
ChatGPTをローカルで動かす完全ガイド【2026年最新】:Ollama・Open WebUI・必要スペックまで徹底解説
 室谷
室谷今回はChatGPTをローカルで動かす話をしましょう。これ、.AI(ドットエーアイ)コミュニティでも定期的に盛り上がるテーマなんですよね。
「ChatGPTをローカルで使いたい」「オフラインで動かしたい」って声が本当に多くて・・・
「ChatGPTをローカルで使いたい」「オフラインで動かしたい」って声が本当に多くて・・・
 テキトー教師
テキトー教師ですよね。講座でも「なぜローカルで動かしたいのか?」から整理することが多いんですけど、大きく3パターンあるんですよ。
プライバシーを守りたい人、コストを下げたい人、そしてカスタマイズしたい人です。目的によって最適な方法が変わってくるんですよね。
プライバシーを守りたい人、コストを下げたい人、そしてカスタマイズしたい人です。目的によって最適な方法が変わってくるんですよね。
室谷正直、「ChatGPTをローカルで動かす」という表現自体がちょっと誤解を招くんですよね。ChatGPTそのものはOpenAIのクラウド上にあって、それをローカルで動かすことは技術的にできないんですよ。
でも本当に面白いのは、ChatGPTと同等、もしくは特定のタスクでそれ以上の性能を持つオープンソースモデルをローカルで動かせるようになってきたってこと。
でも本当に面白いのは、ChatGPTと同等、もしくは特定のタスクでそれ以上の性能を持つオープンソースモデルをローカルで動かせるようになってきたってこと。
テキトー教師そこが本質ですよね。Ollama + オープンソースモデルの組み合わせで、感覚的にはChatGPTに近い体験が手元のPCで完結する。
コミュニティのメンバーさんも最初は「え、ほんとに動くの?」って半信半疑で試してみて、「思ってたより全然使える!」ってなる人が多いです。
コミュニティのメンバーさんも最初は「え、ほんとに動くの?」って半信半疑で試してみて、「思ってたより全然使える!」ってなる人が多いです。
室谷MYUUUのエンジニアチームも社内の一部処理はローカルLLMでやってますね。特に機密情報を扱う処理は、クラウドに飛ばしたくないじゃないですか。
そういうケースでローカル実行が効いてくる。
そういうケースでローカル実行が効いてくる。
テキトー教師企業のユースケースだと確かにそれが一番大きいですよね。コンプライアンス的に外部APIに情報を出せないケースって、医療・法務・金融あたりで山ほどあります。
ローカルLLMはそういうところの需要が着実に伸びてます。
ローカルLLMはそういうところの需要が着実に伸びてます。
室谷ということで今回は、2026年時点で一番スタンダードな方法であるOllamaを使ったローカル環境構築を、実際の手順と合わせて掘り下げていきましょう。必要なスペックから、使えるモデル、Open WebUIでChatGPTライクなUIを作る方法まで全部やります。
そもそもChatGPTをローカルで動かすとはどういうことか
室谷まず整理しておくと、「ChatGPT ローカル」と検索してる人の大半が求めているのは、「インターネットなし・外部サーバーへのデータ送信なし・無料」でAIチャットを使いたいということなんですよね。
テキトー教師正確に言うと、「ChatGPT」という製品をローカルで使うことはできない。ChatGPTはOpenAIのサービスであって、そのモデルの重みは公開されていない。
でも、「ChatGPTと同じような体験ができるAIチャット環境」はローカルに構築できる、ということですよね。
でも、「ChatGPTと同じような体験ができるAIチャット環境」はローカルに構築できる、ということですよね。
室谷そういうことです。代替となるのはオープンソースのLLMで、MetaのLlama、DeepSeek、Gemma(Google)、Mistralあたりが主要どころです。
これらはモデルの重みが公開されていて、手元で実行できる。
これらはモデルの重みが公開されていて、手元で実行できる。
テキトー教師特にDeepSeekが登場してから、「これクラウドのChatGPTにかなり近い精度じゃないか」ってなったのがローカルLLM熱が盛り上がった一因だと思いますよ。コスト効率が高い分、軽量でローカル向けのモデルも充実してきた。
室谷DeepSeekの衝撃は大きかったですね。中国発の非常に高性能なモデルが出てきて、しかもオープンソースで公開されて・・・モデルレイヤーの競争がバチバチになってるじゃないですか、あの流れで「手元で動かせるモデルが使えるようになってきた」という認知が一気に広がった感じがします。
テキトー教師ローカルLLMとクラウドLLMの違いを整理すると、こうなります。
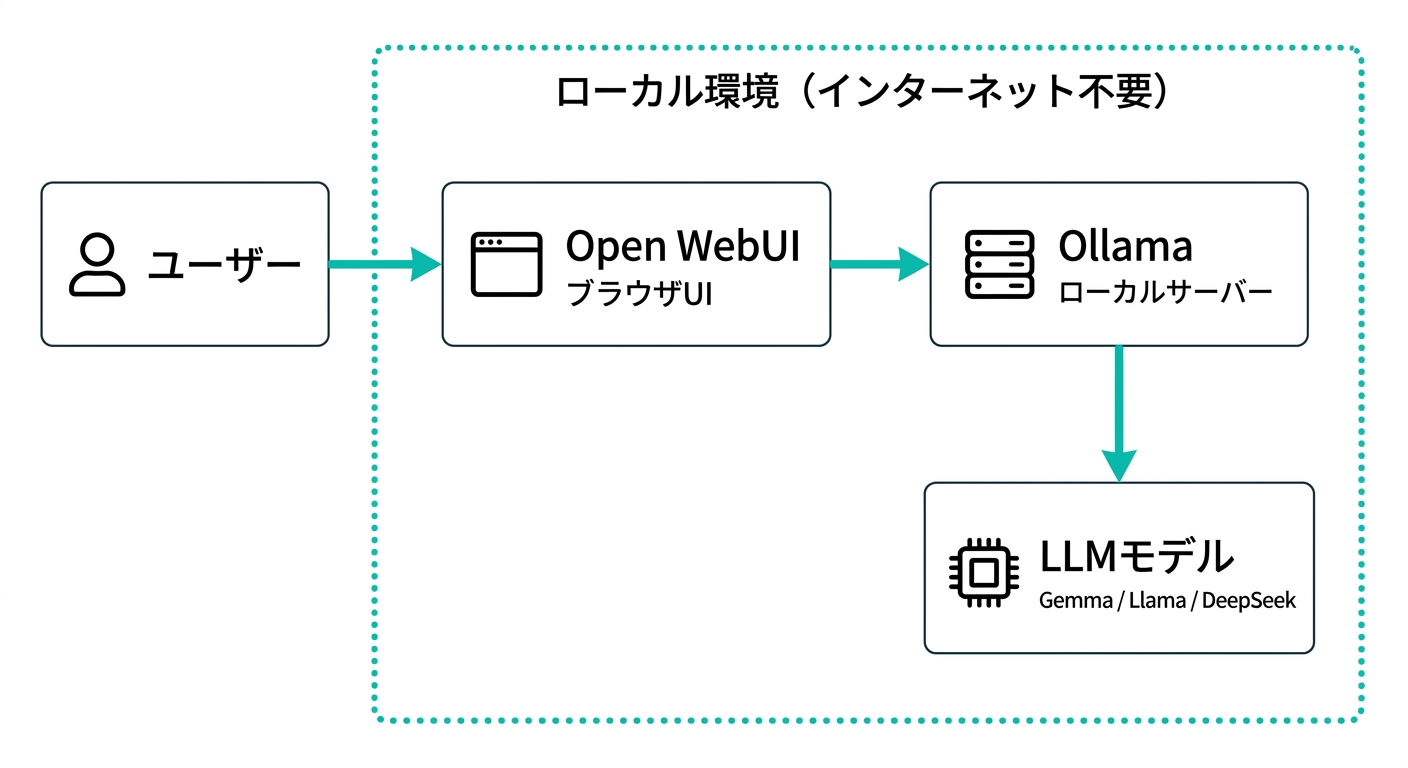
| 項目 | クラウドLLM(ChatGPT等) | ローカルLLM(Ollama等) |
|---|---|---|
| データのプライバシー | 外部サーバーに送信される | 完全にローカルで完結 |
| コスト | 月額/従量課金が発生 | ハードウェア代のみ |
| インターネット | 必要 | 不要(オフライン可) |
| モデルの性能 | 最高性能のモデルが使える | ハードウェアに依存 |
| セットアップ | ほぼ不要 | 環境構築が必要 |
| カスタマイズ | 制限あり | 自由度が高い |
| 最新情報 | リアルタイム更新 | 手動でモデル更新 |
室谷この表を見てわかるように、ローカルLLMはメリットとデメリットがはっきりしてるんですよね。プライバシー・コスト・オフライン対応はローカルが圧倒的に有利。
でも性能と手軽さはクラウドに軍配が上がる。
でも性能と手軽さはクラウドに軍配が上がる。
テキトー教師講座のコミュニティのメンバーさんに「どちらがいいか」と聞かれたら、「用途次第」と答えるしかないですよね。多くのケースはクラウドで十分で、特定の理由がある人だけローカルを使う、という棲み分けが実際のところだと思います。
ローカルで動かす前に確認!必要なスペックとGPU
室谷ここが一番大事なポイントで、手元のマシンがローカルLLMを動かせるスペックかどうかを先にチェックしておかないと、インストールしてもまともに動かないんですよね。
テキトー教師コミュニティのメンバーさんがよくハマるのがここです。「動かしてみたけど全然レスポンスが遅い」「1分待っても返ってこない」ってなる原因の9割がスペック不足です。
室谷Ollamaのドキュメント()を確認すると、GPUについてはNVIDIA(Compute Capability 5.0以上)、AMD Radeon(ROCm対応)、Apple Silicon(Metal API)がサポートされています。GPUがない場合はCPUでも動くんですが、体験が大きく変わります。
テキトー教師モデルのサイズとRAM・VRAMの関係を整理すると、こうなります。
| モデルサイズ | 必要VRAM/RAM目安 | 代表的なモデル | 体感速度(GPU使用時) |
|---|---|---|---|
| 1B〜3B | 2〜4GB | Llama 3.2 3B、Gemma 3 1B | 速い |
| 7B〜8B | 6〜8GB | Llama 3.1 8B、Gemma 3 4B | 普通 |
| 13B〜14B | 10〜16GB | Qwen 2.5 14B | やや遅い |
| 32B | 24GB+ | DeepSeek R1 32B | 遅い |
| 70B+ | 48GB+ | Llama 3.1 70B | 非常に遅い |
室谷つまり一般的なゲーミングPCやMacBook Pro(Apple Silicon)であれば、8BクラスのモデルはGPUが十分なので実用的に動く。それ以上は専用GPUがないとキツいですね。
テキトー教師実際の体感の話をすると、M3 MacBook ProでLlama 3.1 8Bを動かしたとき、1秒あたり40〜50トークンくらい生成できるんですよ。これ、読むより速いスピードなので快適に使えます。
室谷Appleシリコン(M系チップ)はローカルLLMに向いてますよね。統合メモリなのでVRAMとRAMを区別せず大きな領域が使えて、8Bモデルなら16GBのRAMのMacでも問題なく動く。
MYUUUのメンバーに聞くとM3やM4 ProのMacを使っている人が多くて、そのまま使えてる人がほとんどです。
MYUUUのメンバーに聞くとM3やM4 ProのMacを使っている人が多くて、そのまま使えてる人がほとんどです。
テキトー教師Windowsユーザーの場合は、GeForce RTX 3060(VRAM 12GB)以上あれば7B〜8Bクラスのモデルは快適に動きます。RTX 4070以上なら14Bクラスも視野に入ってくる。
Ollamaは起動時に自動でGPUを検出して、使えるGPUがあれば優先的に使うので、設定は基本不要です。
Ollamaは起動時に自動でGPUを検出して、使えるGPUがあれば優先的に使うので、設定は基本不要です。
GPUなしCPUのみでも動くか?
室谷よく聞かれるんですけど、CPUのみでも動くんですよ。ただ、7B以上のモデルをCPUだけで動かすと、1トークン生成するのに数秒かかることもあって、実用的な体験にはならない。
テキトー教師1B〜3Bの小さいモデルであれば、CPUのみでも1秒あたり10〜20トークンくらい出るので、ライトな用途なら使えなくはないですね。ただ、精度はやはり小さいモデルなりの限界があります。
室谷結論としては、8B以上のモデルをきちんと動かしたいならGPUかApple SiliconのMacが必要。それがない環境なら、まずクラウドAPIを使う方が現実的です。
スペックを確認してからインストールに進みましょう。
スペックを確認してからインストールに進みましょう。
OllamaでChatGPTライクな環境を構築する手順
室谷では実際のインストール手順に入りましょう。Ollamaは2026年時点でGitHubスター数16万を超えている、ローカルLLM実行ツールのデファクトスタンダードですね。
テキトー教師シンプルさが秀逸で、コマンド一発でモデルをダウンロードして実行できる。Dockerが不要で、初心者でもとっつきやすい。
これが爆発的に広まった理由だと思います。
これが爆発的に広まった理由だと思います。
macOSへのインストール
室谷macOSの場合はからGUI版をダウンロードするのが一番簡単です。
# または Homebrew 経由でインストール
brew install ollama
GUIアプリをダウンロードした場合は、メニューバーにアイコンが出て、バックグラウンドでサーバーが起動します。インストール後は特に設定しなくてもすぐ使えますよ。
LinuxとWindowsへのインストール
室谷Linuxはターミナルで一発です。
curl -fsSL https://ollama.com/install.sh | sh
Windowsは公式サイトから.exeインストーラーをダウンロードして実行するだけです。インストール後にターミナル(PowerShell or コマンドプロンプト)からollamaコマンドが使えるようになります。
# Windowsの場合はPowerShellでインストール
irm https://ollama.com/install.ps1 | iex
モデルを実行してみる
室谷インストールが完了したら、まず試してほしいのはこのコマンドです。
# Gemma 3 4Bモデルを起動(初回はダウンロードが走る)
ollama run gemma3
# または Llama 3.1 8B
ollama run llama3.1
初回はモデルのダウンロードが走るので、しばらく待つ必要があります。Llama 3.1 8Bだと約4.7GBのダウンロードが発生します。
Wi-Fi環境で5〜10分くらい見ておくといいです。
Wi-Fi環境で5〜10分くらい見ておくといいです。
室谷ダウンロードが終わると対話モードになって、そのまま質問を入力できます。これだけでローカルLLMが動く。
テキトー教師終了するときは
/bye と入力するかCtrl+Dです。一度ダウンロードしたモデルはローカルに保存されるので、2回目以降は即座に起動できます。使えるモデルの選び方
室谷Ollamaで使えるモデルはに一覧があります。2026年時点で人気上位はこんな感じです。
| モデル | コマンド | サイズ | 用途 |
|---|---|---|---|
| Gemma 3 | ollama run gemma3 | 4B〜27B | 汎用、日本語も良好 |
| Llama 3.1 | ollama run llama3.1 | 8B〜70B | 汎用、バランス型 |
| DeepSeek R1 | ollama run deepseek-r1 | 1.5B〜671B | 推論・コーディング |
| Qwen 2.5 | ollama run qwen2.5 | 0.5B〜72B | 多言語、日本語対応 |
| Mistral | ollama run mistral | 7B | 軽量・高速 |
テキトー教師日本語を重視する場合はGemmaかQwen 2.5が良いですね。Qwen 2.5は多言語モデルで日本語の品質が高い。
英語中心のタスクであればLlama 3.1も十分使えます。
英語中心のタスクであればLlama 3.1も十分使えます。
室谷コーディングや論理的な推論を重視するならDeepSeek R1系が面白いですね。ただし7B以上のサイズはそれなりのスペックが必要です。
目的に合ったモデルを選ぶのが重要で、何でも一番大きいモデルが良いわけじゃない。
目的に合ったモデルを選ぶのが重要で、何でも一番大きいモデルが良いわけじゃない。
ChatGPTのAPIとしてローカルモデルを使う
テキトー教師これが実はかなり使えるテクニックで、Ollamaは起動するとlocalhost:11434でOpenAI互換のAPIを提供するんですよ。
室谷OpenAI互換APIということは、ChatGPTのAPIを使う前提で作られたツールやコードが、エンドポイントを差し替えるだけでローカルモデルに向けられるんですよね。これはマジで便利です。
# OllamaのAPIをOpenAI互換で呼び出す例
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.1",
"messages": [
{"role": "user", "content": "日本の首都はどこですか?"}
]
}'
これを使うと、たとえばDifyのLLMノードをローカルのOllamaに向けることもできますし、VSCodeの拡張機能やContinueみたいなコーディングアシスタントをローカルモデルで動かすことも普通にできます。
室谷ローカルLLMをMCPと組み合わせる使い方も増えてきてますよね。OllamaがOpenAI互換APIを出してるので、MCPサーバーとの連携も設定次第でできます。
Open WebUIでChatGPTそっくりのUIを作る
室谷Ollamaだけだとターミナルで使う感じになるんですけど、ビジュアルなUIが欲しい場合はOpen WebUIが最高です。ChatGPTのUIとほぼ同じ見た目で、ブラウザからローカルモデルを使えます。
テキトー教師Open WebUIは完全にオフラインで動いて、自分のPCの中だけで完結する。DockerがあればコマンドひとつでChatGPTそっくりの環境が立ち上がりますよ。
# DockerでOpen WebUIを起動する
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
このコマンドを実行したら、
http://localhost:3000にアクセスするとChatGPTライクなUIが立ち上がります。左サイドバーに会話履歴、右にチャット画面、モデルの切り替えもメニューからできる。テキトー教師DockerがインストールされていないMacの場合は、公式サイト()にpipでのインストール方法もあります。
# pip経由でインストール
pip install open-webui
# 起動
open-webui serve
Open WebUIは機能も豊富で、会話履歴の管理、プロンプトのプリセット保存、ファイルアップロードとRAG(Retrieval-Augmented Generation)との連携まで対応してます。ChatGPTの有料プランと比較してもかなり使いやすい。
テキトー教師特に「ファイルにアクセスする」というニーズがある場合に、Open WebUIのRAG機能が役立ちます。ローカルのドキュメント・PDF・テキストファイルをアップロードして、モデルがそれを参照しながら回答してくれる。
機密情報を含むドキュメントを扱う場合は、これが外部サービスとの大きな違いになります。
機密情報を含むドキュメントを扱う場合は、これが外部サービスとの大きな違いになります。
室谷社内文書を安全にAIに読ませたい、でも外部に出したくない、という場合は、Open WebUI + Ollamaのローカル構成がそれに応えるソリューションになります。
ローカルLLMを使ったプロンプト・指示の工夫
室谷ローカルモデルとクラウドモデルのもう一つの違いが、プロンプトへの反応の仕方なんですよね。ChatGPTはOpenAIが細かく調整してあるので、ざっくりした指示でもそれなりに返してくれる。
でもローカルモデルは丁寧な指示が必要なケースが多い。
でもローカルモデルは丁寧な指示が必要なケースが多い。
テキトー教師そこは確かに差がありますよね。ローカルモデルは基本的にベースモデルか、軽くファインチューニングされたものなので、より明示的な指示が求められます。
プロンプトの書き方次第で結果が大きく変わります。
プロンプトの書き方次第で結果が大きく変わります。
室谷たとえば日本語で出力させたい場合は、「必ず日本語で答えてください」と明示しないと英語で返ってくることがある。このあたり、ChatGPTだと自動的に合わせてくれますが、ローカルモデルでは明確な指示が必要なことが多い。
テキトー教師プロンプトのコツを整理するとこんな感じです。
- 言語の明示: 「日本語で回答してください」を最初に書く
- 役割の設定: 「あなたは○○の専門家です」というシステムプロンプトが効く
- 出力形式の指定: 「箇条書きで5点にまとめてください」など具体的に
- 文脈の提供: 前提情報や背景をしっかり書く
- 段階的な指示: 複雑なタスクは小さく分割して指示する
室谷Ollamaでシステムプロンプトを設定するには、Modelfileという設定ファイルを使います。ChatGPTで言う「カスタム指示」のローカル版です。
# Modelfileを作成してカスタムモデルを定義
# FROM: ベースモデルを指定
# SYSTEM: システムプロンプトを設定
ollama create myassistant -f Modelfile
ollama run myassistant
これを使うと、毎回「日本語で答えて」と書かなくていい専用モデルが作れます。業務用途であれば、ここに会社の業種やよく使う資料のフォーマットを入れておくと、よりコンテキストに合った回答が返ってきますよ。
ローカルで英語の文献を翻訳・要約する
室谷英語の論文や技術文書をローカルで翻訳・要約するケースが多いですよね。外部に出したくない機密性の高い文書を、ローカルで日本語に変換したい、というニーズです。
テキトー教師翻訳の品質は正直、ChatGPTに比べると一段落ちる場合があります。ただQwen 2.5の72Bクラスだと、かなり良い翻訳ができる。
スペックがあるなら大きいモデルを使うのが吉ですね。
スペックがあるなら大きいモデルを使うのが吉ですね。
室谷学術論文の翻訳は特にデリケートで、専門用語の訳し方がモデルによって全然違う。Systemプロンプトで「専門用語は英語のままにしてください」とか「学術的な文体で訳してください」と指定するのが重要です。
ChatGPT ローカル 構築:Windows環境の詳細手順
テキトー教師WindowsでのChatGPTライクなローカル環境構築についても話しておきましょう。Windows環境はmacOSよりもステップが多いので、詰まりやすい人が多いです。
室谷Windowsでのローカル環境構築はこの流れです。
- Ollamaのインストール: 公式サイト(ollama.com/download)から.exeをダウンロードして実行
- モデルのダウンロード: PowerShellかコマンドプロンプトで
ollama run gemma3等を実行 - Open WebUIのインストール: Dockerを使うか、pipで入れる
- ブラウザからアクセス:
http://localhost:3000で使い始める
テキトー教師Windows環境でよく引っかかるのがファイアウォールの設定です。Ollamaのサーバー(ポート11434)がWindows Defenderにブロックされることがある。
「Windowsセキュリティ」→「ファイアウォールとネットワーク保護」→「アプリにファイアウォール経由のアクセスを許可する」からollamaを許可しておくと解決することが多いです。
「Windowsセキュリティ」→「ファイアウォールとネットワーク保護」→「アプリにファイアウォール経由のアクセスを許可する」からollamaを許可しておくと解決することが多いです。
室谷GPU設定の話をすると、NVIDIAのGPUを使っている場合は、事前にNVIDIA GPU DriverとCUDAをインストールしておく必要があります。Ollamaが自動検出してくれますが、ドライバーが古いと認識されないことがあります。
ドライバーは最新版に更新してからOllamaを入れるのがおすすめです。
ドライバーは最新版に更新してからOllamaを入れるのがおすすめです。
テキトー教師「なんかCPUで動いてる気がする」という場合は
ollama ps コマンドでプロセッサーの使用状況を確認してみてください。# モデルの実行状態を確認
ollama ps
# 出力例:
# NAME ID SIZE PROCESSOR UNTIL
# gemma3:4b abc123 3.8GB 100% GPU 4 minutes from now
PROCESSORの欄が「100% CPU」になっていたらGPUが使われていない状態です。「100% GPU」になっていればGPU加速が効いている状態で、体感速度が全然違います。
ローカルLLMの環境でできること・できないこと
室谷ローカルLLMを使い込んでいくと、「これはできるの?できないの?」という疑問が出てきますよね。整理してみましょう。
テキトー教師ローカルLLMでできることから言うと、
- テキスト生成・要約・翻訳
- コード生成・デバッグ
- ドキュメントの質疑応答(RAG構成)
- プロンプトの実験・比較検証
- オフライン・エアギャップ環境での利用
- 大量バッチ処理(API経由)
あたりは普通にできます。ChatGPTとほぼ同等のユースケースがカバーできます。
室谷逆にできないこと・苦手なことというと、リアルタイムのウェブ検索は基本的にできない(ツール連携すれば別ですが)。最新情報へのアクセスがない、マルチモーダル(画像理解)は対応モデルが限られる、といったあたりです。
テキトー教師あと正直な話をすると、最新のGPT-4oやClaude Sonnetと比べると、複雑な推論や創作の品質には差があります。日常的な業務用途ではローカルで全然いける、でもフロンティアレベルの性能が必要なタスクはクラウドを使う、という使い分けが現実的ですよね。
室谷企業での使い方として多いパターンが「クラウドとローカルのハイブリッド」です。機密度の低い・ルーティン的なタスクはローカルで処理してコストを下げつつ、複雑・重要なタスクはクラウドのAPIを使う。
MYUUUのチームでも似たような構成になってます。
MYUUUのチームでも似たような構成になってます。
ローカルLLMのプライバシーとデータ学習の誤解
テキトー教師ローカルLLMを使う最大の理由の一つであるプライバシーについて、もう少し詳しく話しておきましょう。
室谷ローカルで動かす場合、テキストが外部に送信されない。これは間違いないです。
Ollamaはインターネット接続なしで動かせますし、モデルダウンロード時以外は通信が発生しません。
Ollamaはインターネット接続なしで動かせますし、モデルダウンロード時以外は通信が発生しません。
テキトー教師企業でローカルLLMを採用する理由として、「入力した情報がモデルの学習に使われる心配がない」という点も大きいです。クラウドサービスによってはオプトアウトしない限り入力データが学習データに使われる可能性があるので、機密情報を扱う場面では気になるポイントです。
室谷ただし注意点があって、ローカルで学習させる(Fine-tuning)のは別の話です。Ollamaでモデルを「ローカルで動かす」ことと、「ローカルのデータで再学習させる」ことは全くの別物。
Ollamaで手軽にできるのは前者だけで、後者は別のツールと大きなGPUリソースが必要です。
Ollamaで手軽にできるのは前者だけで、後者は別のツールと大きなGPUリソースが必要です。
テキトー教師「ローカルで動かしたモデルに自社データを学習させたい」という場合は、Fine-tuningかRAGという別のアプローチが必要になります。この点を誤解している人がかなり多いので、きちんと整理しておくことが大事です。
よくある質問(FAQ)
Q1: ChatGPTをオフラインで使いたい場合、Ollamaが最善の選択肢ですか?
室谷2026年時点では、Ollamaが最も手軽でスタンダードな選択肢ですね。インストールが簡単で、Windowsでも使えて、モデルライブラリも充実している。
テキトー教師他の選択肢としてはLM Studio(GUIが使いやすい)やllama.cpp(軽量で高速)などもあります。でも初めてローカルLLMを試すならOllamaから入るのが一番失敗が少ないです。
Q2: 無料でChatGPTに近い体験ができるというのは本当ですか?
室谷本当です。ただし前提として、Ollamaとモデルのダウンロード・実行自体は無料ですが、動かすためのPC・GPU環境のコストはかかります。
ランニングコストは実質「電気代のみ」ですが、初期投資(ハードウェア)はゼロではない。
ランニングコストは実質「電気代のみ」ですが、初期投資(ハードウェア)はゼロではない。
テキトー教師手元にM3 MacやGeForce RTX 3060以上のPCがあれば、追加コストなしで始められます。新たにGPUを買うとなると5〜10万円の投資になるので、クラウドAPIのコストと比較して判断する方がいいですよ。
Q3: Windowsでローカル環境を構築する際の最低スペックは?
室谷Ollama自体は非常に軽量なので、スペックの要件はほぼモデル次第です。1B〜3Bの小さいモデルなら8GBのRAMとCPUのみでも動く。
7B〜8Bのモデルを快適に使いたいなら、GPU(VRAM 8GB以上)が必要です。
7B〜8Bのモデルを快適に使いたいなら、GPU(VRAM 8GB以上)が必要です。
テキトー教師とりあえず試してみたいなら、まず
ollama run llama3.2:1b といった1Bクラスのモデルからスタートするといいです。ダウンロードも1GB以下で終わりますし、CPUでも動きます。Q4: ローカルLLMとChatGPT APIはどちらが速いですか?
室谷単純比較するとクラウドAPIの方が速いことが多いです。GPT-4oは1秒あたり100トークン以上出ることも珍しくない。
テキトー教師ただし、インターネット遅延がゼロなのがローカルの強みで、ネットワーク品質に依存しない安定したレスポンスが得られます。社内Wi-Fiが遅い環境や、海外出張先でインターネットが不安定な場面では、ローカルLLMの方が安定して使えるというケースも実際にありますよ。
まとめ:ChatGPTをローカルで動かすために知っておくべきこと
室谷整理しましょう。ChatGPTそのものをローカルで動かすことはできないけど、Ollamaというツールを使えばオープンソースのLLMを手元で実行できる環境が手軽に構築できます。
テキトー教師ポイントをまとめると、
- スペック確認が最重要: 8B以上のモデルにはGPU(VRAM 8GB+)かApple Siliconが必要
- Ollamaが入門ツールとしてベスト: インストールが簡単、macOS・Windows・Linux対応
- UIはOpen WebUI: ブラウザからChatGPTそっくりの体験ができる
- モデル選びはQwen 2.5かGemma 3: 日本語重視ならこの2択
- プライバシーとコストが最大のメリット: データが外部に出ない、ランニングコストは電気代のみ
- クラウドとのハイブリッドが現実解: 全部ローカルにする必要はない
室谷.AI(ドットエーアイ)コミュニティでも「ローカルLLMを使い始めました!」という報告が増えてきていますが、多くの人が「最初のセットアップに1時間かかったけど、一度動いたら快適」って言ってます。スペックさえ合っていれば、それほど難しくない。
テキトー教師講座でも「まず動かしてみる」を大事にしていて、動いた瞬間の体験が次の学習への動機になるんですよね。この記事を読んでローカルLLMを試してみる方が一人でも増えれば嬉しいです。
室谷ローカルで動かす環境ができたら、次はAPIとの連携やDifyとの組み合わせも試してみてください。Ollama + Difyのローカル構成は、かなり強力なAIパイプラインが組めます。
.AIのコミュニティでも活発に情報共有されているテーマなので、ぜひ参加してみてください。
.AIのコミュニティでも活発に情報共有されているテーマなので、ぜひ参加してみてください。









