
CursorでローカルLLMを使う完全ガイド|OllamaとLM Studioで設定する方法
 室谷
室谷今回はCursorでローカルLLMを使う話をしていきましょう。これ、.AIコミュニティでも結構聞かれるテーマで・・・コスト的な理由でローカルLLMに興味持ってる人がすごく多いんですよね。
 テキトー教師
テキトー教師受講生さんからも「Cursorのフロンティアモデルを使いすぎてAPI費用がかさむ」って相談は定期的に来ます。月$20のProプランを超えて追加課金になるパターン、ほんと多いんですよ(笑)
室谷そうなんですよね。でもここで気をつけてほしいのが、ローカルLLMに全部移行しようとするのは現実的じゃないケースも多いってこと。
Cursorのタブ補完やAgentモードの精度は、今のクラウドモデルが支えてる部分が大きいので・・・
Cursorのタブ補完やAgentモードの精度は、今のクラウドモデルが支えてる部分が大きいので・・・
テキトー教師そうですね。「ローカルLLMに完全移行すれば無料になる」みたいな期待で始めると、精度が落ちてストレスになる人もいます。
用途を絞って使うのが賢いやり方だと思いますよ。
用途を絞って使うのが賢いやり方だと思いますよ。
室谷今日はまさにそこを整理したいですね。どういうケースでローカルLLMが有効で、どう設定するか。
実際の設定手順も含めて話しましょう。
実際の設定手順も含めて話しましょう。
テキトー教師CursorのローカルLLM設定、やってみると意外とシンプルで驚く人も多いです。ポイントを押さえれば30分かからずに動きますからね。
ローカルLLMをCursorで使うべき理由
室谷まず「なぜローカルLLMを使うのか」から整理しましょう。理由は主に3つあって、コスト削減、プライバシー保護、オフライン利用ですね。
テキトー教師順番に言うと、コスト削減が一番わかりやすいですね。Cursorの料金プランを見ると、Proが月$20で、それを超えるとフロンティアモデルの追加料金がかかります。
開発ヘビーユーザーだと月$60〜$100になることもありますし。
開発ヘビーユーザーだと月$60〜$100になることもありますし。
室谷MYUUUでも複数プロジェクトを同時に動かしてるエンジニアは、普通にそのくらい使いますね。ローカルLLMで補えるところは補う、という使い分けをしてます。
テキトー教師2つ目のプライバシー保護は、企業だと特に重要ですね。クラウドモデルだとコードが外部サーバーに送信されますから、機密性の高いプロジェクトやセキュリティポリシーが厳しい現場では使えないケースがあります。
室谷3つ目のオフライン利用も意外と重要で・・・新幹線でガッツリコーディングしたいときとか、ネット環境が不安定なところでも動くのは地味に助かります。
テキトー教師講座で教えていて気づいたんですが、この3つの理由のうち、実際にローカルLLMに踏み切るきっかけになるのはほぼ「コスト」ですね。プライバシーは後から気づく人が多い(笑)
Cursorの料金プランとローカルLLMの位置づけ
テキトー教師ここで整理しておきたいのが、Cursorの現在の料金体系との関係です。まとめるとこうなります。
| プラン | 月額 | 特徴 |
|---|---|---|
| Hobby | 無料 | エージェントリクエスト・Tab補完に制限あり |
| Pro | $20 | フロンティアモデル(Claude、GPT、Gemini)、MCP、クラウドエージェント |
| Pro+ | $60 | Proの3倍の使用量 |
| Ultra | $200 | Proの20倍の使用量、新機能への優先アクセス |
室谷ローカルLLMはどのプランでも使えます。ただし、Cursorのタブ補完やAgentモードはCursorのクラウドモデルが動いてる部分が多いので、「ローカルLLMにしたら無料になる」わけじゃないんですよね。
テキトー教師そこが誤解されやすいポイントです。ローカルLLMを使えるのは主に「Chat機能」で、タブ補完はCursorのプロプライエタリな仕組みなので、ローカルモデルに置き換えることはできません。
室谷つまり「ChatのAIをローカルLLMで代替することでフロンティアモデルの消費を抑える」というのが実態ですね。それでも有効なユースケースはたくさんあります。
OllamaでローカルLLM環境を構築する
室谷設定方法に入りましょう。CursorでローカルLLMを使う一番ポピュラーな方法がOllamaを使うやり方です。
テキトー教師Ollamaは「オープンモデルでビルドするための最も簡単な方法」というコンセプトのプラットフォームで、ローカルでLLMを動かすためのランタイム環境ですね。コマンド一発でモデルをダウンロードして実行できます。
室谷何が良いって、OpenAI互換のAPIエンドポイントを持ってるんですよ。
http://localhost:11434/v1 でOpenAI形式のリクエストを受け付けるので、CursorのカスタムAPIキー設定と組み合わせて使えます。Ollamaのインストール手順
テキトー教師まずインストールから。OSごとのコマンドをまとめると以下です。
macOS / Linux:
curl -fsSL https://ollama.com/install.sh | sh
Windows(PowerShell):
irm https://ollama.com/install.ps1 | iex
Docker:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
macOSの場合は からDMGファイルをダウンロードしてインストールする方法もあります。macOS 14 Sonoma以降が必要なので注意が必要です。
テキトー教師インストール後はターミナルで
ollama --version を実行して確認しましょう。正常にインストールされていればバージョン番号が表示されます。コーディング向け推奨モデル
室谷次にモデルの選択です。Ollamaで使えるモデルは数百種類ありますが、コーディング用途に絞ると選択肢はある程度絞れます。
テキトー教師コーディング用途でよく使われるモデルをまとめるとこうなります。
| モデル名 | パラメータ | 必要VRAM目安 | 特徴 |
|---|---|---|---|
| codellama | 7B / 13B / 34B | 4〜20GB | Meta製コード特化モデル。軽量で高速 |
| deepseek-coder | 6.7B / 33B | 4〜20GB | コード精度が高い。日本語も比較的得意 |
| qwen2.5-coder | 7B / 14B / 32B | 4〜20GB | Alibaba製。多言語コードに強い |
| gemma3 | 4B / 12B / 27B | 4〜16GB | Google製。バランス型。文書作成も得意 |
| llama3.1 | 8B / 70B | 6〜40GB | Metaのフラグシップ。汎用で高品質 |
室谷個人利用でGPUが8GB程度なら
qwen2.5-coder:7b か codellama:7b あたりが現実的ですね。MYUUUのエンジニアが試したところ、qwen2.5-coderはコード補完の精度が良かったって話してました。テキトー教師受講生さんに多いのがM1/M2/M3 Macのケースなんですが、Apple Siliconは統合メモリでVRAMとRAMが共有されるので、16GB RAM搭載のMacなら13Bクラスのモデルがサクサク動きます。実はローカルLLMとApple Siliconの相性はかなり良いんですよ。
室谷そこは本当に重要なポイントで・・・NVIDIAのGPUがなくても、M1 MacBook Pro以降なら十分実用的なレベルで動かせます。
モデルのダウンロードと起動
テキトー教師モデルのダウンロードはこのコマンドだけです。
# モデルをダウンロード(例: qwen2.5-coder 7Bモデル)
ollama pull qwen2.5-coder:7b
# 対話形式でモデルを起動
ollama run qwen2.5-coder:7b
# サーバーとして起動(APIとして使う場合)
ollama serve
ollama serve を実行すると、デフォルトで http://localhost:11434 でサーバーが立ち上がります。これがCursorから参照するAPIエンドポイントになります。テキトー教師なお、macOSでOllamaをアプリとしてインストールした場合は、バックグラウンドで自動的にサーバーが起動するので
ollama serve は不要です。CursorとOllamaを連携する設定手順
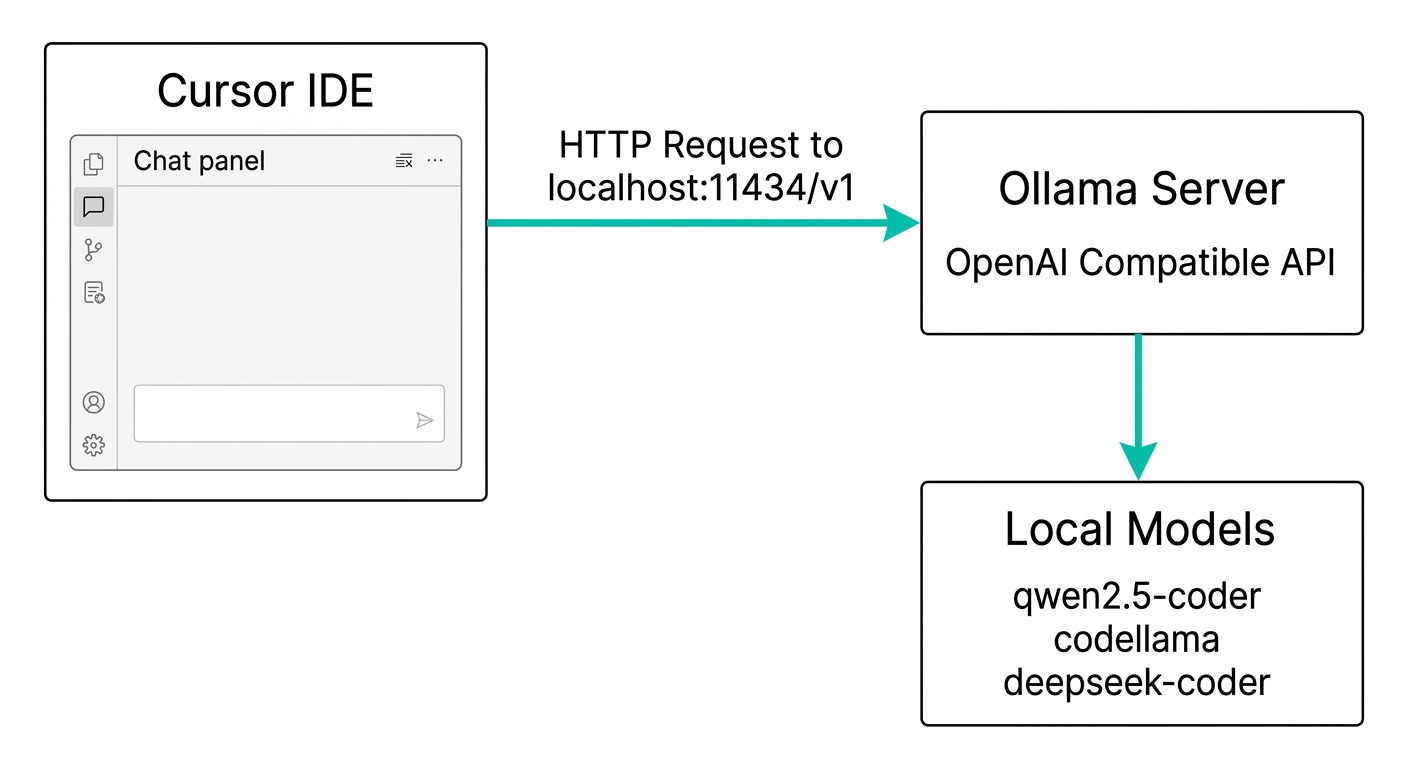
室谷ここがメインですね。CursorとOllamaをつなぐ設定方法です。
テキトー教師Cursorには「カスタムモデル」を追加できる機能があって、OpenAI互換のエンドポイントを持つサービスなら何でも設定できます。OllamaはOpenAI互換APIを持っているので、これを使います。
室谷設定は Cursor Settings(
Cmd+, / Ctrl+,)から行います。設定手順(ステップバイステップ)
テキトー教師手順をまとめると以下になります。
- Cursorを開いて Settings(歯車アイコン または
Cmd+,)を開く - 左メニューから Models を選択
- OpenAI API Key のセクションを見つける
- Base URL を
http://localhost:11434/v1に設定する - API Key は
ollama(任意の文字列でOK)と入力 - + Add Model ボタンをクリックして、使いたいモデル名(例:
qwen2.5-coder:7b)を追加 - 追加したモデルをデフォルトに設定してテスト
室谷API Keyは実際には使われないんですが、空欄だとエラーになるので
ollama という文字列を入れておくのが定番ですね。テキトー教師このあたりはOllamaの公式ブログ( but unused(必須だが使用されない)」という扱いです。
室谷設定後は実際にCursorのチャットで動作確認してみましょう。シンプルなコード生成リクエストを投げてみて、ローカルモデルが返答してくれれば成功です。
動作確認とトラブルシューティング
テキトー教師設定したのに動かない、というケースで一番多い原因がOllamaサーバーが起動していないことです。Cursorを開く前にOllamaが起動しているか確認しましょう。
室谷ブラウザから
http://localhost:11434 にアクセスして「Ollama is running」と表示されれば、サーバーは正常に動いてます。テキトー教師よくあるトラブルをまとめると、こんな感じです。
| 症状 | 原因 | 対処法 |
|---|---|---|
| モデルが応答しない | Ollamaサーバー未起動 | ollama serve または アプリを起動 |
| 「Connection refused」エラー | ポート11434が使えない | ファイアウォール設定を確認 |
| レスポンスが遅い | モデルサイズが大きすぎる | 小さいモデル(7B以下)に変更 |
| モデルが見つからない | pullしていない | ollama pull {モデル名} を実行 |
室谷あとARMベースのMacで動かす場合は特に問題ないんですが、古いIntel Macで重いモデルを動かそうとするとかなり遅くなります。7BモデルでもCPUだけだと厳しいケースがあるので・・・そこは現実的なスペックかどうか先に確認しておくのが大事ですね。
LM Studioを使う方法
室谷OllamaだけじゃなくてLM Studioという選択肢もあります。GUIで操作できるのでエンジニアじゃない人でも使いやすい。
テキトー教師LM Studioの特徴は「ローカルコンピュータでAIモデルをプライベートに実行できるデスクトップアプリ」という点ですね。インストールして起動すると、モデルの検索・ダウンロード・実行が全部GUIでできます。
室谷こちらもOpenAI互換エンドポイントを持っていて、デフォルトで
http://localhost:1234/v1 で動きます。Cursorの設定は Base URL をこのURLにするだけで、Ollamaと同じ要領で使えます。テキトー教師インストール方法はLM Studioの公式サイト(
# Mac / Linux
curl -fsSL https://lmstudio.ai/install.sh | bash
# Windows PowerShell
irm https://lmstudio.ai/install.ps1 | iex
OllamaとLM Studioの使い分けとしては、ターミナル操作が慣れてる人はOllama、GUIで管理したい人はLM Studioって感じですね。機能的には大きな差はないです。
テキトー教師受講生さんで「コマンドラインは苦手」という方にはLM Studioを勧めることが多いです。モデルのダウンロードや切り替えが視覚的にできるので、最初の壁が低いんですよ。
ローカルLLMとクラウドモデルを使い分けるベストプラクティス
室谷実際の使い方として、「ローカルLLMをメインにして、クラウドモデルは重要な作業だけ使う」というハイブリッド運用が現実的だと思っています。
テキトー教師講座でコミュニティのメンバーさんに教えているのも、タスクによって使い分けるアプローチですね。整理するとこういう分け方が使いやすいです。
室谷まとめるとこうなります。
| タスク | 推奨モデル | 理由 |
|---|---|---|
| 軽いコード補完・修正 | ローカルLLM(7B〜) | 速度優先、精度的にも十分 |
| コードの説明・ドキュメント生成 | ローカルLLM(7B〜) | コスト効率が良い |
| 複雑なアーキテクチャ設計 | クラウドモデル(Claude、GPT) | 高い推論能力が必要 |
| バグの根本原因分析 | クラウドモデル | 深い文脈理解が重要 |
| セキュリティが重要なコード | ローカルLLM | 外部送信を避けたい |
| 新しいフレームワークの学習 | クラウドモデル | 最新情報が必要 |
テキトー教師このテーブルのポイントは、「単純・反復的なタスク → ローカル」「複雑・高精度が必要 → クラウド」という切り分けですね。ローカルLLMはフロンティアモデルに匹敵する精度ではないけれど、単純作業には十分実用的です。
室谷でも本当に面白いのは、ローカルLLMの精度がどんどん上がってきてること・・・DeepSeek-R1やQwen3クラスのモデルが7Bサイズでも動くようになってきてるので、1年前と比べると実用範囲がかなり広がっています。
テキトー教師そうなんですよね。実はそうなんですよw。
受講生さんに最初にローカルLLMを触ってもらった時、「思ったより使えるじゃないですか」って反応がほとんどで。2年前のイメージを持ったまま「精度が低い」と思い込んでる人が多い。
受講生さんに最初にローカルLLMを触ってもらった時、「思ったより使えるじゃないですか」って反応がほとんどで。2年前のイメージを持ったまま「精度が低い」と思い込んでる人が多い。
ハードウェア要件と推奨スペック
室谷ローカルLLMで一番ネックになるのがハードウェアですね。スペックによって使えるモデルサイズが全然違います。
テキトー教師実用的なスペックの目安をまとめるとこうなります。
| 環境 | 使えるモデルサイズ | 速度感 |
|---|---|---|
| M1/M2/M3 Mac(16GB) | 7B〜13B | 実用的(20〜40 tokens/sec) |
| M1/M2/M3 Mac(32GB) | 13B〜30B | 快適 |
| M3 Max / M4 Max(64GB+) | 30B〜70B | クラウド並みに速い |
| NVIDIA RTX 4070(12GB VRAM) | 7B〜13B | GPU加速で高速 |
| NVIDIA RTX 4090(24GB VRAM) | 30B〜 | 非常に高速 |
| CPU only(Intel Mac / 古いPC) | 7B以下 | 遅い(要忍耐) |
室谷最近のM4系Macって、GPUとしての性能もすごく上がってきてて・・・VRAM問題がなくて統合メモリで大きなモデルを動かせるのは、ローカルLLM用途で本当に強いですね。
テキトー教師個人開発者の視点だと、新しいMac Miniの24GBモデルがコスパ最強って言われてますよね。10万円以下で30Bクラスのモデルが動く環境が手に入りますから。
室谷そう、MacとOllamaの組み合わせってめちゃくちゃ使いやすいんですよ。NVIDIA GPUのドライバ問題を気にしなくていいし、設定も本当にシンプルで。
よくある質問(FAQ)
テキトー教師受講生さんからよく来る質問をまとめておきますね。
Q. Cursorのタブ補完もローカルLLMに変更できますか?
テキトー教師これは現時点ではできません。タブ補完(Tab Completion)はCursorのプロプライエタリな機能で、Cursorのクラウドサーバーと連携して動いています。
Chat機能のみローカルLLMに変更できます。
Chat機能のみローカルLLMに変更できます。
室谷ここを誤解してる人が多いですね・・・「ローカルLLMに切り替えたら完全に無料になる」というわけじゃないので、期待値の調整が必要です。
Q. Ollamaで複数のモデルを切り替えて使えますか?
室谷できます。Ollamaは複数のモデルを事前にpullしておけば、
Cursorのカスタムモデル設定も複数追加できるので、用途によって切り替えが可能です。
ollama run {モデル名} で切り替えられます。Cursorのカスタムモデル設定も複数追加できるので、用途によって切り替えが可能です。
テキトー教師実際の運用だと「軽いタスクはcodellama:7b、複雑なタスクはqwen2.5-coder:14b」のように使い分けている人が多いですよ。
Q. チームで共有できますか?
テキトー教師できます。OllamaをDockerで動かして、チームが共有できるサーバーとして運用する方法があります。
ネットワーク内のPCから
ネットワーク内のPCから
http://{サーバーIP}:11434/v1 でアクセスする形です。室谷ただしこれはGPUサーバーを1台用意するコストが必要になります。小規模チームなら1台のハイエンドGPUマシンを共有する形が現実的ですね。
個々の開発者PCにGPUを積むより、初期投資を抑えられます。
個々の開発者PCにGPUを積むより、初期投資を抑えられます。
Q. プライバシー的に本当に安全ですか?
室谷Ollamaは完全にローカルで動くので、コードがOllamaのサーバーに送られることはありません。ただしCursorの設定によっては、Cursor自体のサービスとの通信は残ります。
テキトー教師企業で使う場合は、IT部門やセキュリティチームと連携して、Cursor自体の通信設定(Privacy Mode等)も確認することをおすすめします。
Q. cursor ローカル llm ollama の設定でコードが返ってこない場合は?
室谷まずOllamaサーバーが起動しているか確認です。
次にCursorの設定でBase URLが正しく入力されているか確認してください。
http://localhost:11434 にブラウザでアクセスして「Ollama is running」と出ればサーバーはOK。次にCursorの設定でBase URLが正しく入力されているか確認してください。
テキトー教師それでも動かない場合はターミナルで直接APIテストしてみましょう。
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5-coder:7b",
"messages": [{"role": "user", "content": "Hello"}],
"stream": false
}'
これでレスポンスが返ってくれば、OllamaのAPIは正常に動いています。
まとめ:CursorとローカルLLMの賢い使い方
室谷今回の内容をまとめましょう。CursorでローカルLLMを使うメリットは「コスト削減」「プライバシー保護」「オフライン利用」の3つ。
設定方法はOllamaかLM Studioを使ってOpenAI互換エンドポイントをCursorに設定するだけです。
設定方法はOllamaかLM Studioを使ってOpenAI互換エンドポイントをCursorに設定するだけです。
テキトー教師ポイントをまとめるとこうなります。
- Ollama(https://ollama.com)が最も手軽。`curl -fsSL https://ollama.com/install.sh | sh` でインストール
- CursorのBase URLを
http://localhost:11434/v1に設定、API Keyにollamaと入力 - コーディング向けモデルはqwen2.5-coder、codellama、deepseek-coderがおすすめ
- Apple Silicon Mac(16GB以上) なら7B〜13Bモデルが実用的に動く
- 完全移行ではなくハイブリッド運用が現実的。単純作業 → ローカル、複雑作業 → クラウド
室谷2026年の今、ローカルLLMの精度は2年前と全然違います。「試してみたけど使えなかった」という経験がある方も、最新モデルでもう一度試してみる価値は十分ありますよ。
テキトー教師.AI(ドットエーアイ)コミュニティでもローカルLLM活用の事例が増えていますし、設定でつまずいた場合はコミュニティで聞いてみるのもいい方法だと思います。まずOllamaをインストールして、一個モデルを動かしてみるところから始めてみてください。
室谷最初の一歩は本当に30分もあれば踏み出せます。コスト削減とプライバシー保護を両立できるローカルLLM環境、ぜひ試してみてください。









