくつか挙げてみます。
社内ヘルプデスクの自動化
テキトー教師一番多い事例ですね。IT部門への「パスワードリセットはどうやるの?」「社内システムのマニュアルはどこ?」という問い合わせをChatGPT RAGで対応する。
室谷社内情報さえ整備されていれば、定型的な問い合わせはAIで対応できるようになります。MYUUUでも試してみたところ、チームへの質問が明らかに減りましたね。
テキトー教師ポイントは「AIが答えられなかった質問のログを取る」こと。それを元にドキュメントを補強することで、精度がどんどん上がっていく。
営業資料・提案書の自動生成支援
室谷自社の提案事例や製品情報をRAGに入れて、「〇〇業界向けの提案書を作って」と聞けるシステムも面白いですね。
テキトー教師これは海外でも事例が多くて、特にB2Bの営業領域での効果が高いと言われています。「過去の成功事例を参照しながら提案書を作る」というのは、RAGが最も得意とするユースケースの一つです。
室谷「ChatGPT Enterprise RAG」を調べている方はこのユースケースが多い印象です。Enterpriseプランだと大きなコンテキストウィンドウ(約250ページ相当)が使えるので、より大きなドキュメントを渡せる。
カスタマーサポートの高度化
テキトー教師製品マニュアルやFAQをRAGに入れて、顧客からの問い合わせに自動応答するシステムですね。
室谷ここでの注意点は「最新の情報を維持し続ける」ことです。製品がアップデートされてもRAGのドキュメントが古いままだと、間違った情報を答えてしまう。
テキトー教師「定期的にドキュメントを更新するプロセス」をセットで設計することが大事ですね。RAGを「作って終わり」ではなくて、「運用前提のシステム」として考える。
ChatGPT RAGとDifyを組み合わせる
室谷「RAGを自作するのはハードルが高い」という方には、DifyというノーコードAIツールを組み合わせる選択肢もあります。
テキトー教師Difyはナレッジベース機能があって、ファイルをアップロードするだけでRAG的な使い方ができます。ChatGPTのAPIをDifyで使えば、プログラミングなしで「ChatGPT RAG」を実現できる。
室谷Difyのコネクターを使えばGoogleドライブもRAG化できるんですよね。社内資料がGoogleドライブにある会社は多いので、これだけで実用的なRAGシステムができあがります。
テキトー教師ただ、DifyのRAGにも限界があって、「複雑な検索ロジック」「大規模なドキュメント数」「細かい精度チューニング」が必要な場合は、直接APIを使った実装を考えたほうがいい。
室谷「まずDifyで試して、もっとやりたくなったらAPIへ」という段階を踏むのが一番挫折しにくいと思います。
ChatGPT RAGの精度を上げる実践的なTips
テキトー教師「RAGを動かしたけど精度が出ない」という相談、講座でよく来るんですよ。
室谷あるあるですね。動かすのは意外と簡単なんですが、「使えるレベルにする」が難しい。
プロンプトの設計
室谷プロンプト設計が一番効果が大きいですね。基本形は「以下のコンテキストを元に質問に答えてください。
コンテキストに情報がない場合は、わかりません、と答えてください」という構造です。
コンテキストに情報がない場合は、わかりません、と答えてください」という構造です。
テキトー教師「コンテキストに情報がない場合はわかりませんと答える」という指示が超重要です。これを入れないと、AIが持っている既存の知識で補完してハルシネーションが起きます。
室谷あとは「必ず出典(どのドキュメントに書いてあったか)を示してください」という指示も効果的です。ユーザーが検索結果の根拠を確認できるので、信頼性が上がる。
チャンキングの最適化
テキトー教師チャンキングのサイズと重複(オーバーラップ)を調整することで、検索精度が変わります。
室谷一般的な傾向として、チャンクサイズを小さくすると精度が上がりやすいですが、文脈が失われやすくなります。オーバーラップを入れることで文脈の連続性を保てます。
テキトー教師ドキュメントの種類によっても最適なチャンクサイズは違う。FAQ形式なら1Q1Aを1チャンクにする、技術マニュアルなら章ごとに分割する、というように。
メタデータの活用
室谷ベクトル検索だけじゃなくて「このドキュメントは2026年作成」「部門は営業」というメタデータを付けて、フィルタリングに使うと精度が上がります。
テキトー教師「最新のマニュアルだけを参照したい」「営業部門のFAQだけを検索したい」という絞り込みができるようになります。
よくある質問
室谷最後に、よくある質問をまとめておきましょう。
テキトー教師コミュニティで聞かれること、講座で聞かれること、まとめると大体同じパターンになりますよね(笑)。
RAGとファインチューニングは何が違うの?
テキトー教師よく混同される2つですね。RAGは「回答するときに外部情報を参照する仕組み」、ファインチューニングは「モデル自体に知識を学習させる仕組み」です。
室谷コストと速度で言うと、RAGは比較的安くて情報の更新が楽、ファインチューニングはコストが高くて再学習に時間がかかる。最初はRAGから始めるのが正解だと思います。
どのモデルを使えばいいの?
室谷2026年現在、OpenAI APIで使えるメインのモデルはGPT-5.4ファミリーです。RAGの精度を重視するならGPT-5.4、コストを抑えたいならGPT-5.4 miniやGPT-5.4 nanoが選択肢になります(参照)。
テキトー教師まずGPT-5.4 miniで動かしてみて、精度が足りなければGPT-5.4に切り替えるというアプローチが現実的ですね。
RAGと通常のChatGPTで精度はどれくらい違うの?
室谷「自社のデータについての質問」に限定すれば、RAGの方が圧倒的に精度が高いですね。通常のChatGPTは自社情報を知らないので、それっぽい回答を生成してしまいます。
テキトー教師「一般的な知識」の質問は通常のChatGPTが得意で、「特定のドメイン・組織固有の情報」の質問はRAGが得意、という使い分けが正しいですね。
まとめ
室谷今回はChatGPT RAGについて、仕組みから実装方法まで話しましたが、最初に言った通り「自分の情報を渡してから質問する」というシンプルな発想から始まっているんですよね。
テキトー教師RAGのアプローチをまとめるとこうなります。
| アプローチ | 向いているケース | 難易度 |
|---|---|---|
| ChatGPTファイルアップロード | 単発の資料分析 | 低 |
| ChatGPTプロジェクト機能 | チームでのナレッジ共有(40ファイルまで) | 低 |
| ChatGPT Business コネクター | Google Drive・SharePoint連携 | 中 |
| Assistants API File Search | 中規模システム・プロトタイプ | 中 |
| API + 外部ベクトルDB | 大規模・高精度・カスタム要件 | 高 |
室谷「まず動かしてみる」ことが大事です。小さく始めて、必要に応じてスケールアップしていくというアプローチが長続きします。
テキトー教師「RAGって難しそう」と思っていた方が、ChatGPTのプロジェクト機能で試してみたら「これだけで十分だった!」という体験をされることも多いですから。技術的に複雑な実装が必ずしもベストとは限らない。
室谷自社の情報をAIに読ませて使えるようにする。これができるようになると、会社での仕事の進め方が根本から変わります。
ぜひ一歩踏み出してみてください。
ぜひ一歩踏み出してみてください。









